一文介绍八种主流开源模型架构开源模型架构设计一览
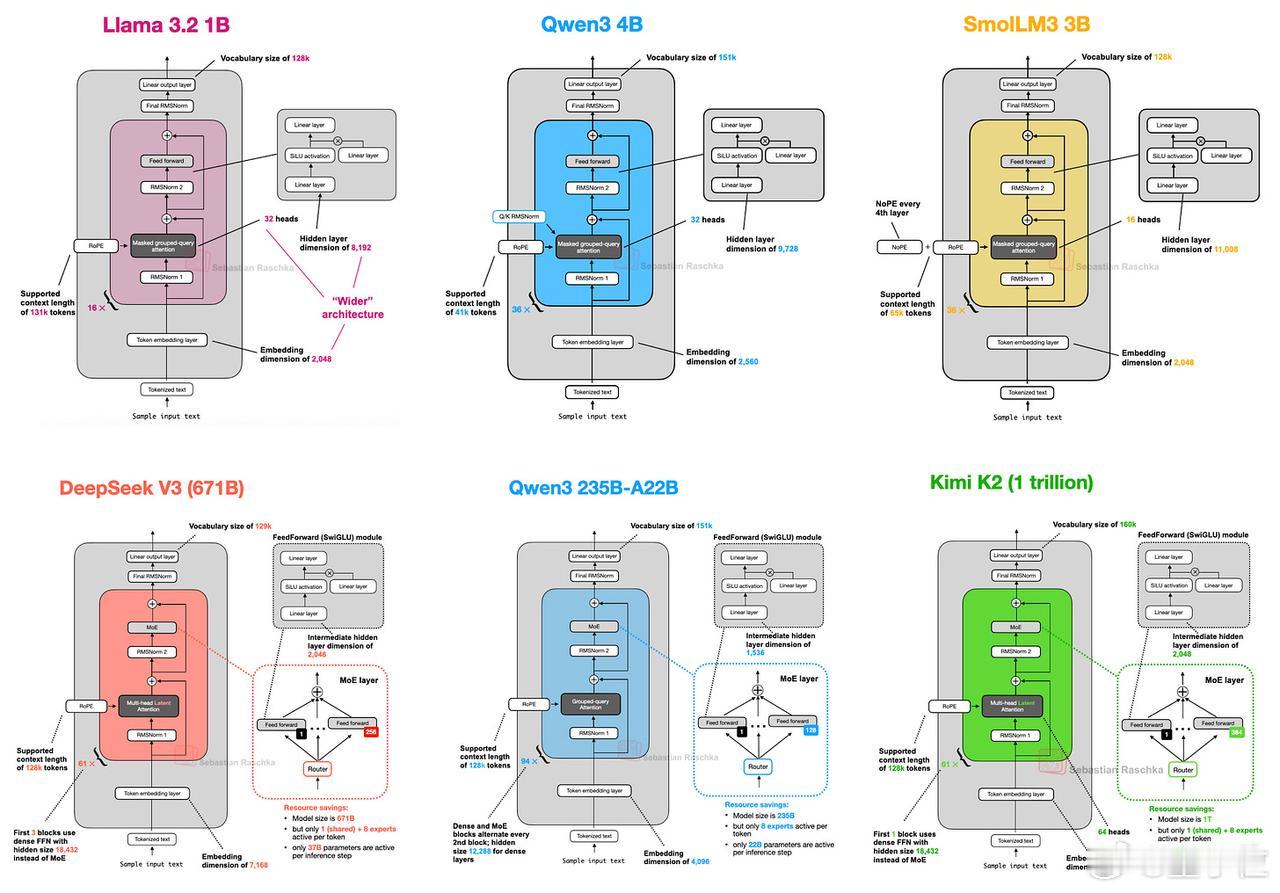
从GPT到MoE,知名科技博主Sebastian Raschka对当前顶尖开源模型的架构设计进行了总结。【图1】
在这篇博客当中,Sebastian没有讨论常见的基准测试表现或训练算法,把目光聚焦在开源模型的核心架构创新。
文章非常全面,量子位节选了部分亮点,欢迎观看:
一、DeepSeek V3/R1
