[CV]《LayerLock: Non-collapsing Representation Learning with Progressive Freezing》G Erdogan, N Parthasarathy, C Ionescu, D Hudson... [Google DeepMind] (2025)
LayerLock:突破视觉自监督学习瓶颈的渐进冻结新策略
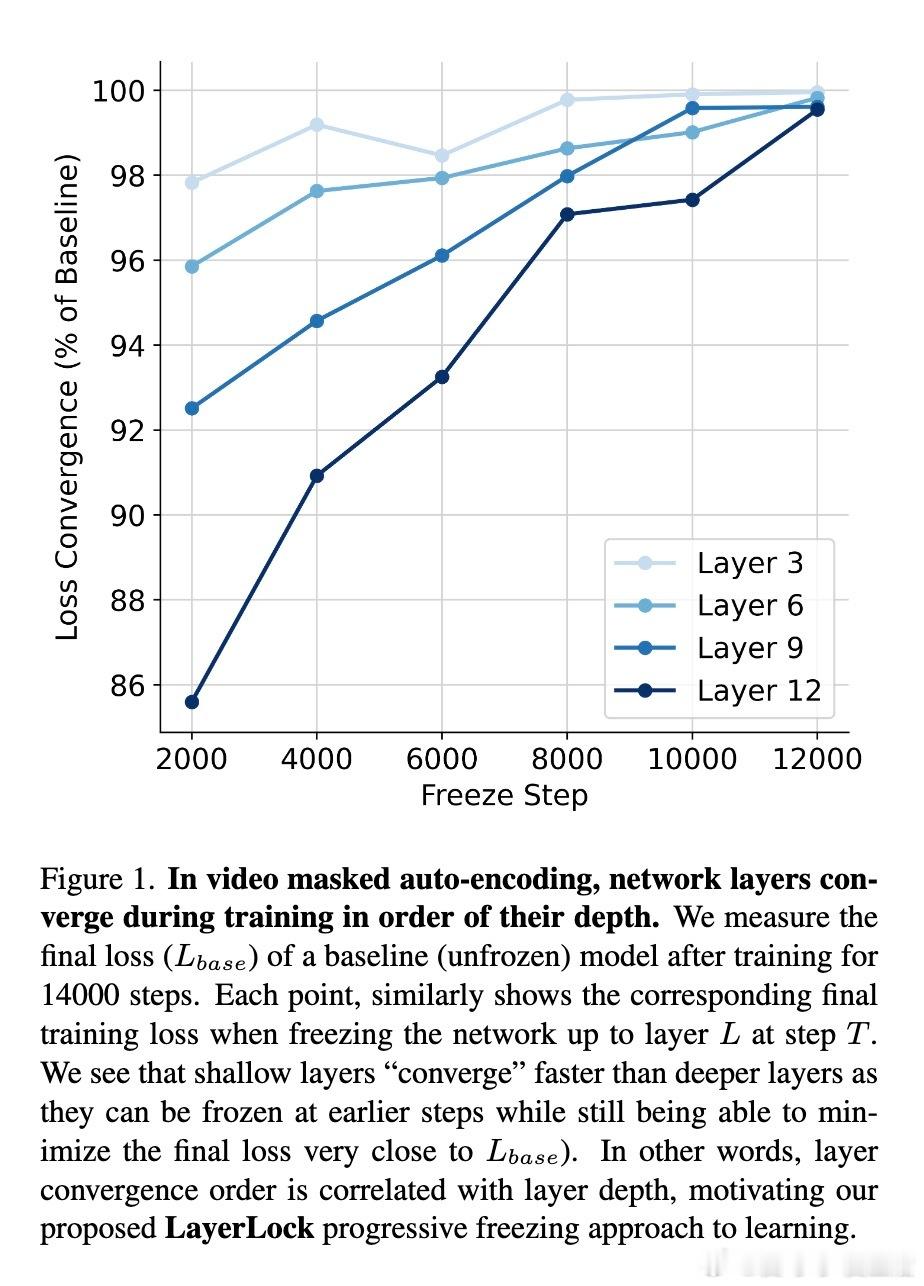
• 观察到视频MAE训练中,ViT模型的层次以深度顺序逐层收敛——浅层先收敛,深层后收敛。
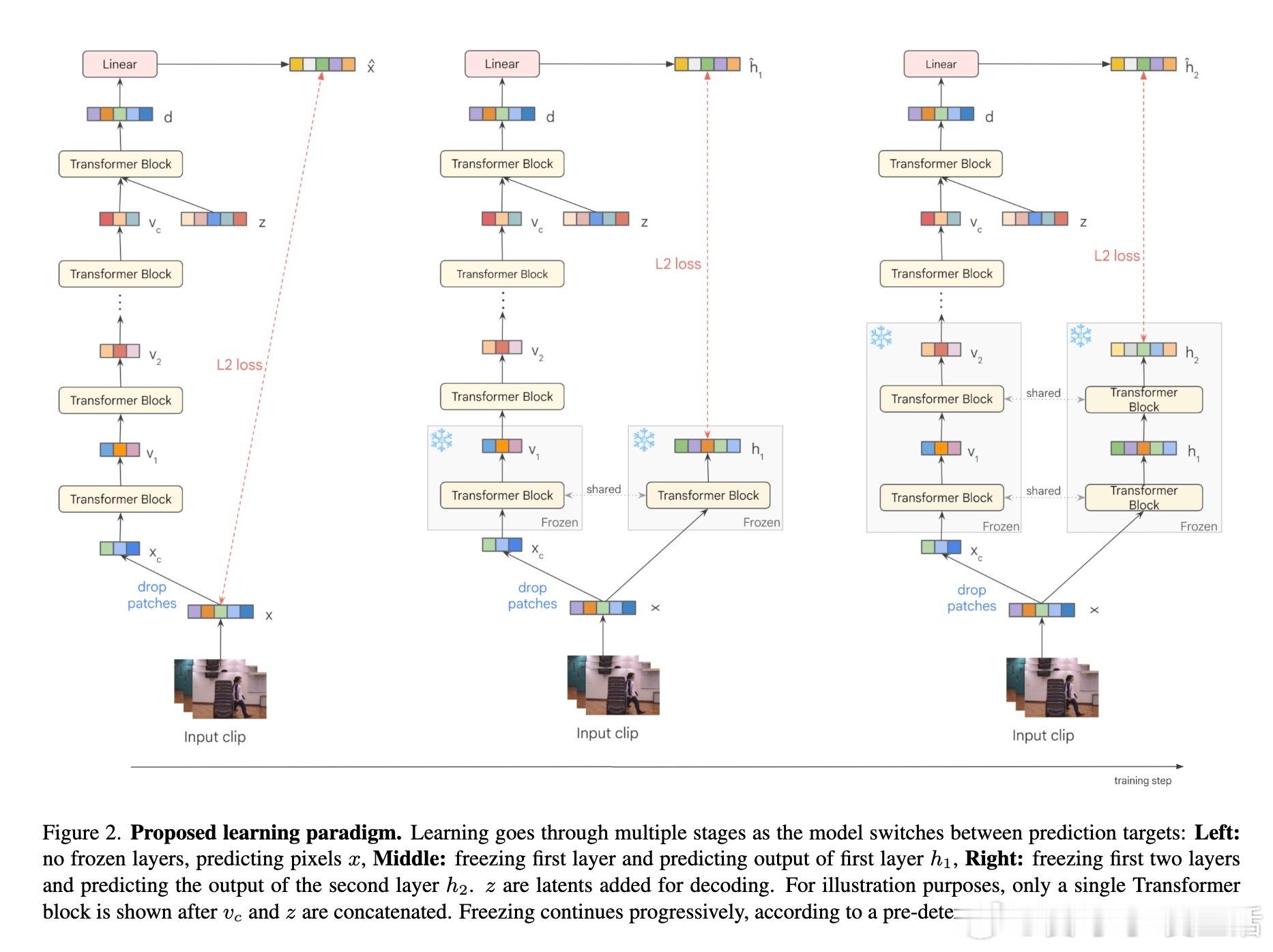
