[CL]《Thinking Augmented Pre-training》L Wang, N Yang, S Huang, L Dong... [Microsoft Research] (2025)
思维增强预训练(Thinking Augmented Pre-training, TPT)是一种创新且高效的语言模型训练方式,通过为原始文本自动生成“思维轨迹”来扩展训练数据,显著提升大语言模型(LLM)的学习效率和推理能力。
• 核心思想:对每个训练文档,利用开源LLM模拟专家的深入思考过程,生成解释复杂知识的“思维轨迹”,并将其与原文拼接,形成更具可学习性的训练样本。
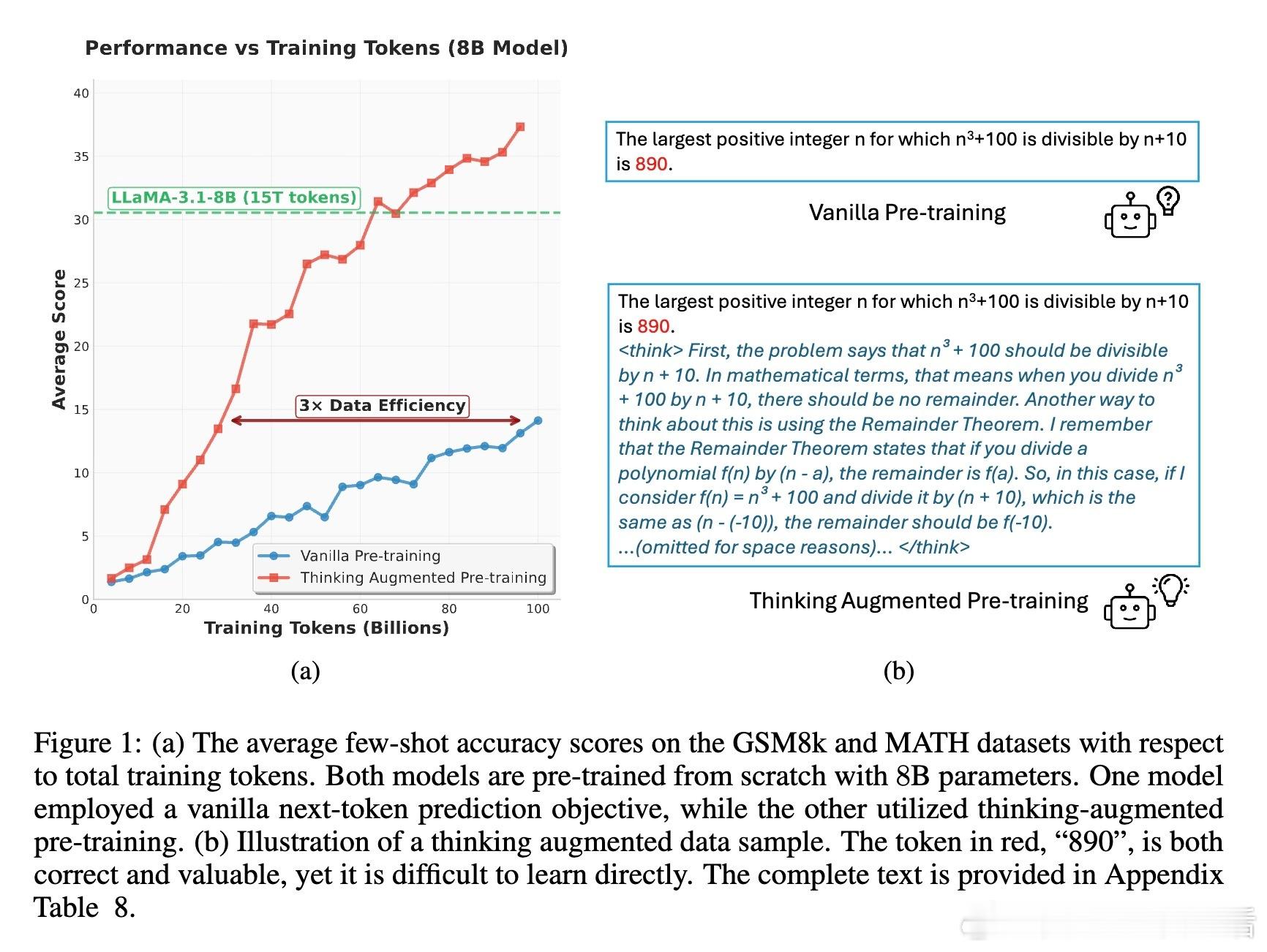
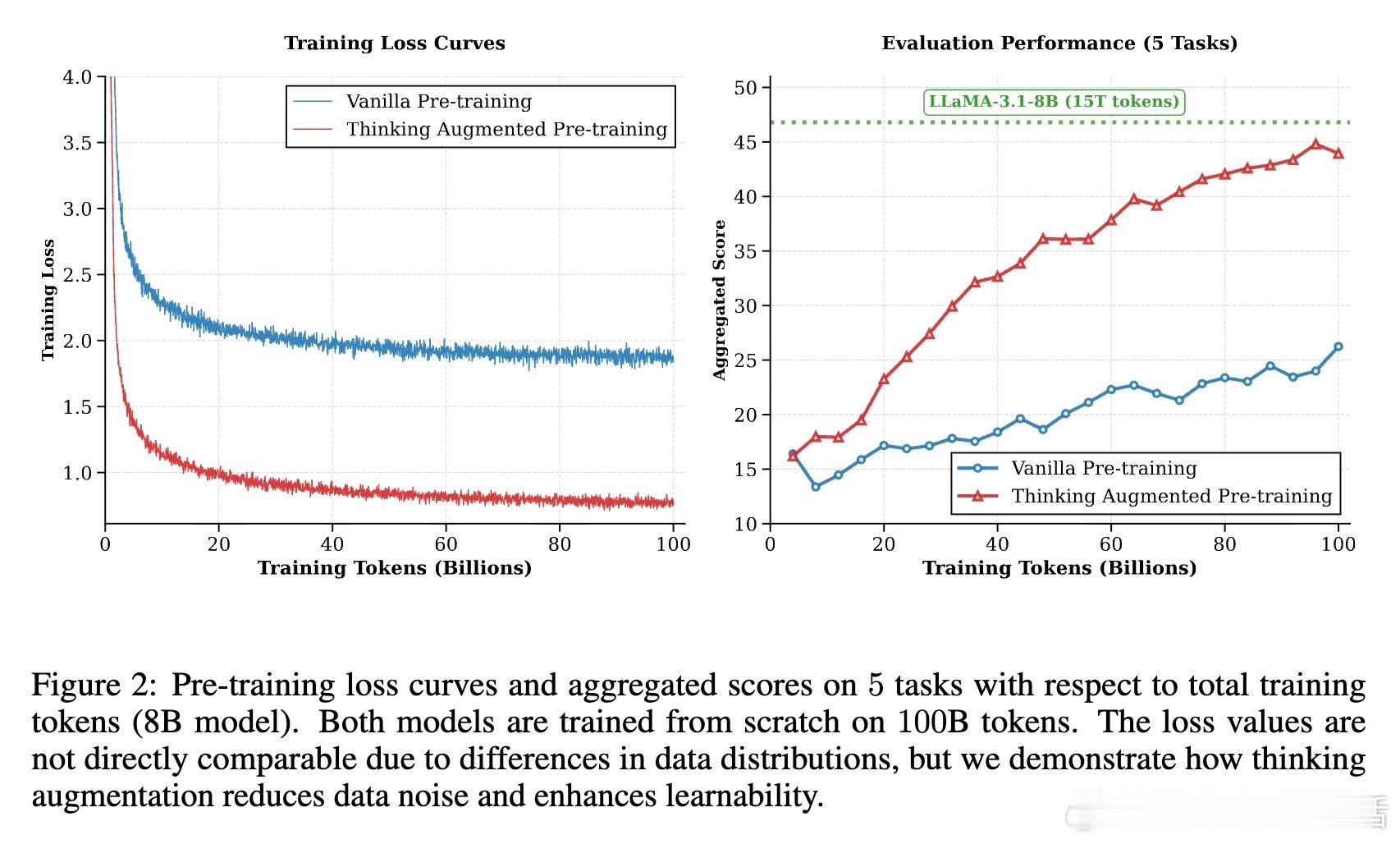
• 数据效率:TPT方法使得模型在相同数据量下的表现提升约3倍,8B参数模型在数学推理等挑战性任务上,准确率提升超10%。
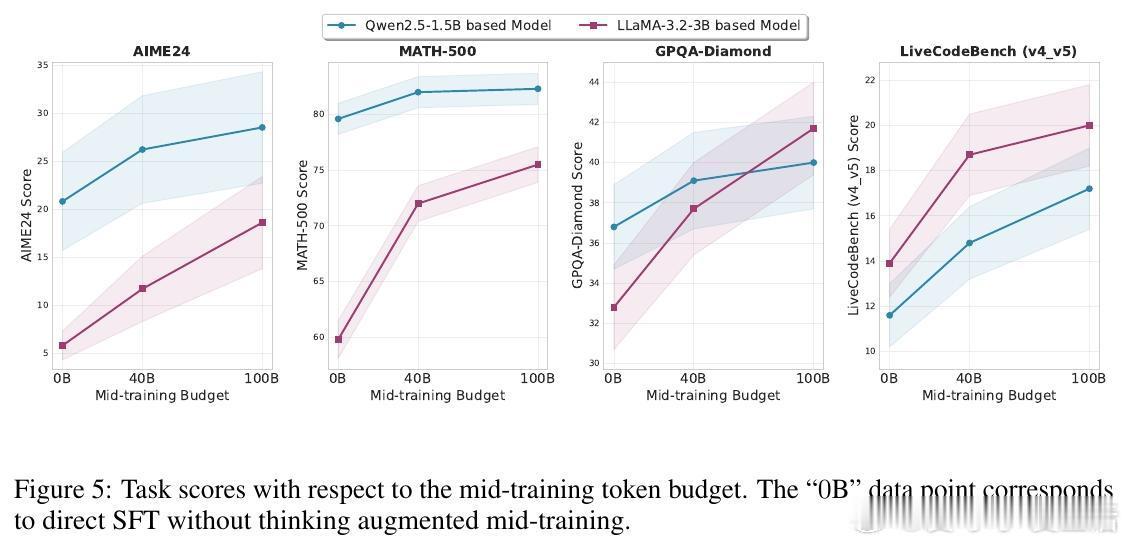