DeepSeek V3具有两项革新的架构设计:多头潜在注意力(MLA)与混合专家(MoE)系统,显著提升了模型计算效能。
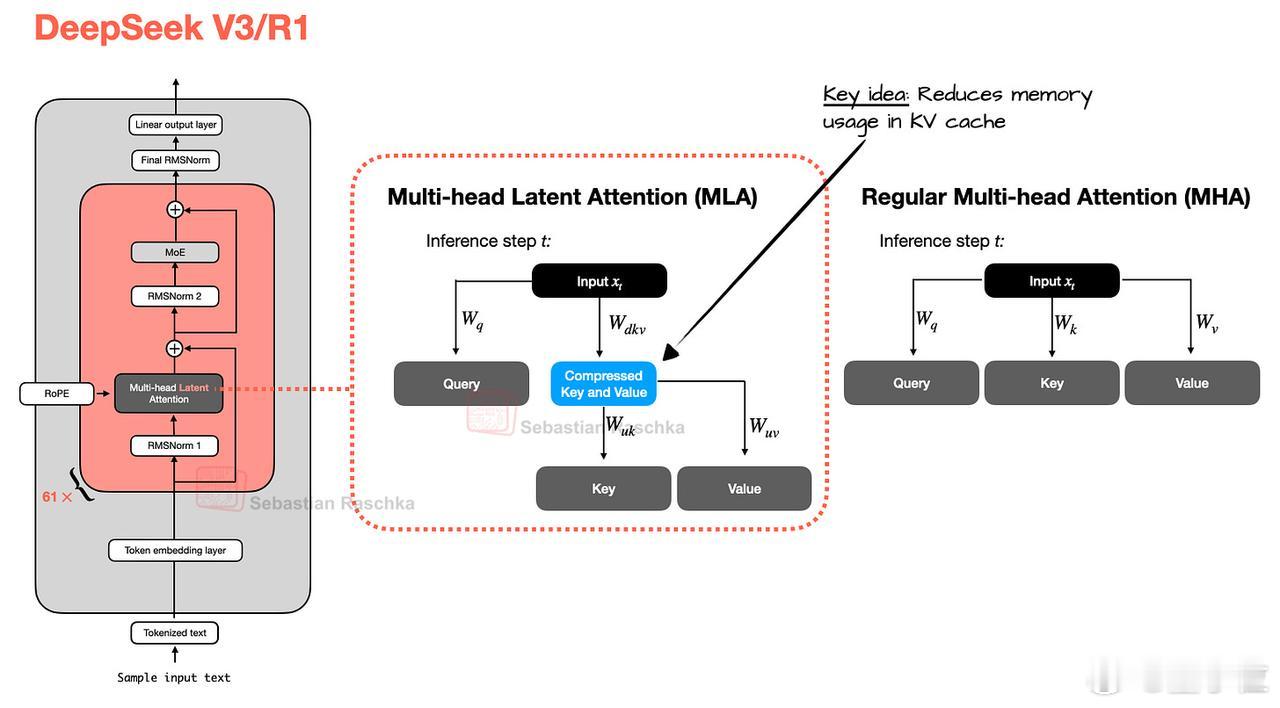
- 多头潜在注意力(MLA)
与GQA(分组查询注意力)共享键值头的做法不同,MLA会将键值张量压缩至低维空间后再存入KV缓存。
在推理过程中,这些压缩后的张量会先通过矩阵乘运算还原至原始维度,再参与注意力计算。虽然这会增加一次额外的矩阵乘法操作,但显著降低了内存占用。【图2】
