Gemini对话就能分割图像Gemini对话圈出图中物体
Gemini 2.5支持用对话进行图像分割了。
也就是说,Gemini能听懂你的自然语言描述,并准确标注对应区域:
- 【图1】“safe places to land”:在直升机视角图中,系统成功圈出楼顶的停机坪;
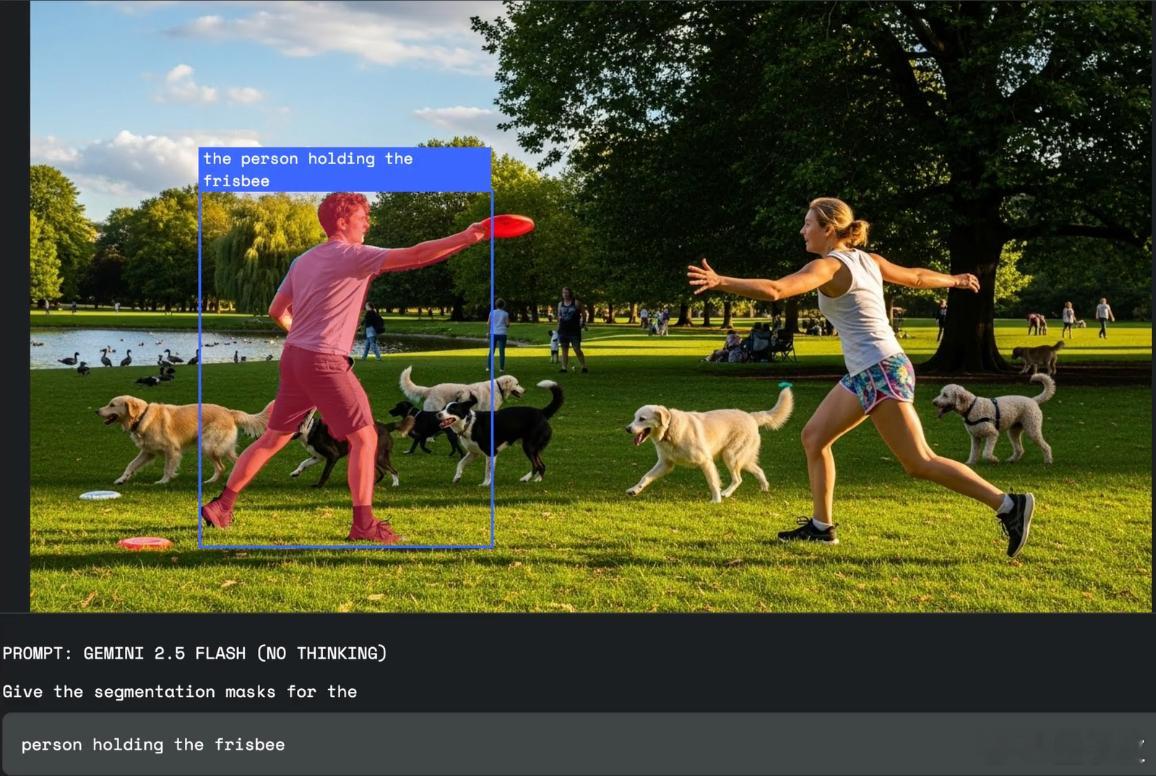
