Meta搞定AI自我进化AI在开放世界自我进化
Meta新论文《SPICE(Self-Play in Corpus Environments)》,让AI自我进化这事儿,实现了关键突破。
此前训练AI的方法,有点像花钱雇许多人类专家,日夜不停地给AI当老师。这叫监督学习或RLHF(人类反馈强化学习)。
这个方法有用,但又贵又慢,而且人类老师的水平总有上限。
于是,Meta想到了一个聪明的办法:让AI自己玩(Self-Play)。
就像AlphaGo让AI一号和AI二号下棋。它们不知疲倦地对战几百万局,很快就超越了所有人类。
问题是,这个方法在下棋和玩游戏上很管用,但一旦用到语言和推理上,就失灵了。
为什么?
因为下棋有清晰的规则(赢或输)。而语言没有。
当你让两个AI自己玩语言游戏时,它们就像被关在了一个密闭的房间里,很快就会陷入一种AI幽闭恐惧症:
1. 废话循环 (Information Symmetry):两个AI知道的东西完全一样 。它们很快就穷尽了所有知识,开始出一些无聊的、重复的对话,学不到任何新东西。
2. 幻觉放大 (Hallucination Amplification):AI会犯错,这是难免的。但当一个AI用自己编造的错误知识去教另一个AI时,错误就会被当成真理来学习,它们会共同发疯。
这就是整个行业的问题:AI的自我提升,被困在了这个密闭的房间里。
而这篇来自Meta AI(FAIR)的论文,SPICE 5,它的核心贡献就是——给这个密闭的房间,开了一扇窗。
|SPICE:教授和学生的终极游戏
SPICE的全称是在语料库环境中自博弈 (Self-Play In Corpus Environments) 。
别被名字吓到。它的设计极其精妙,完美地解决了上面的两个问题。
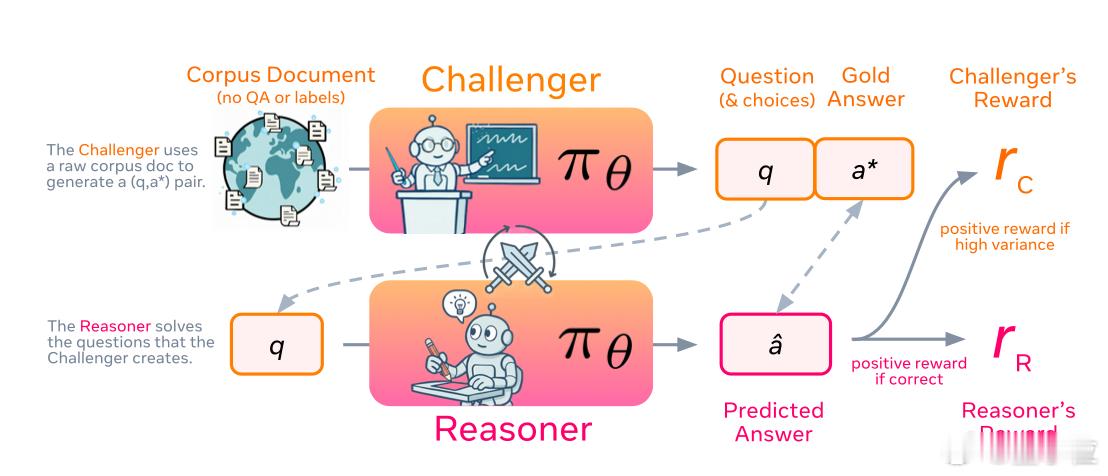
Meta不再让两个AI空对空地聊天。相反,他们只用了一个AI模型,让它精神分裂,同时扮演两个角色:
1. 角色一:博学的出题教授 (The Challenger)
2. 角色二:勤奋的盲解学生 (The Reasoner)
这个游戏是这么玩的:
|第一幕:教授进图书馆
首先,系统会把教授(Challenger)扔进一个巨大的图书馆,这个图书馆就是语料库 (Corpus)——包含了海量的真实网页、书籍、论文等。
教授的唯一任务是:
1. 从书架上随便抽一本书(一份真实文档)。
2. 基于这份文档,挖空心思设计一道极具挑战性的推理题。
3. 同时,它必须从文档中找到100%正确的黄金答案 (Gold Answer) 。
这解决了幻觉放大的问题。 因为所有的题目和答案都锚定在真实世界的知识上,AI无法凭空编造。
|第二幕:学生进考场
接下来,系统会把学生(Reasoner)关进一个小黑屋考场。
学生只能看到教授出的那道题。它绝对不准进入图书馆(即无法访问原始文档)。
学生的唯一任务是:仅凭自己已有的知识和推理能力,解开这道题。
这解决了废话循环的问题。 教授看过答案(文档),而学生没看过。这种信息不对称 (Information asymmetry) 创造了有意义的挑战。
|第三幕:关键的奖励机制
游戏玩完了,该发工资(奖励)了。
