《EmbeddingGemma: Powerful and Lightweight Text Representations》
EmbeddingGemma:谷歌推出的轻量级文本嵌入模型,性能媲美数倍参数量的大型模型,适合低延迟、高吞吐量的设备端应用。
• 参数规模仅308M,基于Gemma 3家族的编码器-解码器架构,利用UL2预训练目标强化上下文理解。
• 创新蒸馏训练策略,结合Gemini Embedding教师模型进行嵌入匹配,提升表达能力和鲁棒性。
• 采用“spread-out”正则化,确保嵌入向量充分分布,增强量化后性能和近似最近邻检索效率。
• 训练数据覆盖超2.1万亿tokens,涵盖多语种(250+语言)、多任务(10类型)与多领域,具备卓越泛化能力。
• 模型融合(model souping)技术多样化微调结果,提升模型稳健性和多任务表现。
• 支持128/256/512/768维度嵌入输出,且量化至4-bit权重时性能损失极小,极大降低计算和存储成本。
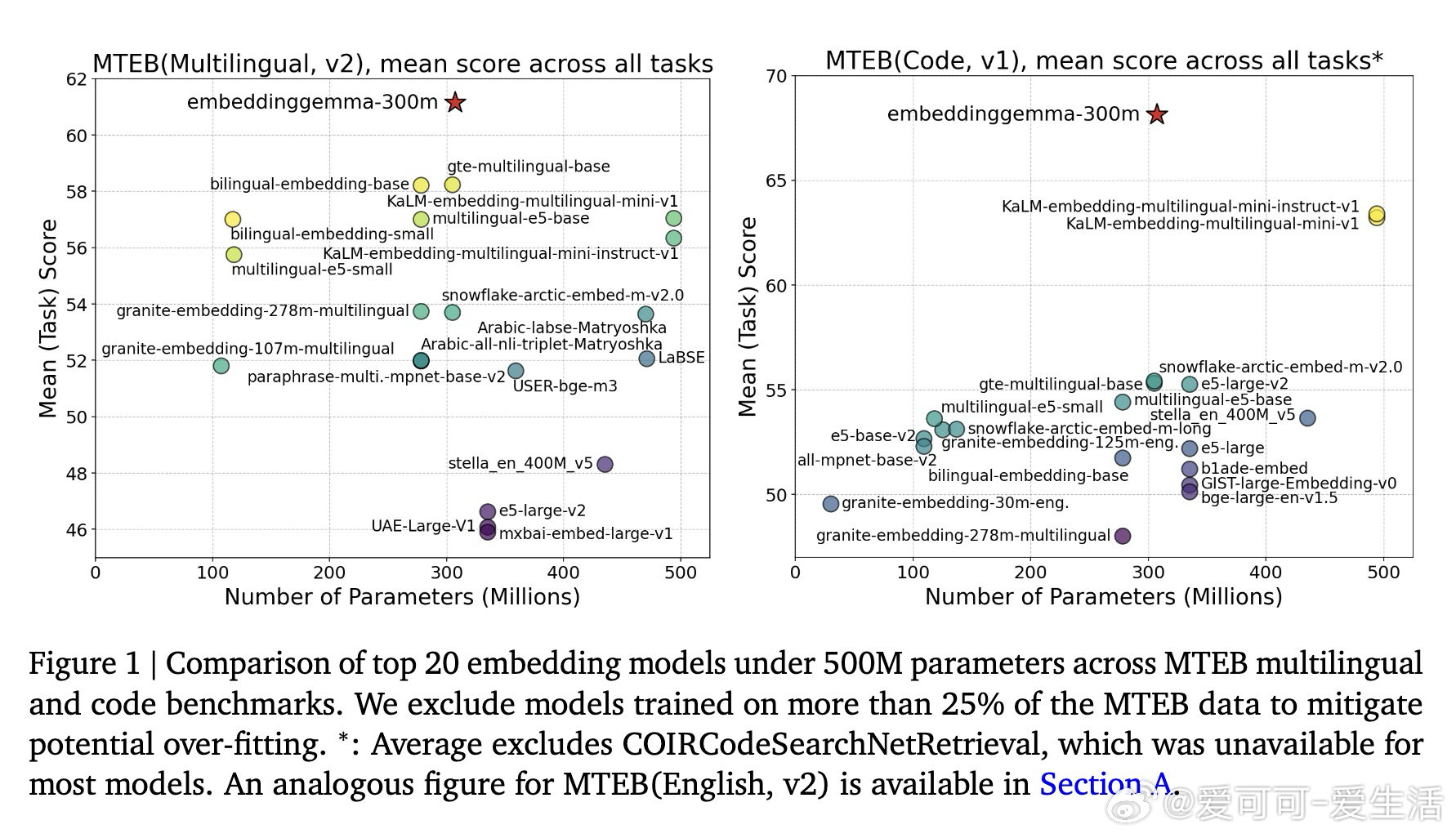
• 在Massive Text Embedding Benchmark (MTEB)多语言、英文及代码任务中,领先所有500M参数以下模型,且性能逼近大型模型。
• 在低资源语言和跨语言检索任务(XTREME-UP、XOR-Retrieve)表现优异,远超多款数十亿参数的模型。
• 适合需要隐私保护、离线运行的场景,如移动设备、边缘计算,满足快速、高效的文本理解需求。
• 开源发布,推动高效通用嵌入模型研究与应用。
心得:
1. 小模型也能通过合理架构与蒸馏技术,达到甚至超越大模型的性能。
2. 编码器-解码器预训练比传统解码器初始化更利于丰富语义表达。
3. 简单的均值池化胜过复杂的注意力池化,反映嵌入任务对稳定性和泛化的特殊需求。
🔗 arxiv.org/abs/2509.20354
了解更多🔗ai.google.dev/gemma/docs/embeddinggemma
自然语言处理 文本嵌入 轻量级模型 多语言 机器学习 模型蒸馏