- 【图2】“the person holding the frisbee”:在公园草地场景中,识别并标注出正准备投掷飞盘的男性;
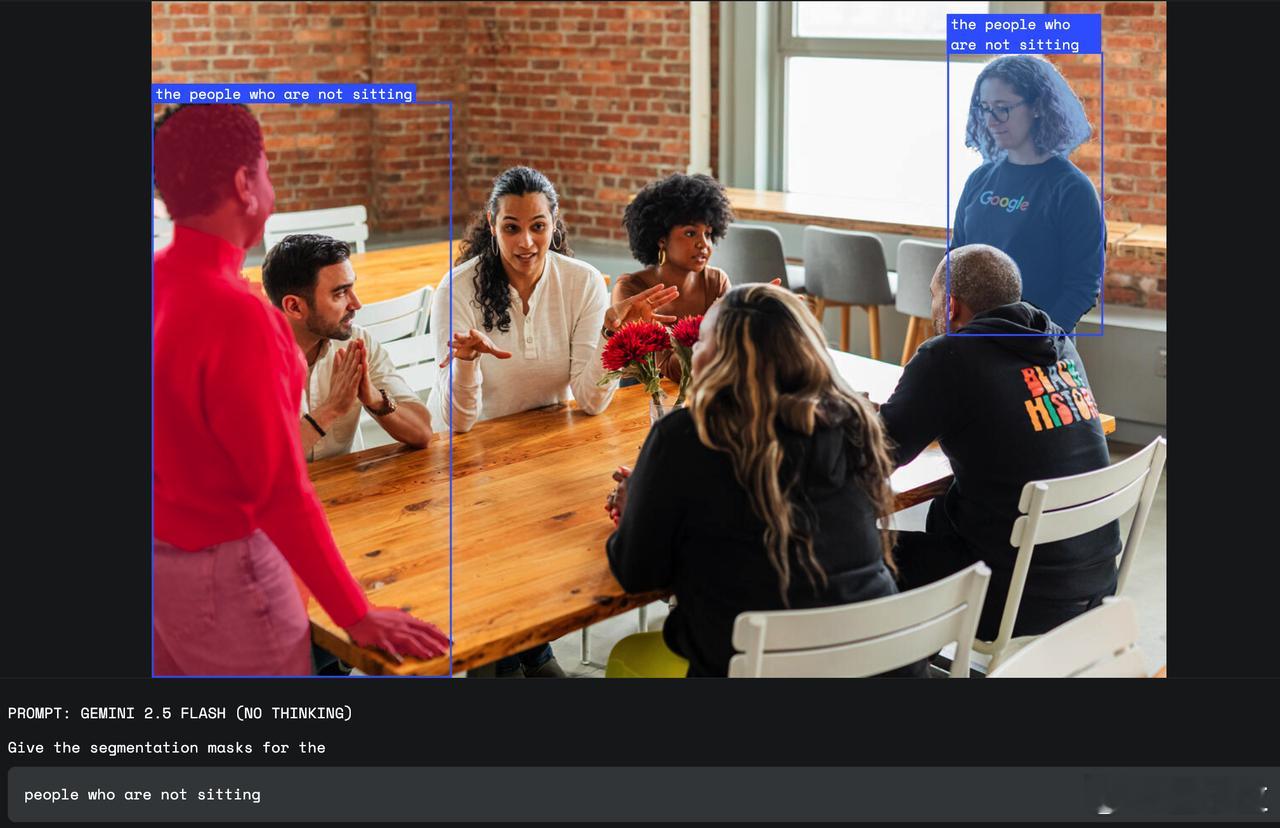
- 【图3】“the people who are not sitting”:会议室中,准确标出站立的两人;