- 给学生的奖励:很简单。答对了,给个大红花(正奖励) 。
- 给教授的奖励:这是SPICE的神来之笔。
教授的KPI不是题出得有多难。如果它出的题太偏太怪,学生一道都答不上来(0%的通过率),教授会被扣工资。如果它出的题太简单,学生闭着眼都全对(100%的通过率),教授同样被扣工资。
教授只有在一种情况下能拿到最高奖金:它出的题,刚好让学生的通过率卡在50%左右。
这在教育学上被称为学习甜点区(Sweet Spot),或者说,刚刚好的挑战。
|进化是如何发生的?
当这个游戏被循环几万次后,一个类似生物进化的奇妙场景出现了 22:
- 第1轮: 学生很笨。教授为了保持50%的通过率,只能从图书馆里找点简单的素材,出一些表面问题(比如图5里的:月球的直径是多少?)。
- 第100轮: 学生通过做题,变聪明了。简单的表面问题已经难不倒它了(通过率变成了80%)。
- 第101轮: 教授发现自己的工资变少了(因为题太简单),于是它被迫回到图书馆,去啃那些更硬的骨头(比如复杂的物理原理),然后设计出更刁钻的多步推理题(比如图5里的:基于日食原理,计算一个外星系统的恒星距离)。
- 第102轮: 学生面对新难题,通过率又掉回了50%。它必须绞尽脑汁,学会更复杂的解题逻辑。
- 第500轮: 学生进化了。它不再是靠猜,而是学会了像图6那样,一步一步结构化地分析问题:
1. 步骤一:识别已知信息……
2. 步骤二:理解日食的条件……
3. 步骤三:列出方程式……
4. 步骤七:验证答案……
看,这不再是训练,这是共同进化 (Co-evolution) 。
教授(Challenger)和学生(Reasoner)就像自然界中的捕食者和猎物,它们在竞赛中螺旋式地上升。
|实验结果
这篇论文的图表(Figure 1)给出了答案:
1. 它效果拔群:在多个推理基准测试上,SPICE方法让模型性能大幅提升(比如Qwen3-4B提升了9.1%,OctoThinker-8B提升了11.9%) 。
2. 它吊打了前辈:那些密室幽闭型的自博弈方法(如R-Zero和Absolute Zero),被SPICE全面超越。
3. 它证明了自己:论文还做了拆解实验(Ablations,见图1(a)):
- 如果去掉图书馆(No Corpus):AI立刻变笨。证明了真实世界的知识是不可或缺的。
- 如果教授不进化(Fixed Challenger):AI也变笨。证明了刚刚好的挑战这个动态过程是成功的关键。
|SPICE可能是个里程碑
SPICE的真正意义在于,它描绘了一条全新的、可扩展的AI成长路径。
过去,我们只有两条路:要么靠人力硬推(监督学习),要么靠算力在密室里硬憋(纯自博弈)。
SPICE提出了第三条路:AI在开放世界中的自我进化。
它不再需要昂贵的人类老师,也不再依赖有限的规则。它只需要两样东西:
1. 一个足够大的世界(互联网文档库)。
2. 一个逼自己一把的动力机制(教授和学生的博弈)。
这让AI第一次有能力自动地、持续地从这个世界汲取养分,并自动地把这些养分转化成越来越难的课程,最终实现自我完善。
网友评价道:我们可能正在见证一个AI,第一次真正意义上摆脱了密闭房间,开始靠自己走向更广阔的世界。