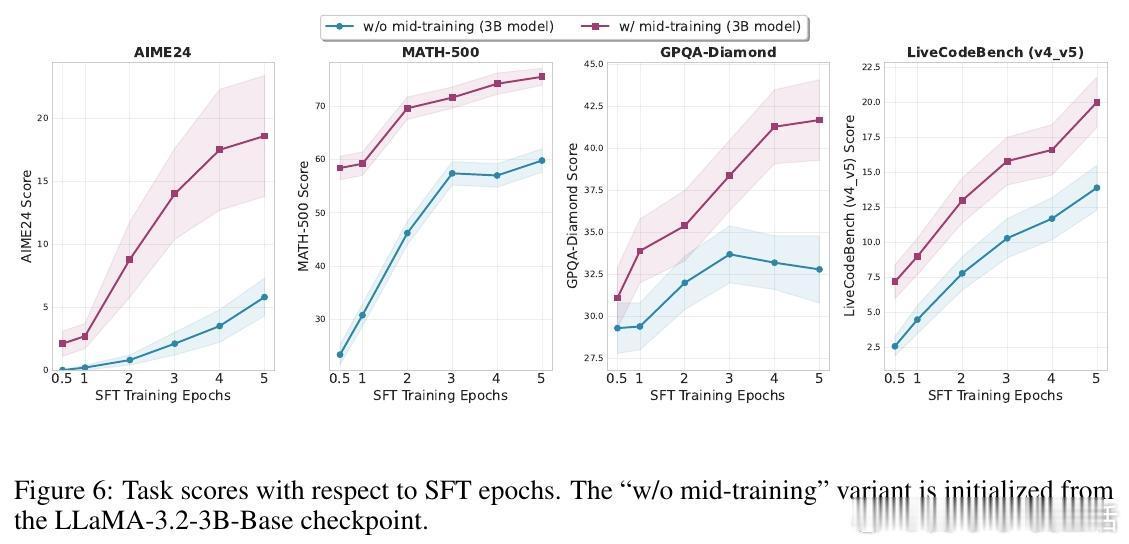
• 训练适用性:支持从零开始预训练(覆盖数据充足和受限场景)、中途训练(mid-training)和监督微调,适用多种模型架构与规模。
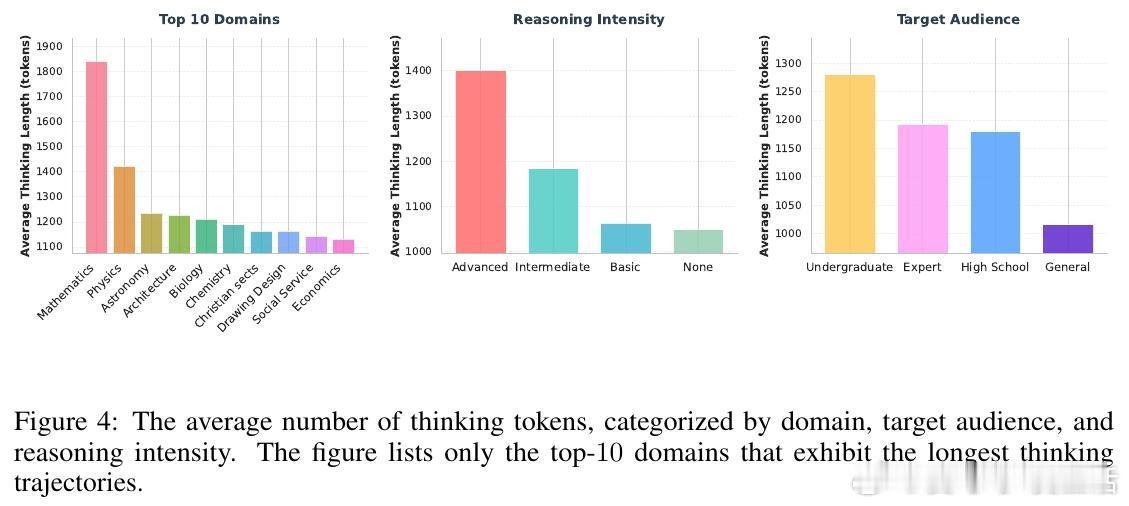
• 动态计算分配:长思维轨迹对应领域难度大、推理强度高的文本,相当于对高价值数据进行自然“上采样”,自动倾斜训练资源,提升难学知识的掌握。