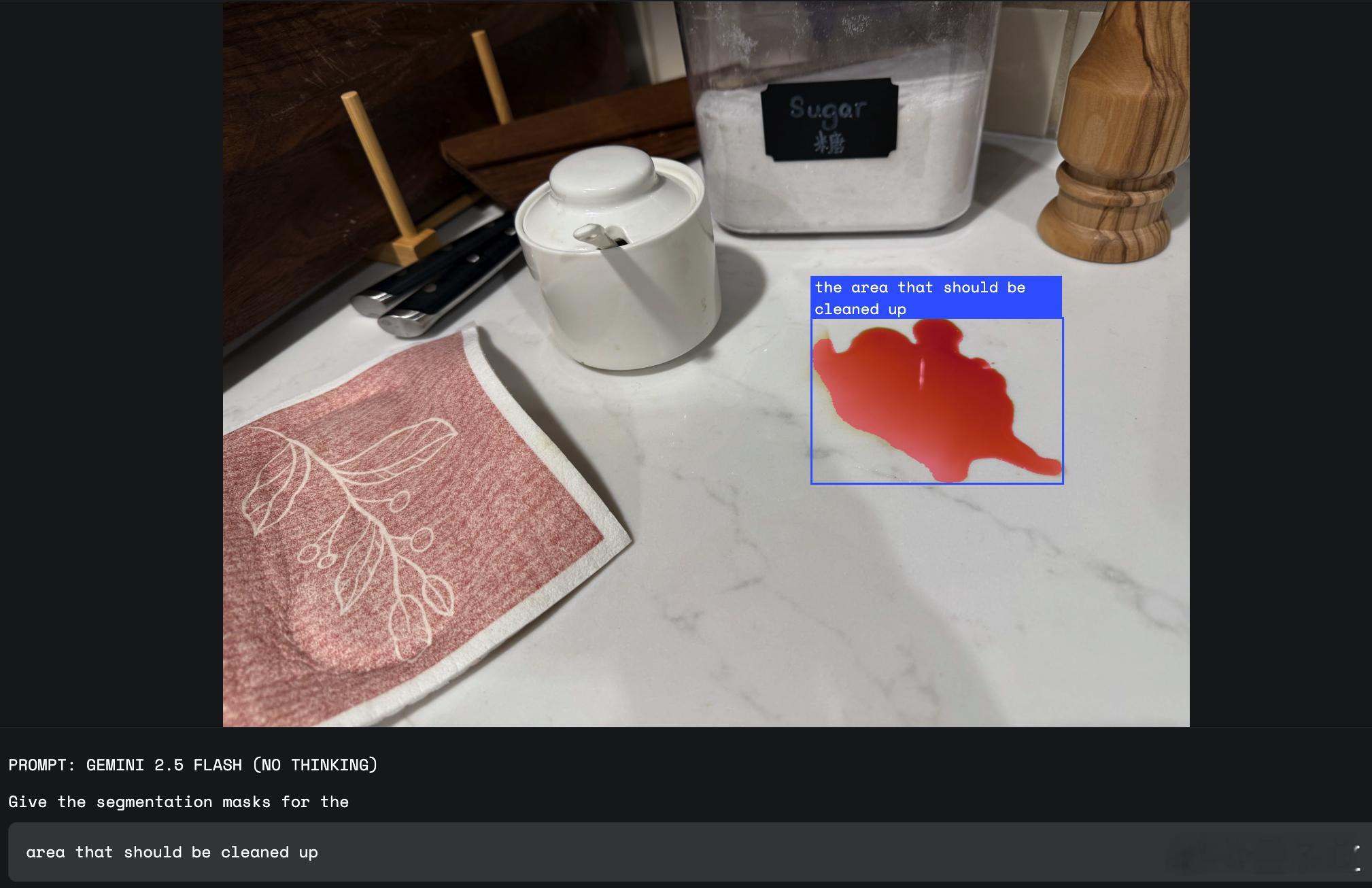
- 【图4】“the area that should be cleaned up”:识别出厨房台面上的红色液体污渍;
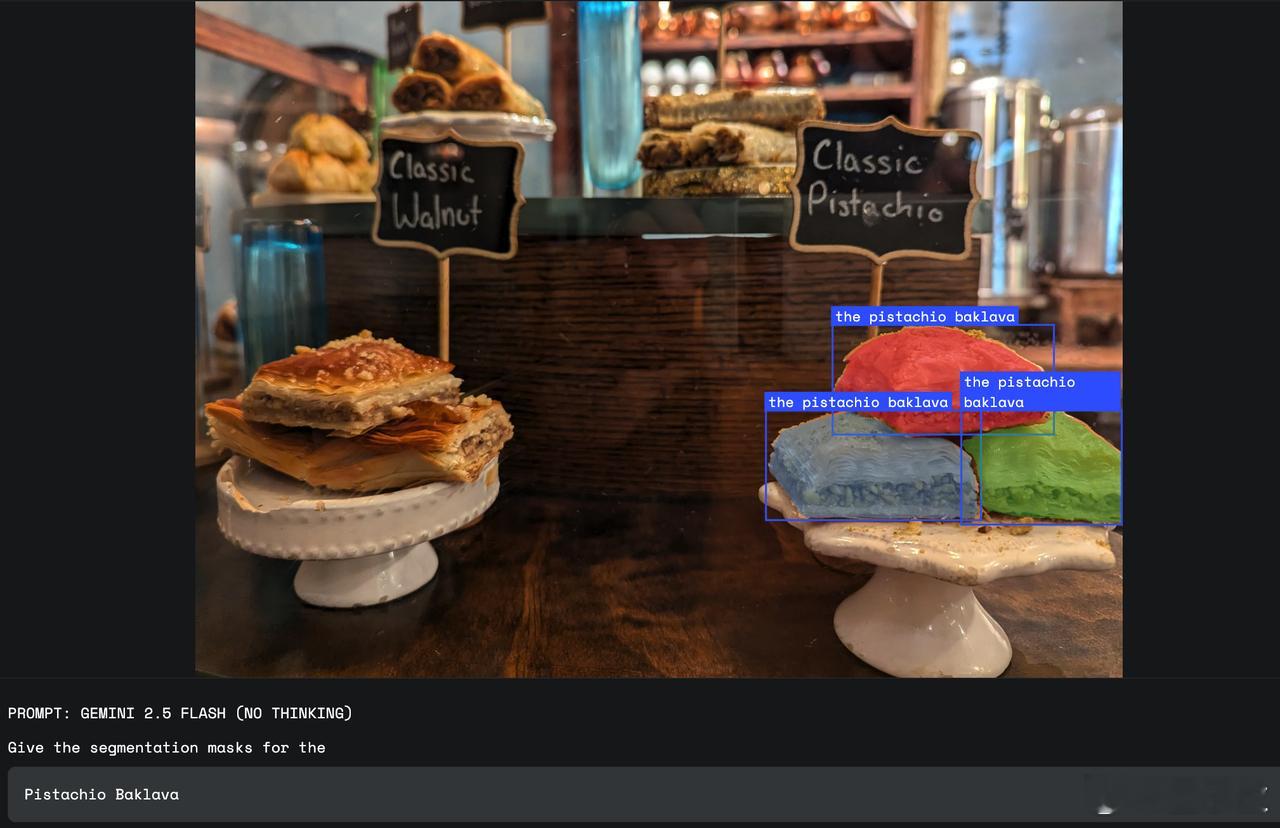
- 【图5】“the pistachio baklava”:在面包店内,通过读取招牌文字,圈出开心果口味的甜点;
