[LG]《Benefits and Pitfalls of Reinforcement Learning for Language Model Planning: A Theoretical Perspective》S Wang, Y Shen, H Sun, S Feng... [Microsoft Research Asia & Peking University] (2025)
强化学习(RL)如何提升大型语言模型(LLM)规划能力?理论揭示细节与盲点:
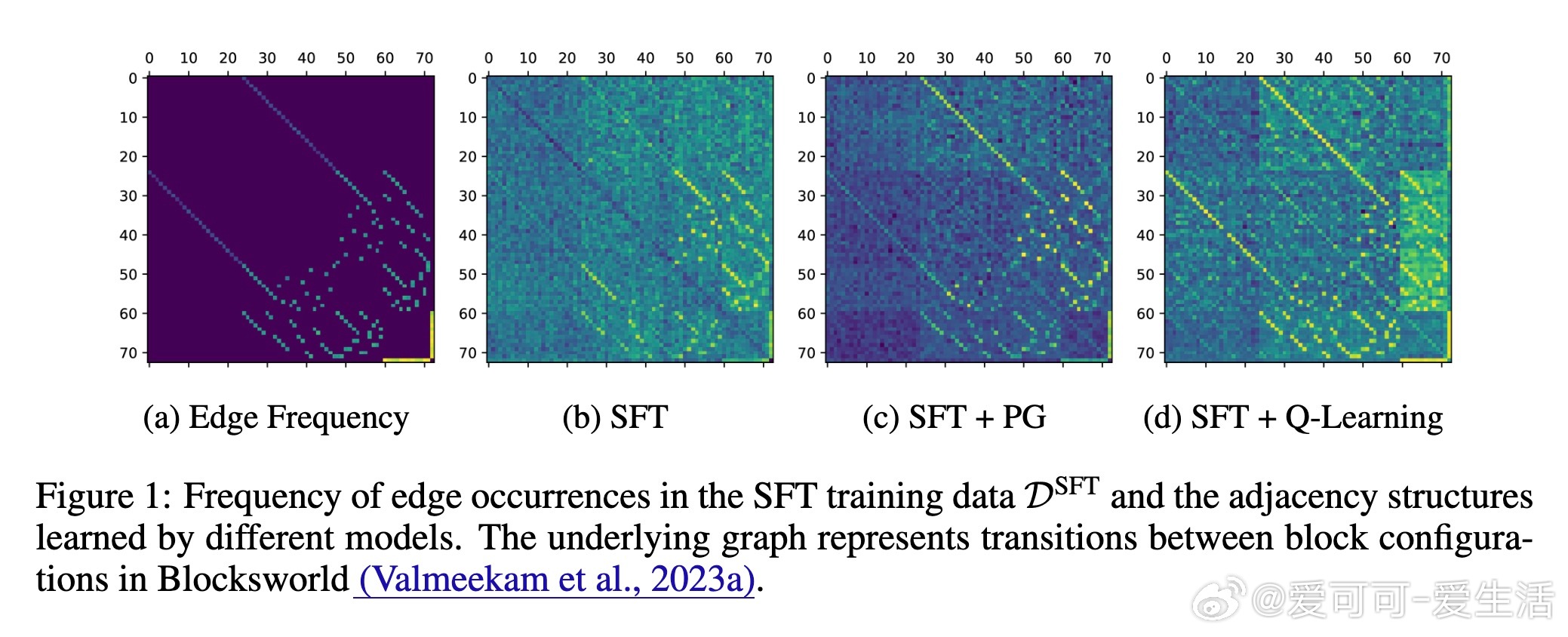
