7个大模型输出质量参数LLM怎么调参
LLM调参都调什么?
7个决定大模型输出质量的核心参数,码住方便回看:
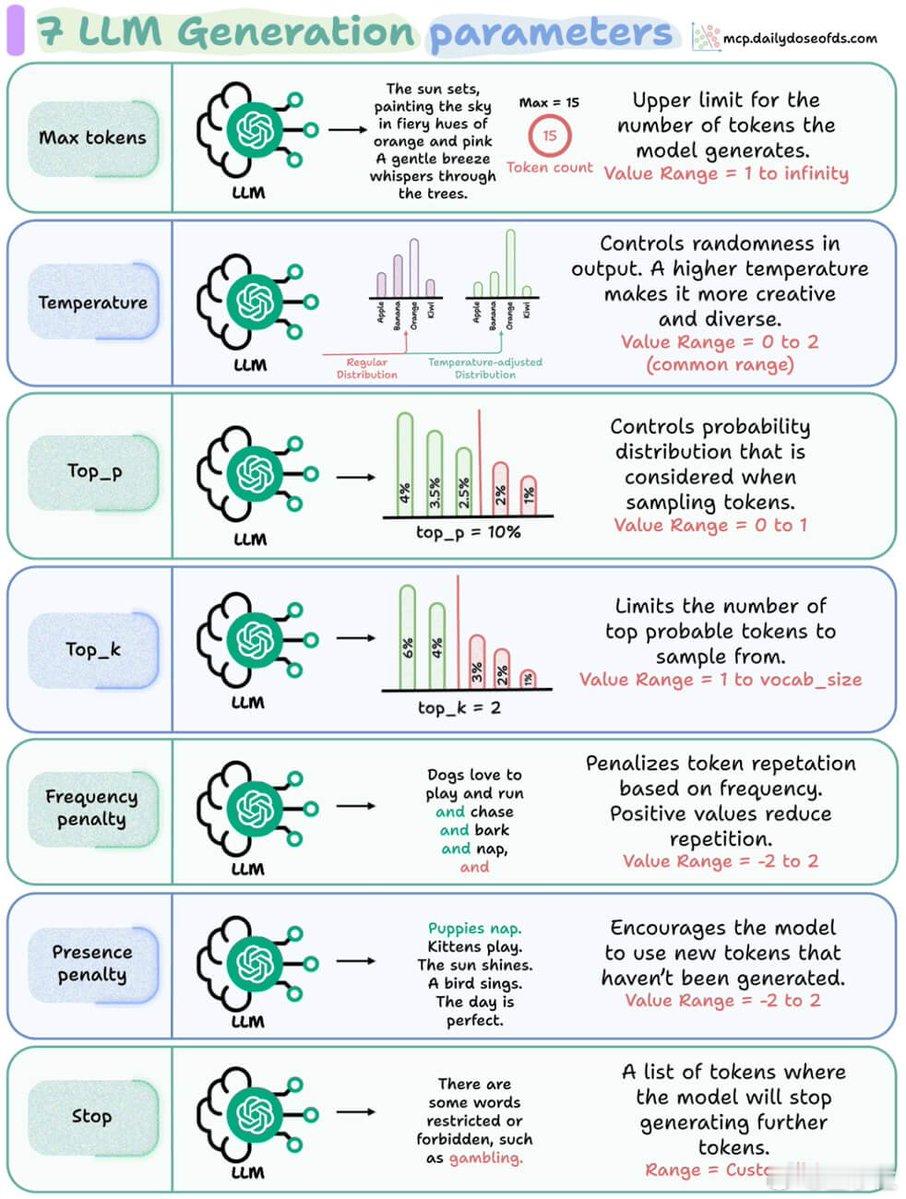
1. Max tokens(最大长度) → 控制它话多话少的关键参数。
限制输出最多token数。设成100,AI就输出100词后立即停下,不管有没有说完。
2. Temperature(温度) → 决定它是严谨还是跳脱。
温度越高(接近2),输出越随机、越有创意;越低(接近0),输出越保守、越稳重。
3. Top_p(核采样) → 控制AI选词范围。
Top_p设成0.9,AI会从概率前90%的词中选词,越小范围越窄,越大则选择更多。
4. Top_k(选择前k个词) → 控制它的词库大小。
设成5,AI每次只能从前5个最可能的词中挑选输出,限制它的选择范围。
5. Frequency penalty(频率惩罚) → 避免重复。
这个惩罚分数越高,AI就越不愿重复已经使用过的词,避免啰嗦。
6. Presence penalty(存在惩罚) → 强迫AI尝试新词。
它鼓励AI说出新词汇,避免一成不变,增加输出的多样性。
7. Stop(停止词) → 确定AI何时停下。
设置特定的停止词,一旦AI输出到这些词就立即停下,比如“结束”或“谢谢”。
这些参数的组合,其实就是调“AI性格”的过程:
调高温度+低惩罚,它就天马行空;
调低温度+加惩罚,它就严谨靠谱;
再配上合理的Top_p、Top_k,就能拿捏“表达范围”——是自由发挥,还是紧跟提示。
你想让它像个学者、诗人、客服,还是法律顾问,全靠调得对。