2张4090微调万亿参数大模型2张4090微调KimiK2
微调超大参数模型,现在的“打开方式”已经大变样了:
仅需2-4 张消费级显卡(4090),就能在本地对DeepSeek 671B乃至Kimi K2 1TB这样的超大模型进行微调了。
你没有看错。
这要放以前啊,各路“炼丹师”是想都不敢这么想的。因为按照传统的方法,类似Kimi K2 1TB参数的模型,用LoRA微调方案理论上需要高达2000GB的显存,而即便是参数量稍小的 DeepSeek-671B的模型微调也需要1400G的显存。
什么概念?
一张H100(80GB)得十几张起步,说是吞矿也是不足为过了。
而现在微调千亿/万亿参数模型的成本能打如此骨折,背后的关键源自两个国产明星项目的联动。
首先就是KTransformers,是由趋境科技和清华KVCache.AI共同开源的项目,GitHub已经斩获15.3K星⭐️。
KTransformer此前在大模型推理领域就已声名鹊起,凭借GPU+CPU的异构推理的创新路径成为主流推理框架之一,通过KTransformers利用单张4090可以推理Kimi K2 1TB级别大模型。
而这一次,KTransformers已经支持LoRA微调,同样是Kimi K2 1TB这样参数的模型,仅90G左右的显存即可;微调参数量稍小的 DeepSeek 671B也仅需70G左右的显存。真·把成本给打下去了。
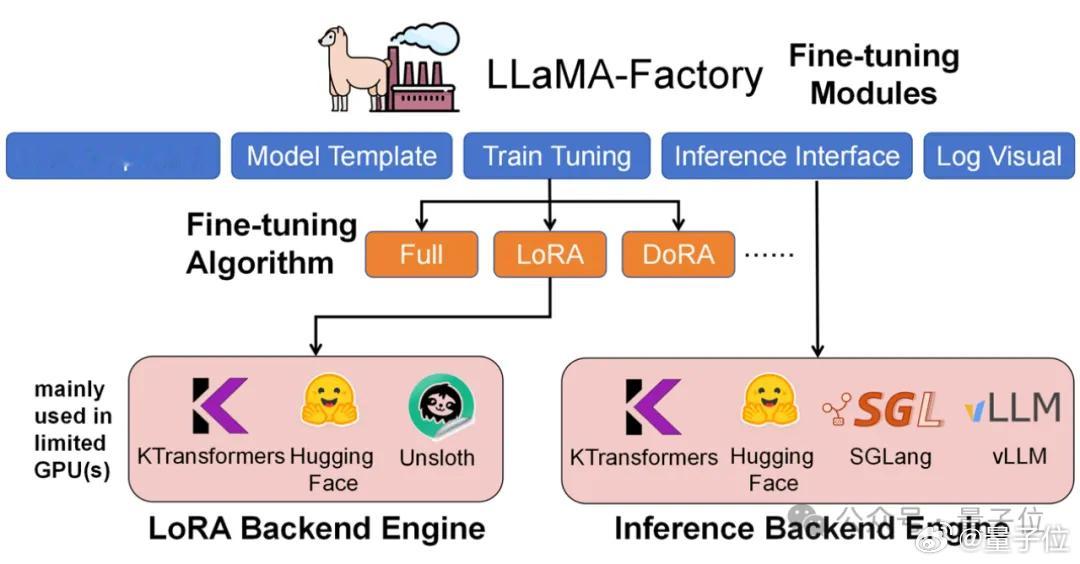
另一个国产明星项目,则是LLaMA-Factory,在GitHub的星标数超6万。它是一个简单易用且高效的大语言模型训练与微调平台,让用户无需编写代码,即可在本地完成上百种预训练模型的微调。
它俩的联动模式是这样的:
LLaMA-Factory是整个微调流程的统一调度与配置框架,负责数据处理、训练调度、LoRA(Low-Rank Adaptation)插入与推理接口管理。
KTransformers则作为其可插拔的高性能后端,在相同的训练配置下接管Attention / MoE等核心算子,实现异构设备的高效协同。
这时候或许有小伙伴要问了,把KTransformers换成其它类似的推理框架不行吗?
答案是,真不行。
例如我们把KTransformers、HuggingFace和Unsloth三种后端的LoRA微调方案放一起比较下效果。
结果显示,KTransformers为超大规模的MoE模型(Kimi K2 1TB等)提供了4090级别的唯一可行方案,并在较小规模的MoE模型(DeepSeek-14B)上面也展现了更高的吞吐和更低的显存占用。
嗯,KTransformers可以说是硬生生把微调超大模型的门槛,从数据中心级拉到了个人工作站级了,而且速度极快。
虽然成本是打下来了,但下一个问题是——效果会不会也打折?