• 监督微调(SFT)易陷入基于共现的伪解,难以捕捉图结构的可达性传递性,表现为“死记硬背”。
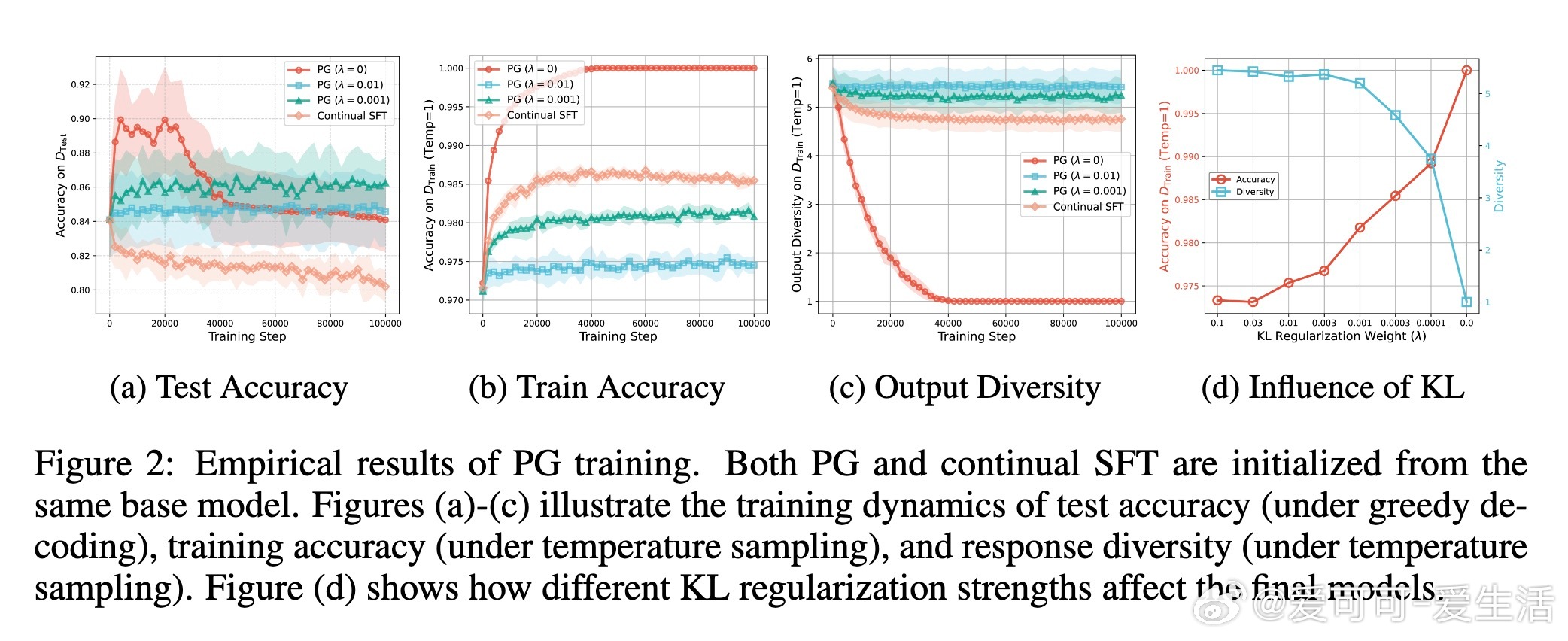
• RL通过探索生成训练数据,显著扩展路径多样性和泛化能力,政策梯度(PG)方法本质上是对探索数据的SFT。
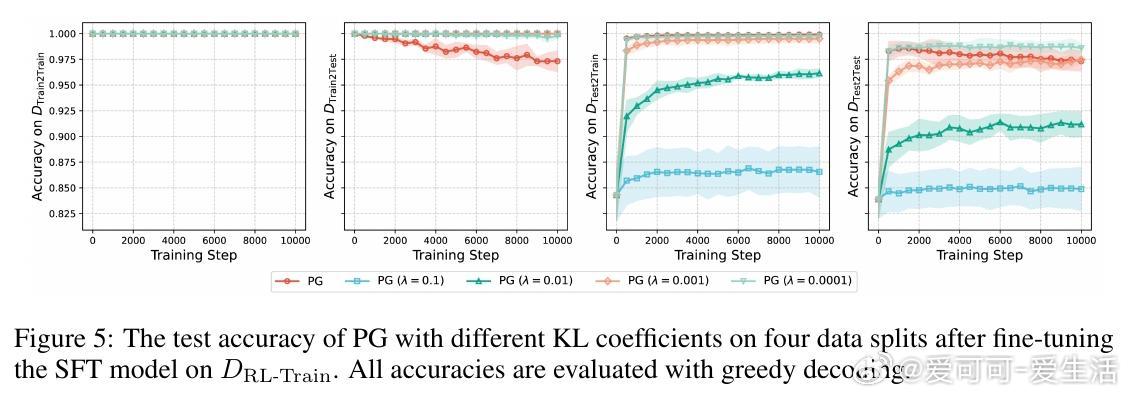
• PG存在“多样性坍缩”问题:训练准确率达100%后,输出路径趋于单一,限制泛化;加入KL正则化可保留多样性,但代价是训练准确度下降。