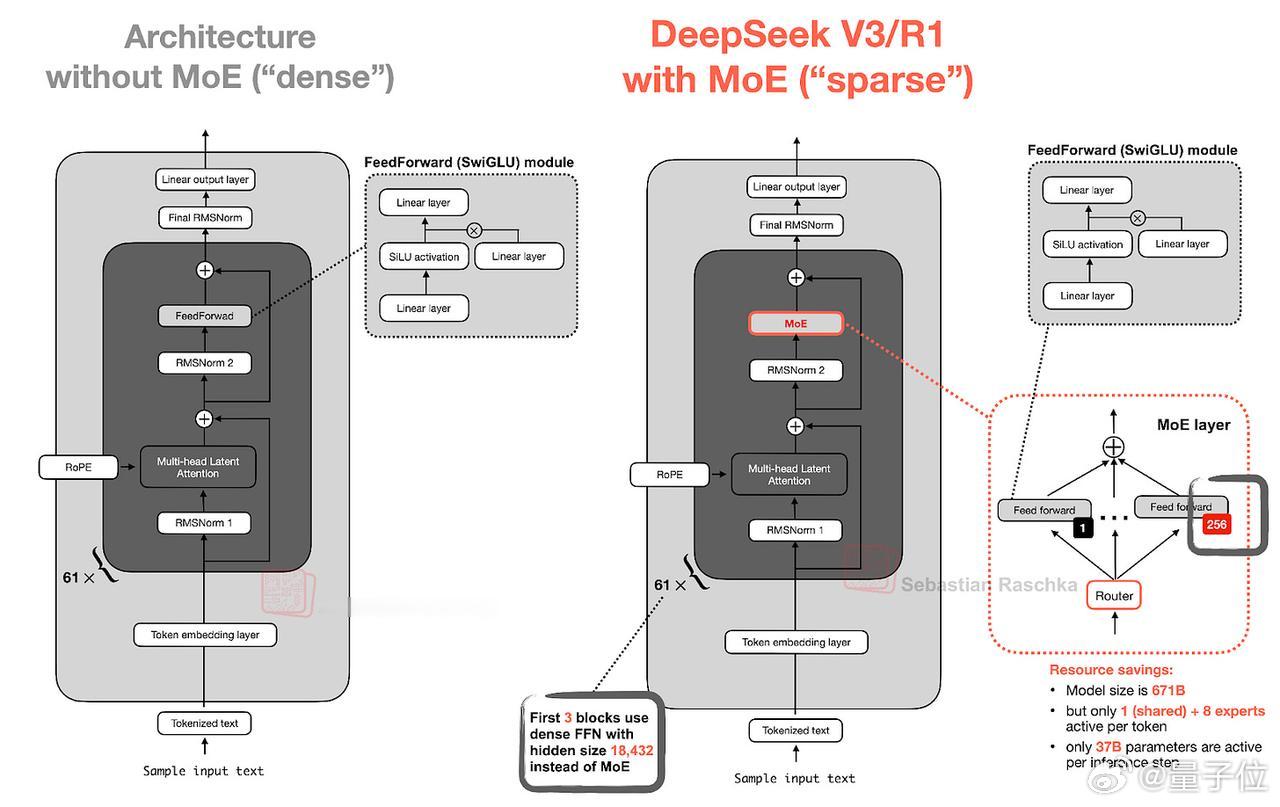
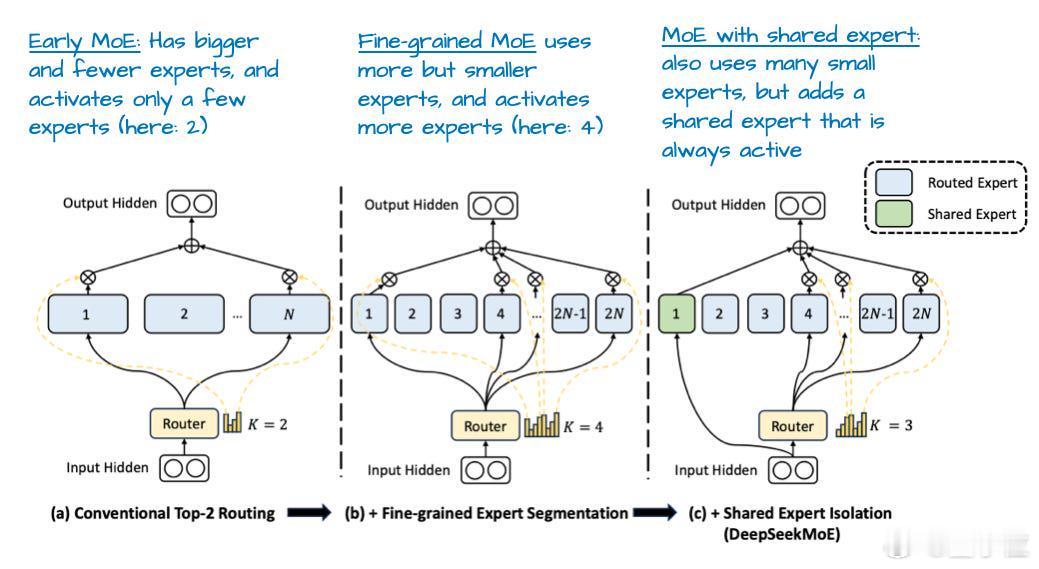
- 混合专家(MoE)
混合专家的核心设计理念在于,将Transformer模块中的每个前馈网络替换为多个专家层。【图3】
V3每个MoE模块包含256个专家,但在实际推理时,每次仅激活9个专家。V3采用始终激活的共享专家机制。该专家会对每个输入token都进行处理。【图4】
