[LG]《Discovering Association Rules in High-Dimensional Small Tabular Data》E Karabulut, D Daza, P Groth, V Degeler [University of Amsterdam & Amsterdam University Medical Center] (2025)
高维小样本表格数据中的关联规则挖掘迎来新突破:
• 关联规则挖掘(ARM)面临高维数据“规则爆炸”和计算瓶颈,传统算法难以高效处理数万列、几十样本的场景,如生物医学基因表达数据。
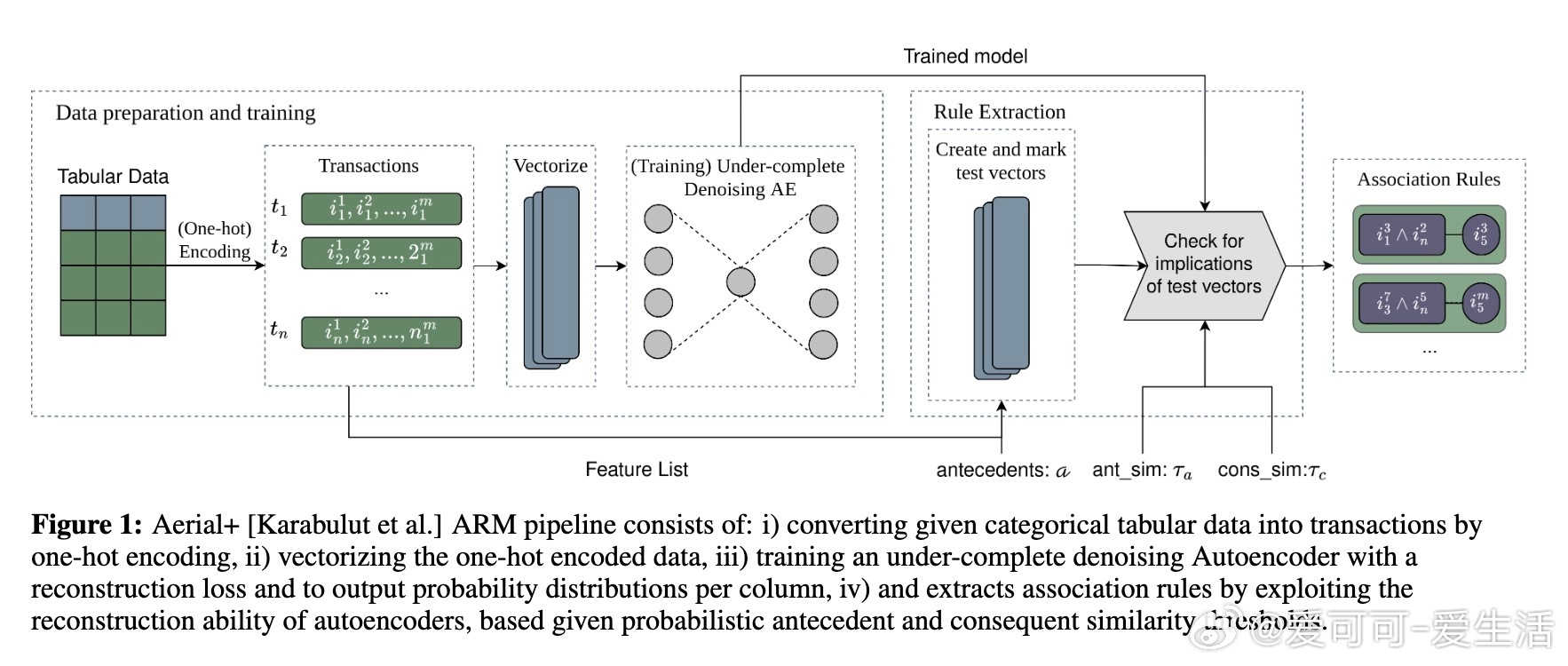
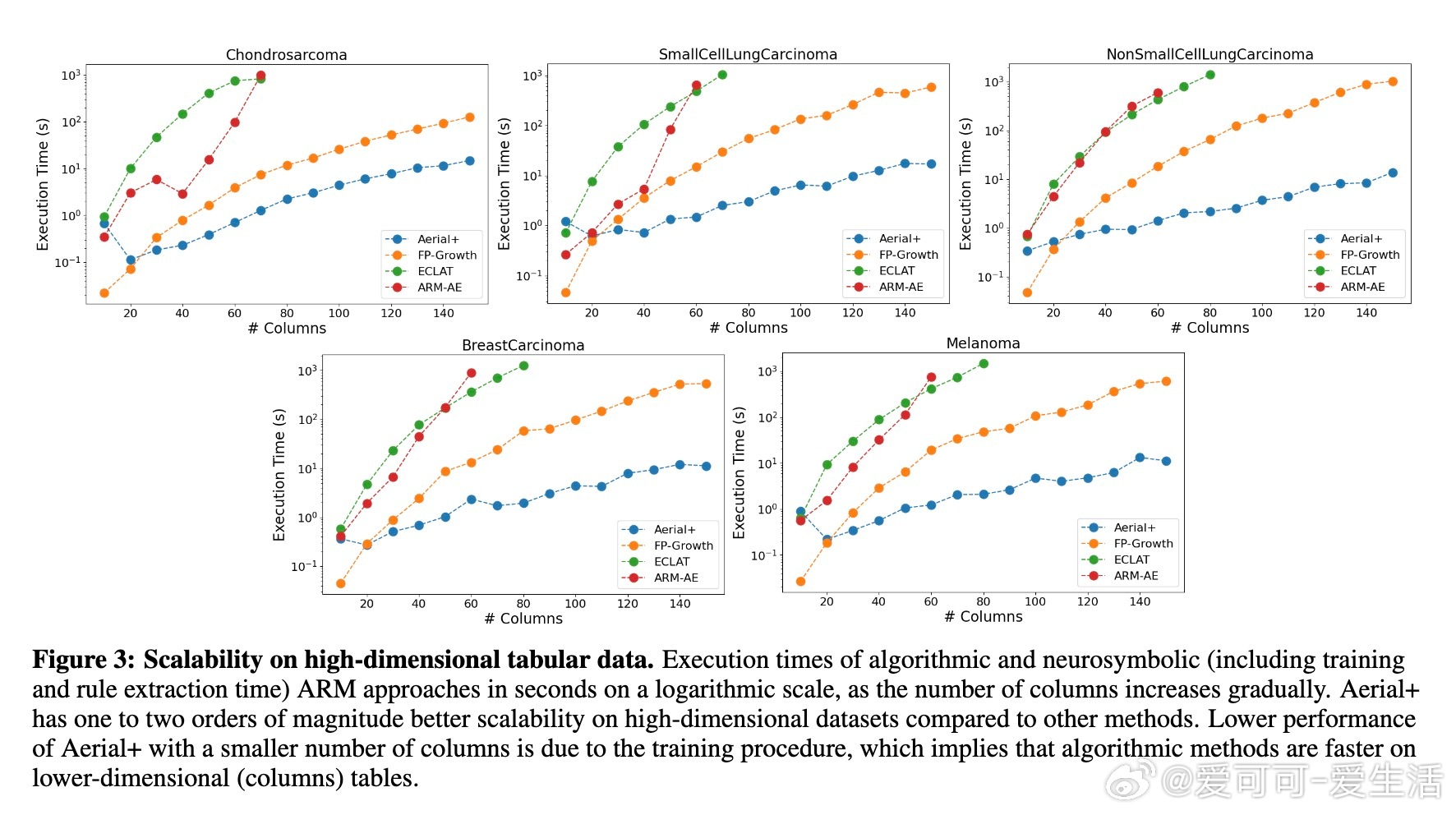