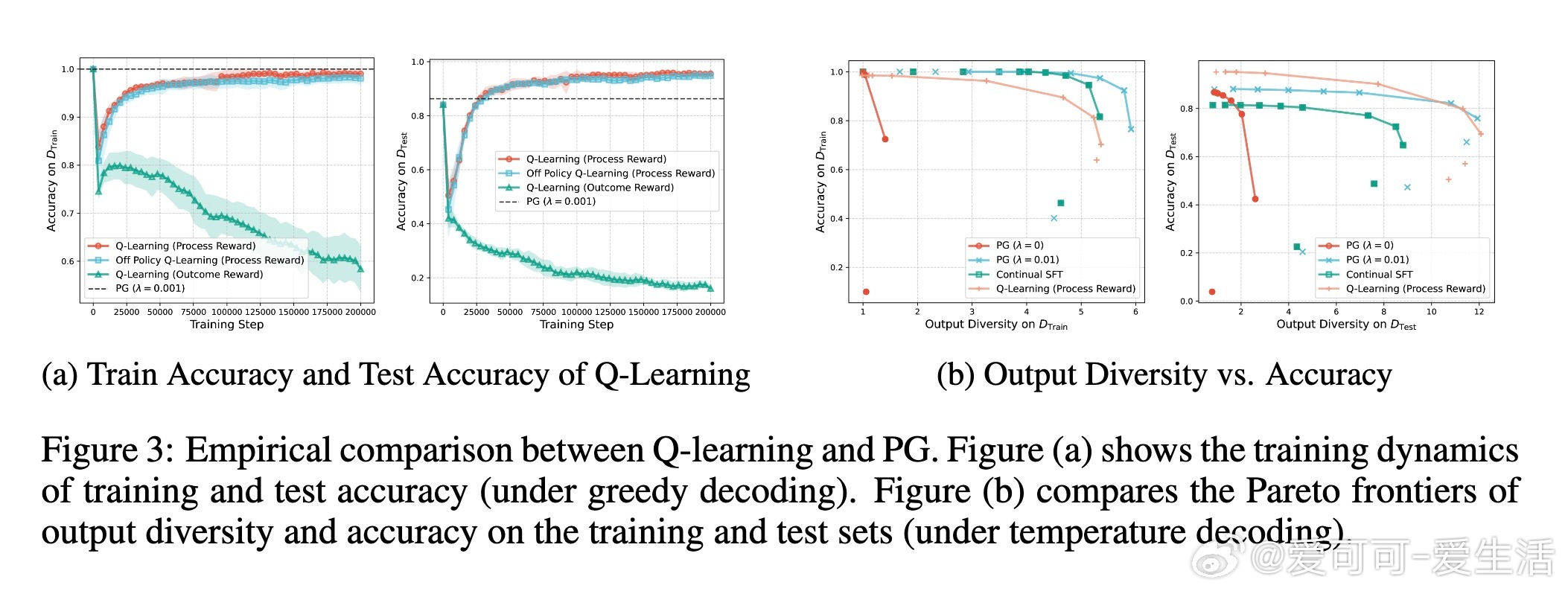
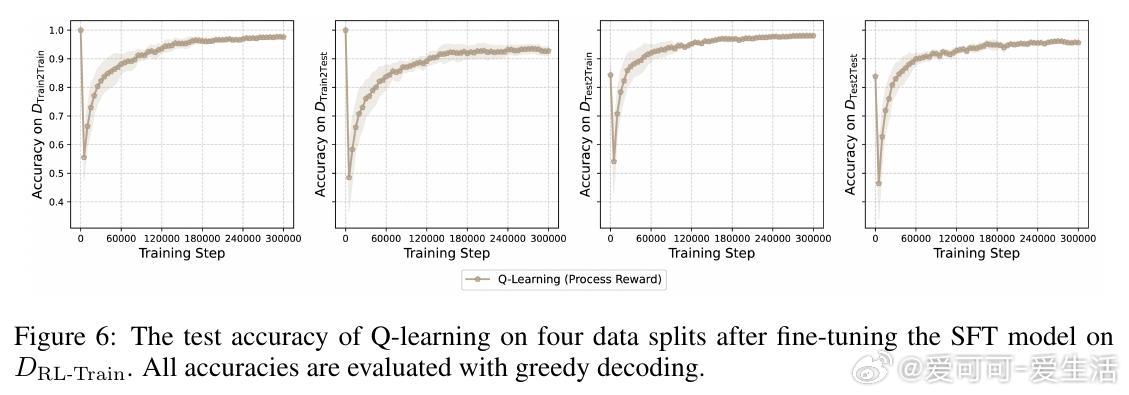
• Q-learning优势明显:支持离线(off-policy)学习,收敛时保留输出多样性;但仅使用最终结果奖励容易出现奖励作弊,需引入过程奖励(逐步奖励)防止误导。
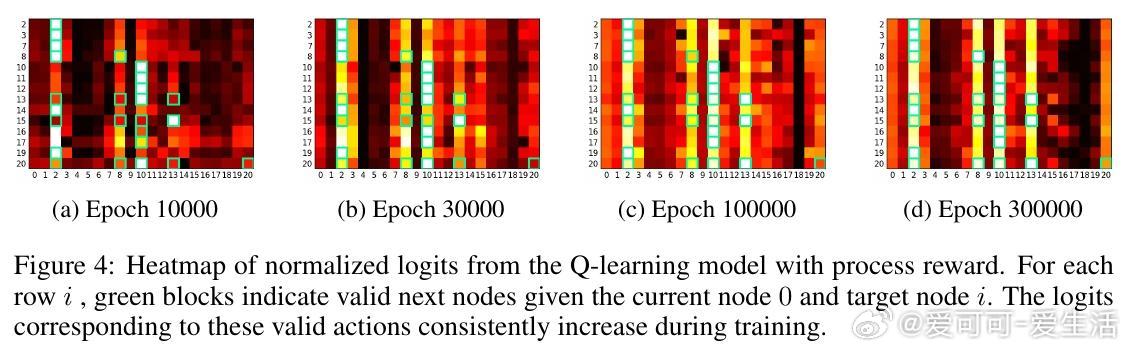
• 过程奖励设计使Q-learning稳定收敛,准确捕获图的邻接和可达关系,实验证实Q-learning在Blocksworld等规划任务中几乎恢复完整拓扑结构。
• 理论与实证相辅相成,揭示RL超越SFT优势根源于探索机制,Q-learning为未来可扩展、高鲁棒规划框架指明方向。
心得:
1. 规划能力的提升,不是简单拟合,而是通过探索增加训练数据覆盖,突破SFT的“记忆瓶颈”。
2. 多样性是泛化关键,忽视多样性会导致模型陷入单一路径,影响复杂任务表现。
3. 奖励设计至关重要,过程奖励比单一结果奖励更能引导模型学习真正有效的规划策略。
详见🔗arxiv.org/abs/2509.22613
人工智能 强化学习 大型语言模型 规划算法 机器学习理论