• 基于此,LayerLock提出渐进冻结策略,训练初期预测像素级低层特征,逐步冻结浅层并切换到预测更深层次的潜在表示,融合像素预测的稳定性与潜在预测的语义抽象优势。
• 该方法适用于像素预测(VideoMAE)与潜在预测(V-JEPA)两大流派,支持超大规模模型(最高达40亿参数),显著提升动作分类(SSv2、Kinetics700)和深度估计(ScanNet)等多层次视觉任务表现。
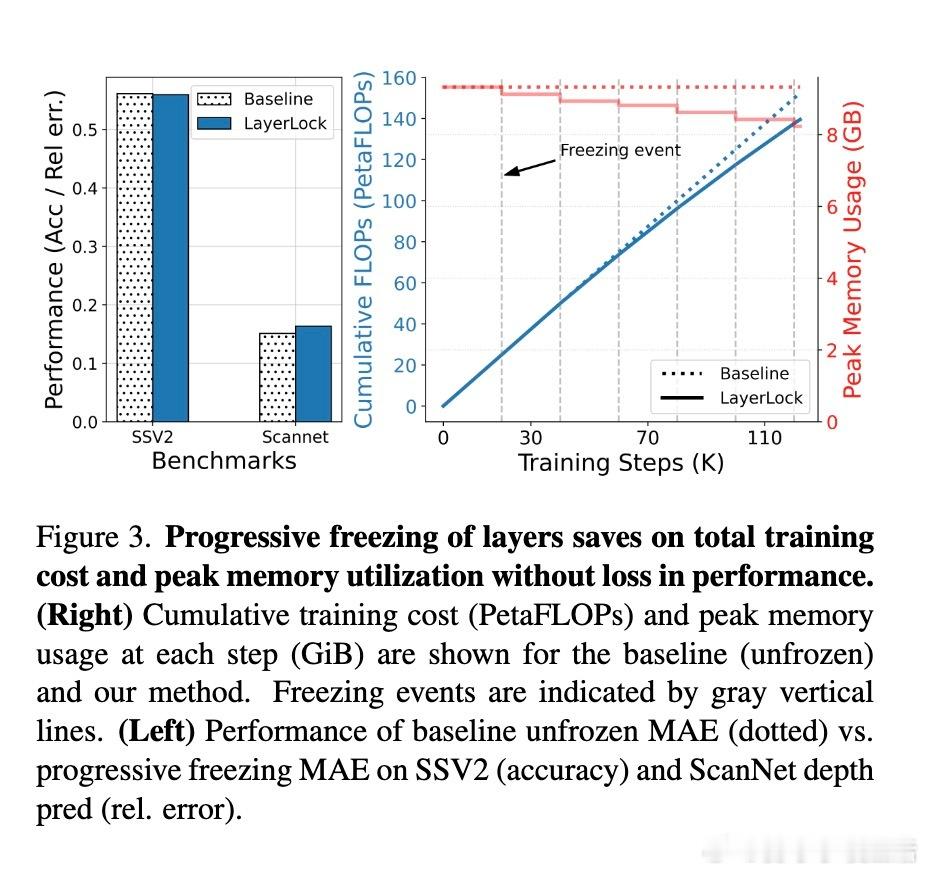
• 通过逐层冻结,LayerLock减少反向传播计算和显存压力,提升训练效率,实测节省最高19% FLOPs和16%峰值内存。
• 引入创新3D旋转位置编码(3D RoPE),有效增强时空编码能力,提升下游任务性能。
• 多项消融实验验证渐进冻结避免潜在预测常见的“表示坍缩”问题,单目标预测策略简洁有效,训练时切换预测目标配合学习率微调稳定训练过程。
心得:
1. 训练过程中层级收敛规律是提升大规模视觉模型训练效率和稳定性的关键突破口。
2. 自监督学习中“从低级到高级”渐进预测目标设计,兼顾了训练稳定性与语义表达能力,减少了传统潜在空间预测的陷阱。
3. 结合生物视觉系统“关键期”塑性机制,LayerLock通过动态冻结策略为机器视觉提供了新范式,有望推广至更长视频和更深模型的训练。
🔗arxiv.org/abs/2509.10156
视觉表示学习自监督学习深度学习视频理解视觉变换器模型训练优化人工智能







![钱学森在1992年就已经意识到今天火热的人工智能[并不简单]](http://image.uczzd.cn/836658470808337902.jpg?id=0)