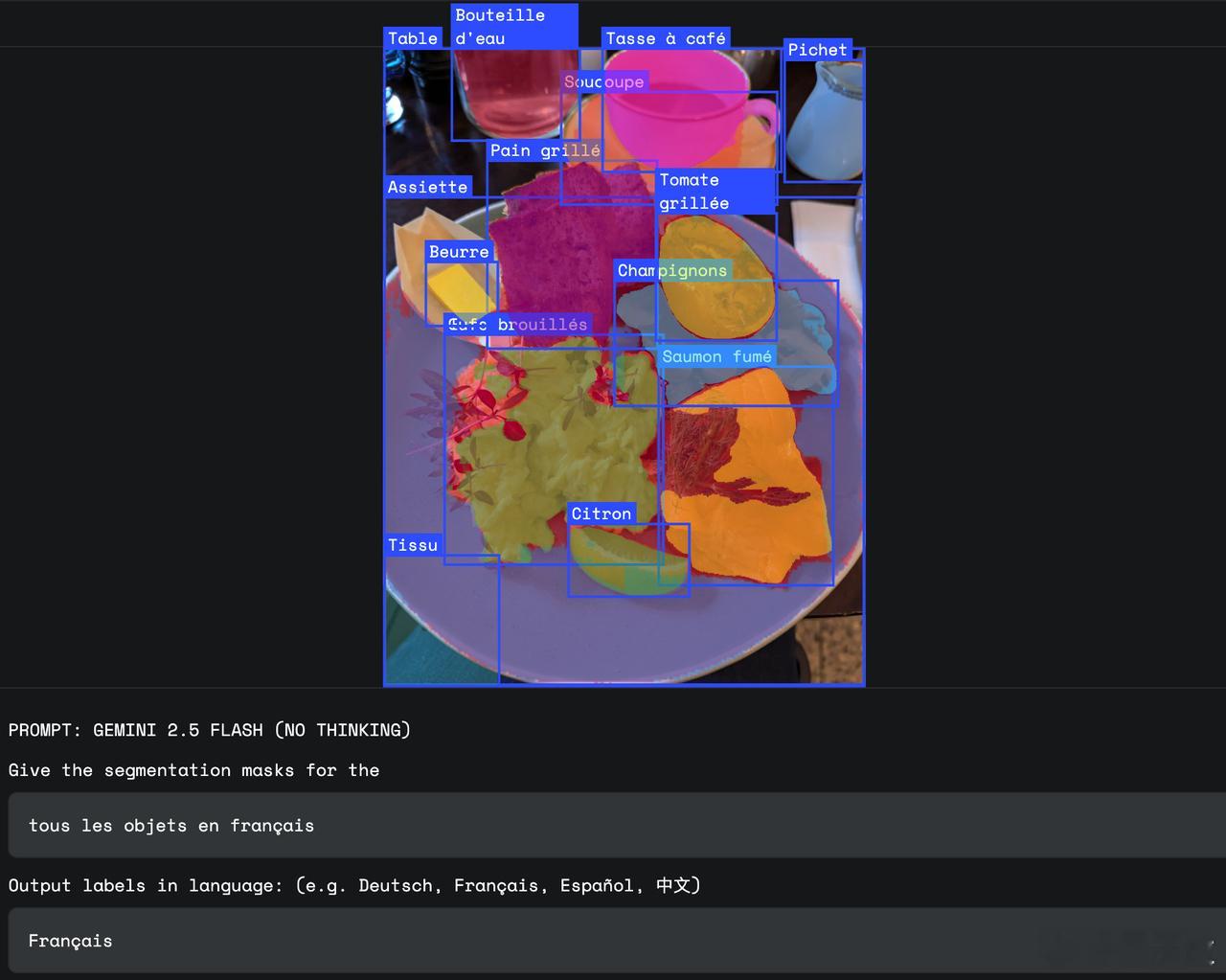
- 【图6】“tous les objets en français”:在法语提示下,将餐盘上的各类食物和物件用法语标注;
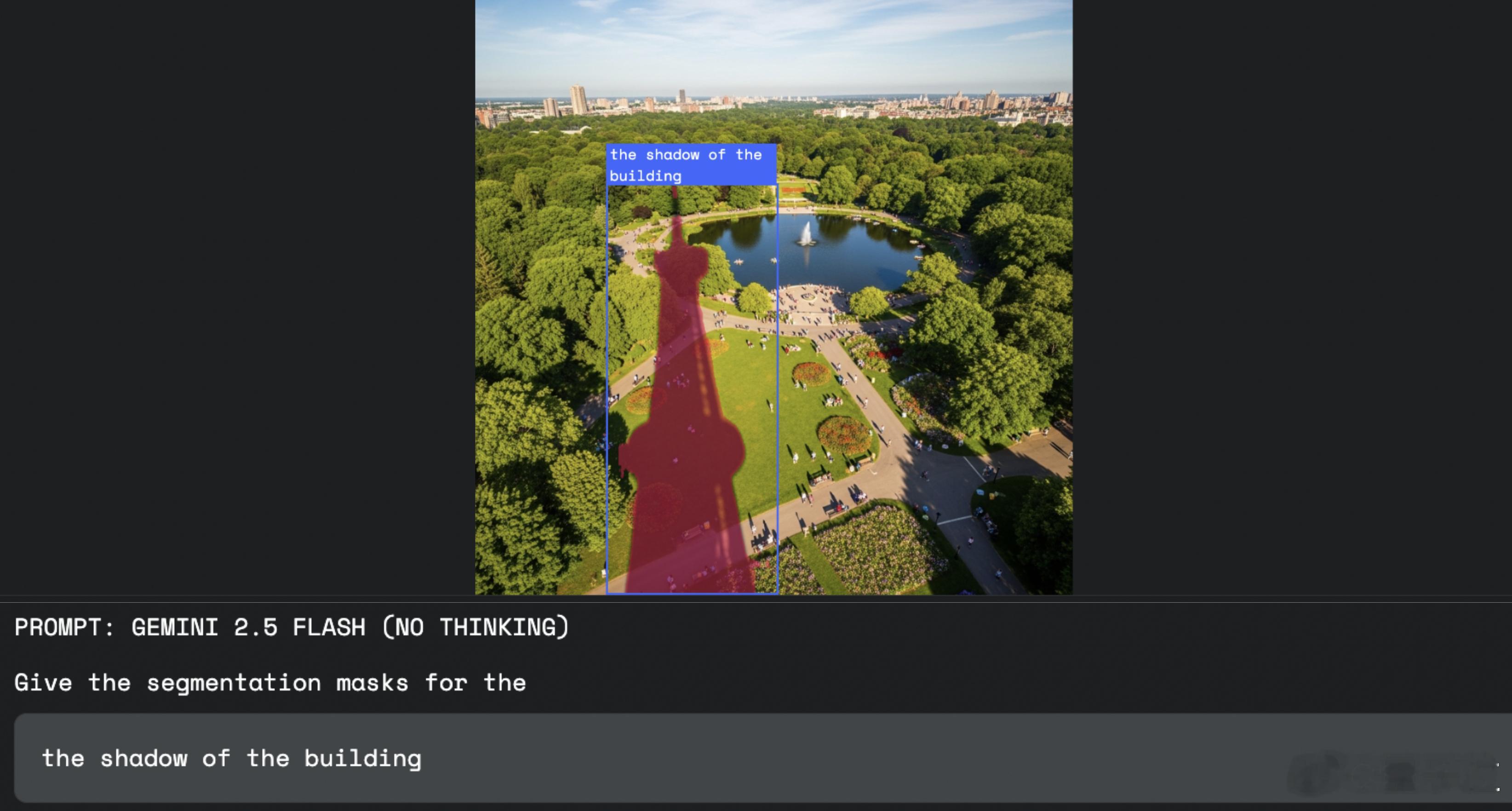