• 神经符号方法Aerial+凭借深度自编码器,结合符号规则提取,实现比FP-Growth、ECLAT等算法快1-2个数量级的运行速度,显著提升高维数据的可扩展性。
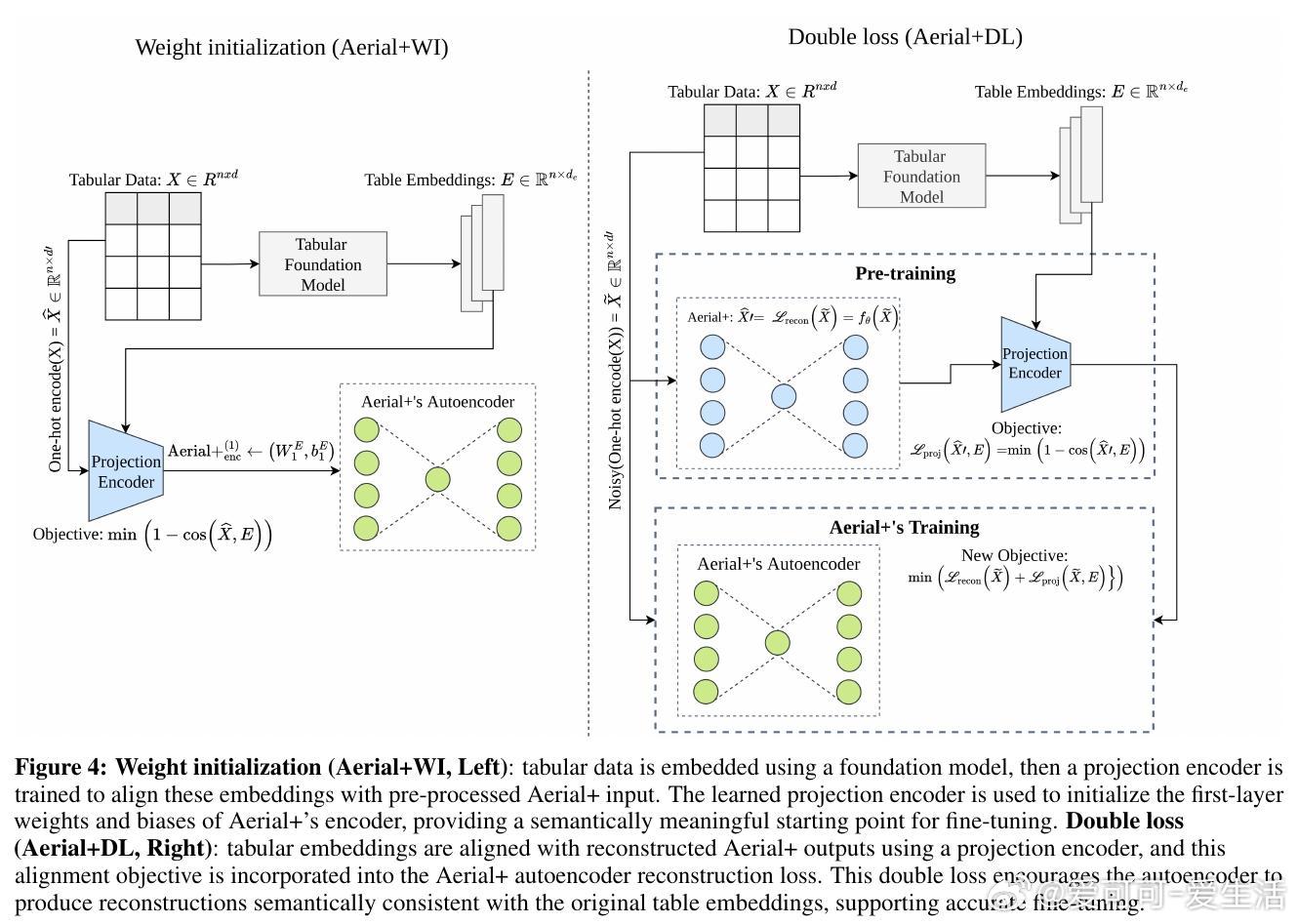
• 低样本量导致神经网络性能下降,Aerial+在小数据 regime 中表现受限。论文创新性提出两种基于TabPFN表格基础模型的微调策略:权重初始化(Aerial+WI)和双重损失训练(Aerial+DL),有效提升规则质量和置信度。
• 细粒度实验覆盖5个真实生物医学数据集(约18K特征,几十样本),验证微调方法提升了规则的统计关联强度和置信度,同时减少冗余规则,计算开销仅微增数秒。
• TabPFN作为唯一公开支持表格嵌入提取的基础模型,为神经符号ARM引入了强语义先验,开启了利用预训练模型引导关联规则提取的新方向。
• 研究指出,未来可结合更多形式的先验知识与多样化基础模型,推动ARM在高维、低样本领域实现更高效和可解释的知识发现。
心得:
1. 神经符号方法突破了传统算法在高维数据的可扩展性瓶颈,利用深度学习提取紧凑表示,显著减少规则数量与计算时间。
2. 低样本限制是神经网络在ARM中的挑战,预训练表格模型的迁移微调策略为解决小样本问题提供了有效路径。
3. 结合符号推理与大规模预训练模型,ARM正迈向一个全新范式,未来可实现更精准且具解释力的规则挖掘,特别是在生命科学等关键领域。
详情🔗arxiv.org/abs/2509.20113
关联规则挖掘神经符号AI高维数据小样本学习表格基础模型生物信息学