• 训练成本与扩展性:无需人工标注,完全自动化,且不依赖特定文档结构;生成思维轨迹的计算开销远低于强化学习类方法,易于大规模推广。
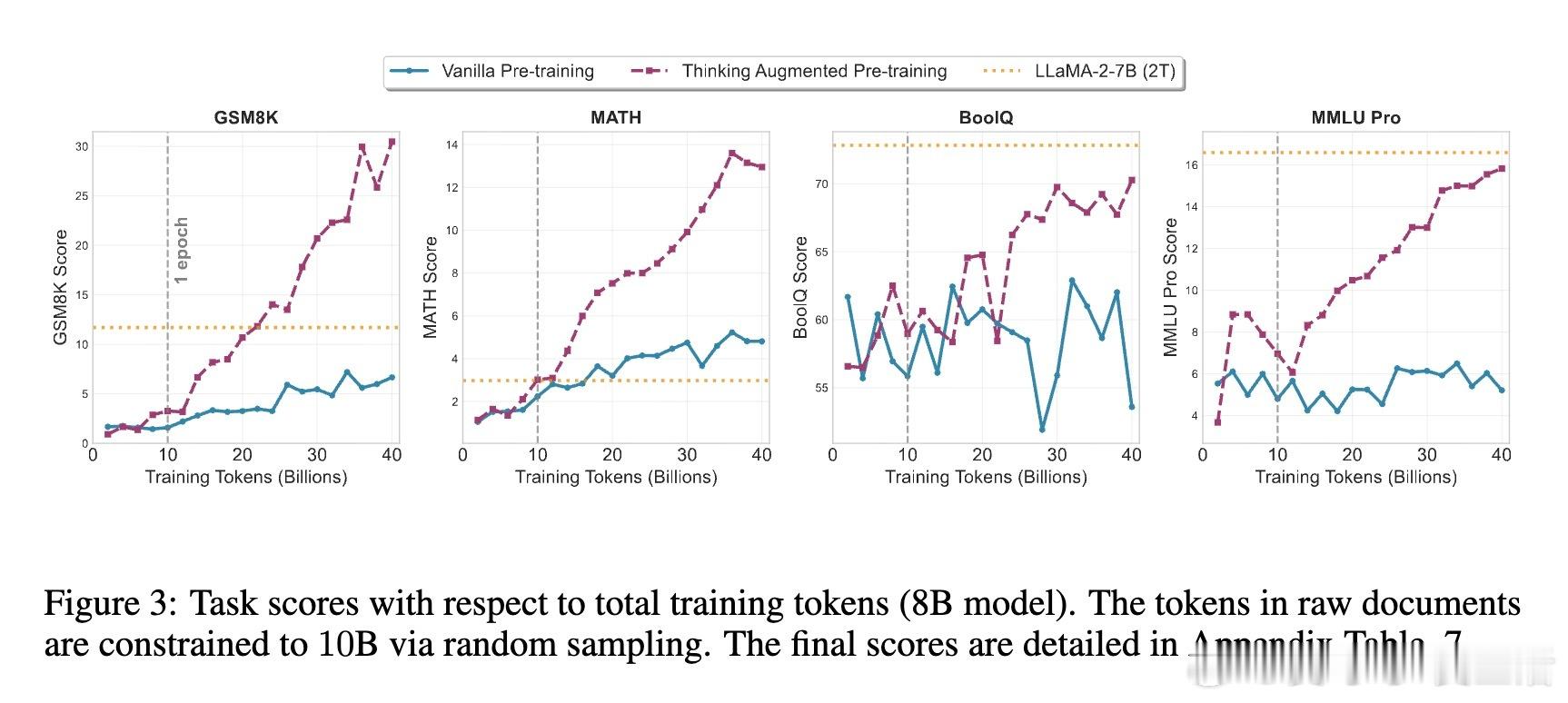
• 实验验证:覆盖数学、代码生成及通用推理10多个基准测试,TPT模型普遍超越无增强模型及多款公开开源模型,尤其在数学题、复杂推理和代码任务中表现突出。
• 思维轨迹生成策略:采用简单的基于提示词的专家模拟,不同生成策略效果接近,选用较小模型生成反而更利于下游学习,降低实现复杂度。
• 未来展望:结合自动化提示优化、探索更强思维生成模型及扩展至更大规模训练,进一步释放数据潜能。
心得:
1. 复杂知识单凭单步预测难以学习,逐步分解思考过程能显著提升模型对高价值信息的理解和泛化能力。
2. 数据质量不仅靠筛选和重写,结构化增强(如思维轨迹)能从现有数据中挖掘更大价值,突破数据瓶颈。
3. 训练阶段类似于“测试时放大计算”的思路,将更多计算资源动态赋予难点,助力模型在推理密集任务中快速成长。
详细阅读👉arxiv.org/abs/2509.20186
大语言模型预训练人工智能机器学习自然语言处理推理能力数据增强