- 【图7】“the shadow of the building”:航拍图中识别出建筑在地面上的完整阴影;
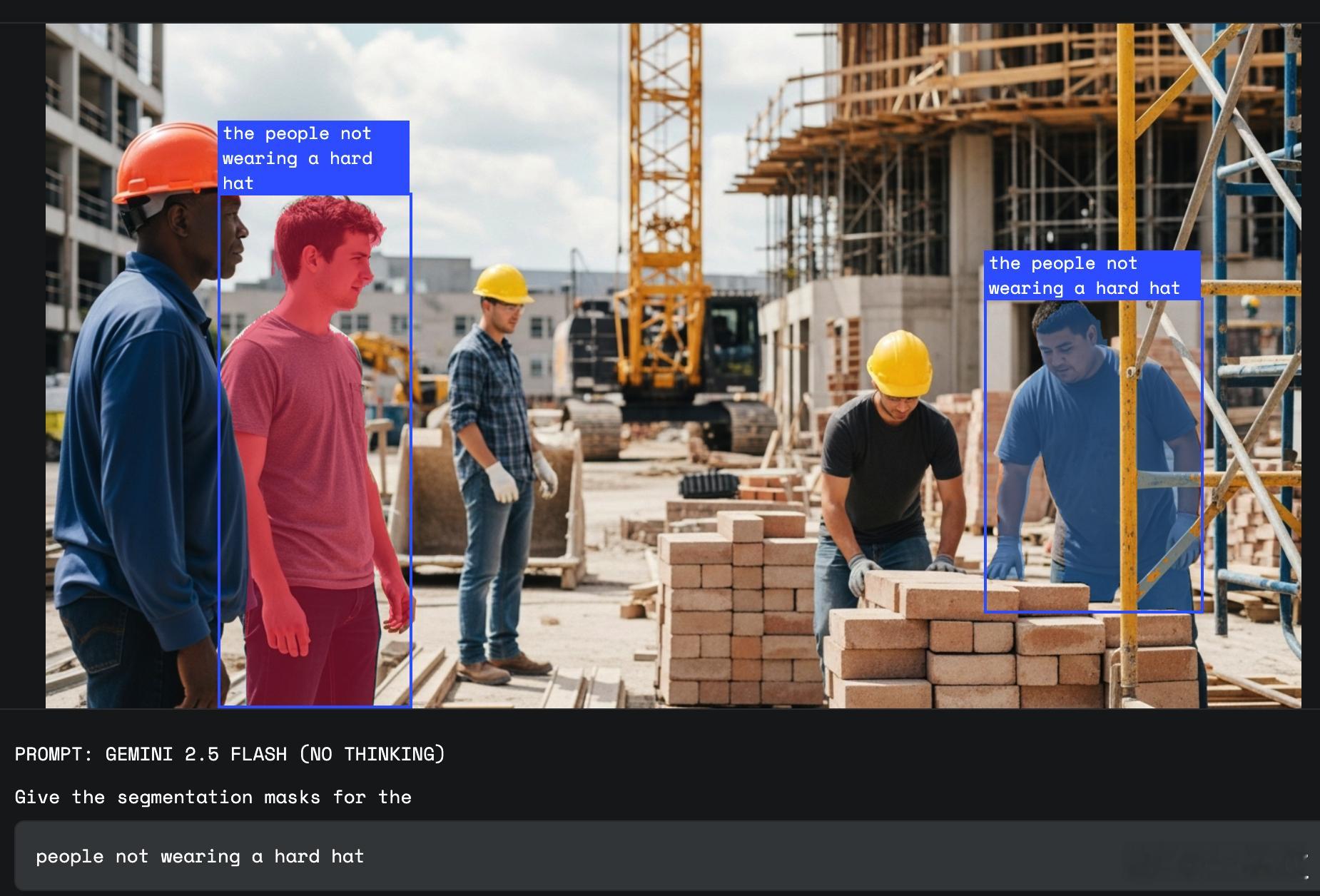
- 【图8】“people not wearing a hard hat”:工地场景中,仅标出未佩戴安全帽的工人;
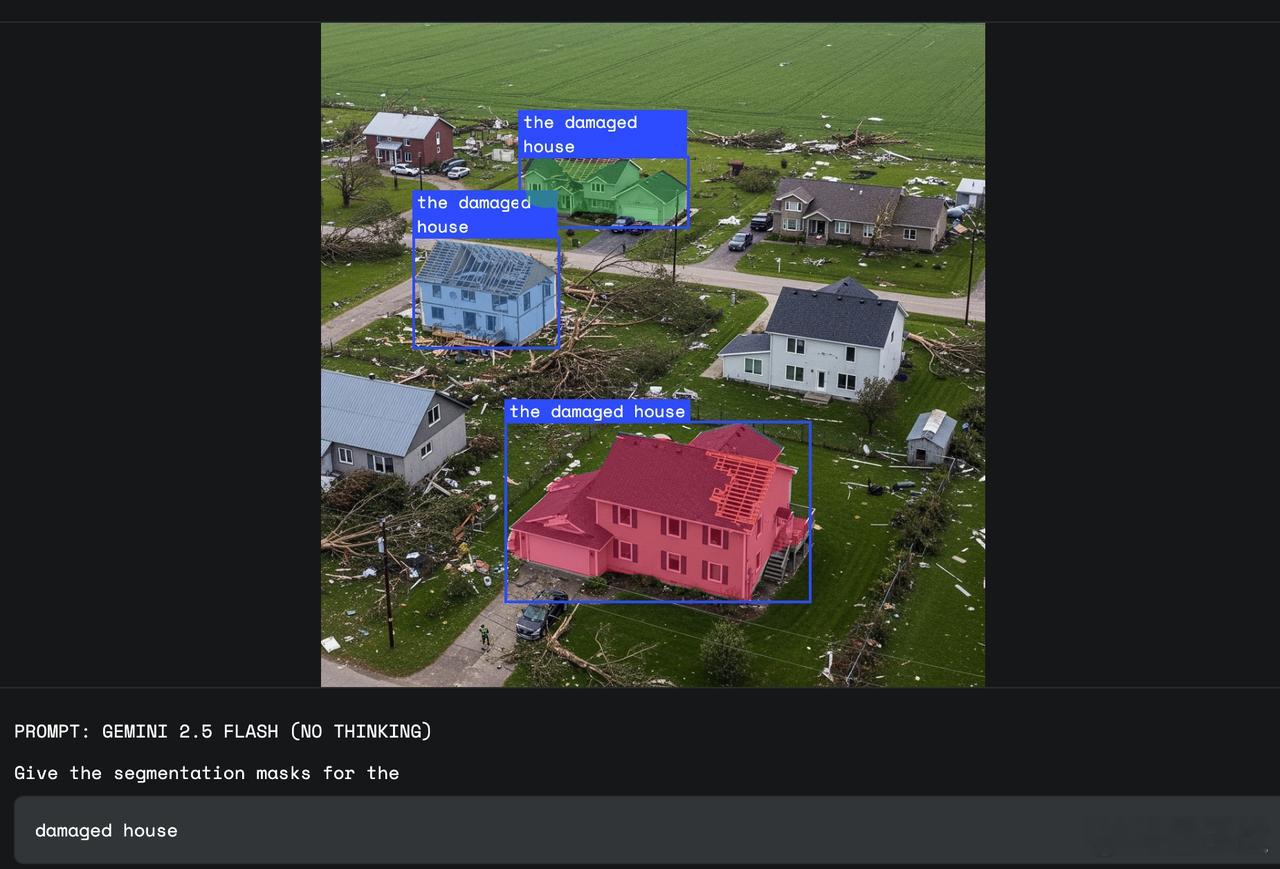
