
携手阿里,英特尔驱动Qwen3系列大模型的AI应用边界
为持续推动尖端AI模型创新发展,英特尔与业界创新力量深度协作,成果斐然。近日,全新升级的英特尔AI解决方案全面覆盖PC客户端、边缘计算、智能驾舱等场景,并第一时间助力阿里巴巴新一代通义千问Qwen3系列大模型发布。

Qwen3系列大模型五大亮点闪耀
稀疏MoE模型优化:深度优化稀疏MoE模型,让Qwen3在端侧实现高效部署,为端侧应用带来更多可能
NPU Day 0支持:首次在NPU上实现Day 0支持大模型,显著提升性能并降低功耗,为模型运行提供更优平台
端侧微调升级:通过端侧微调技术,提升模型智能水平,全方位优化用户体验,让AI更懂用户需求
动态稀疏注意力赋能:动态稀疏注意力机制赋予Qwen3长上下文窗口能力,解锁端侧Agent新应用,拓展AI应用场景
拥抱开源生态:积极拥抱开源生态,Day 0支持魔搭社区Ollama
Qwen3系列中,30B参数规模的MoE混合专家模型(Qwen3-30B-MOE-A3B)备受瞩目。其先进的动态可调混合专家架构大幅提升了计算效率,在本地设备上应用前景广阔。然而,部署难度大、系统资源消耗高成为制约因素。
为此,英特尔与阿里紧密合作,针对MoE模型展开全面技术适配。借助OpenVINOTM工具套件,成功将Qwen模型高效部署于英特尔硬件平台。在ARL-H 64G内存系统上,30B参数MoE模型实现33.97 token/s的吞吐量,较同等参数稠密模型有突出的性能提升。英特尔采用的软件优化策略涵盖算子融合、定制化调度和访存优化以及负载均衡,为更多MOE模型在英特尔平台高效部署提供有力支持。

此次发布的Qwen3系列模型,还聚焦中小参数量稠密架构LLM,参数规模从0.6B至32B不等,可适配更广泛的硬件资源,满足多样化使用场景需求。英特尔CPU、GPU、NPU架构全面适配Qwen系列模型,通过OpenVINOTM工具套件和PyTorch社区工具,为全系列Qwen模型在英特尔酷睿Ultra平台(酷睿Ultra 100系列/200系列)和英特尔锐炫A/B系列显卡上的部署提供卓越性能保障。
在酷睿Ultra的iGPU平台上,英特尔持续为模型带来卓越性能。针对小尺寸模型,FP16精度下最高达66 token/s;针对中小尺寸模型,INT4精度下最高达35.83 token/s。开发者可根据使用场景,灵活选择精度和性能的最佳组合。在英特尔锐炫B系列显卡强大算力加持下,Qwen3-8B模型可实现70.67 token/s。
当然,面对有限算力资源,英特尔基于动态稀疏注意力,在保证近乎无损精度的前提下,使长上下文窗口处理速度成倍提升。Qwen3-8B模型在英特尔LNL平台上可实现32K的上下文长度,解锁了更多端侧Agent新应用。

结合Qwen3更强的Agent和代码能力,以及对MCP协议的加强支持,基于端侧大模型调用MCP服务开发各种AI PC Agent成为可能。

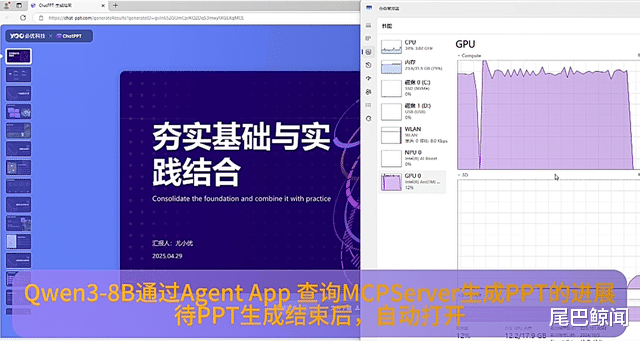
而在端舱内,基于英特尔车载软硬件解决方案,包括第一代英特尔AI增强软件定义汽车(SDV)SOC、第二代SDV SoC NPU以及英特尔锐炫™车载独立显卡,Qwen3系列模型有望快速上车部署,充分发挥车端本地算力。其中,第二代SDV SOC率先采用多节点芯粒架构,生成式和多模态AI性能相比上一代最高提升十倍,让汽车AI体验如舱内实时对话、自然语言交互和复杂指令响应等充满AI灵性。