- 【图9】“damaged house”:龙卷风过后的航拍图中,自动分割出受损房屋,而非仅识别建筑物本体。
Gemini 2.5实现的核心突破包括:
关系理解:不仅能识别“一个人”,还能理解更复杂的关系描述,如“举手的人”“第三本书”或“最蔫的花”;
逻辑判断:能够识别否定与条件关系,例如“不在坐着的人”“没戴安全帽的工人”,甚至结合上下文进行过滤和判断;
抽象概念识别:通过世界知识理解“需要清理的地方”“建筑的阴影”“受损的房屋”等抽象或模糊概念在图像中的具体位置;
图像文字识别:当视觉信息不足时,如“开心果口味的甜点”,Gemini可识别图中文字辅助定位;
多语言支持:可理解并回应多种语言提示,如在法语输入下输出法语标注,适用于跨国和多语环境。
这项能力的实际价值包括:
图像编辑更高效:设计师无需手动抠图,仅需语音或文字提示“选中楼的阴影”即可自动操作;
智能安全监测:自动识别“未佩戴安全帽的人”或“存在安全隐患的区域”;
理赔与风险评估自动化:快速识别“被台风破坏的房屋”等关键视觉信息。
该功能目前支持Web端(Google AI Studio)和API调用,开发者可查阅Gemini API文档了解使用方法。