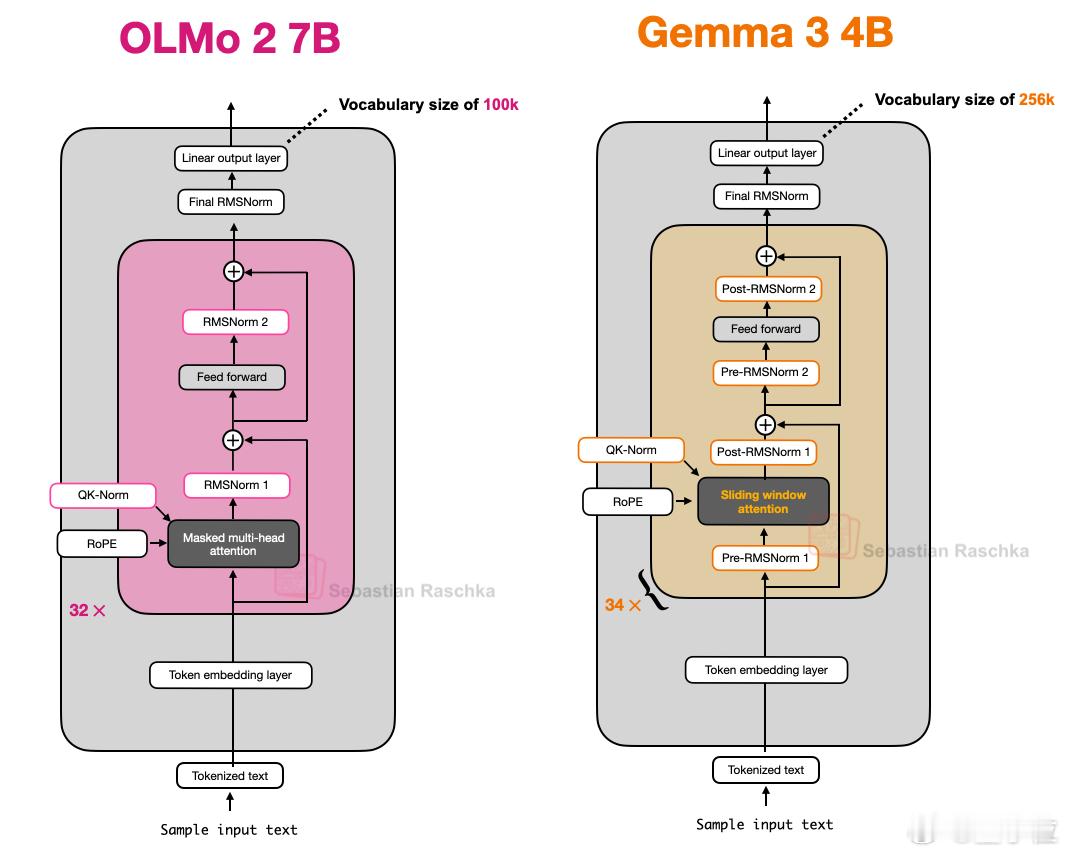
二、Gemma 3
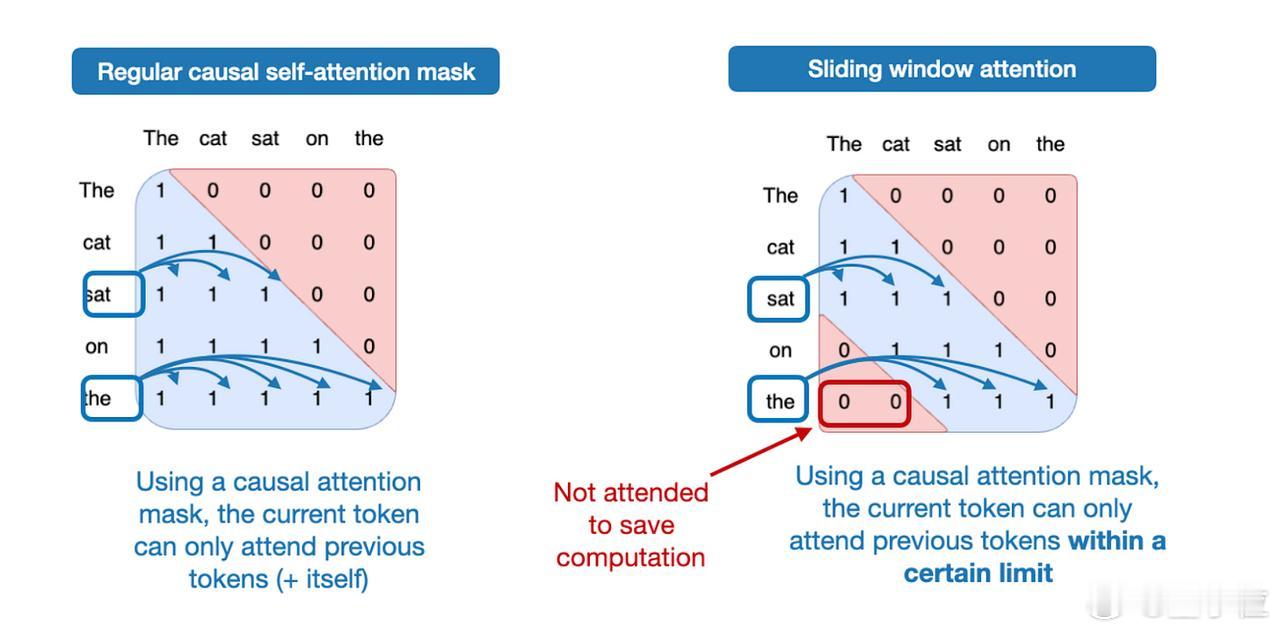
- 滑动窗口注意力机制
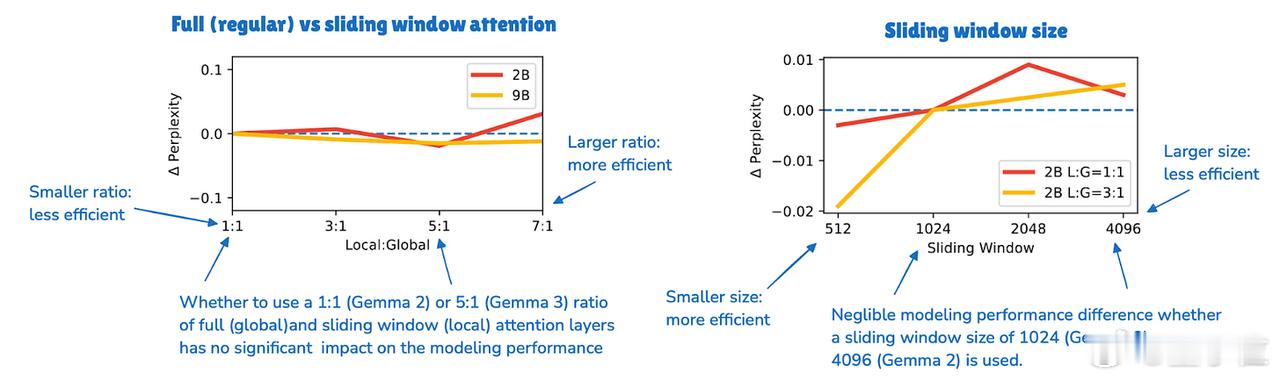
该机制本质是一种局部注意力:与传统全局自注意力(每个序列元素可关注所有其他元素)不同,滑动窗口注意力将上下文范围限制在当前查询位置周边区域。【图5】
Gemma 3采用每5层滑动窗口注意力配1层全局注意力的比例,并将窗口大小从4096压缩至1024,使模型更专注于高效的区域化计算。【图6】
- 归一化层布局设计
Gemma 3在其分组查询注意力模块中同时采用了前置归一化(Pre-Norm)和后置归一化(Post-Norm)的RMSNorm方案。【图7】
从技术角度看,这种混合布局兼具两种归一化的优势:前置归一化有利于训练稳定性,后置归一化则保留原始Transformer的特性。
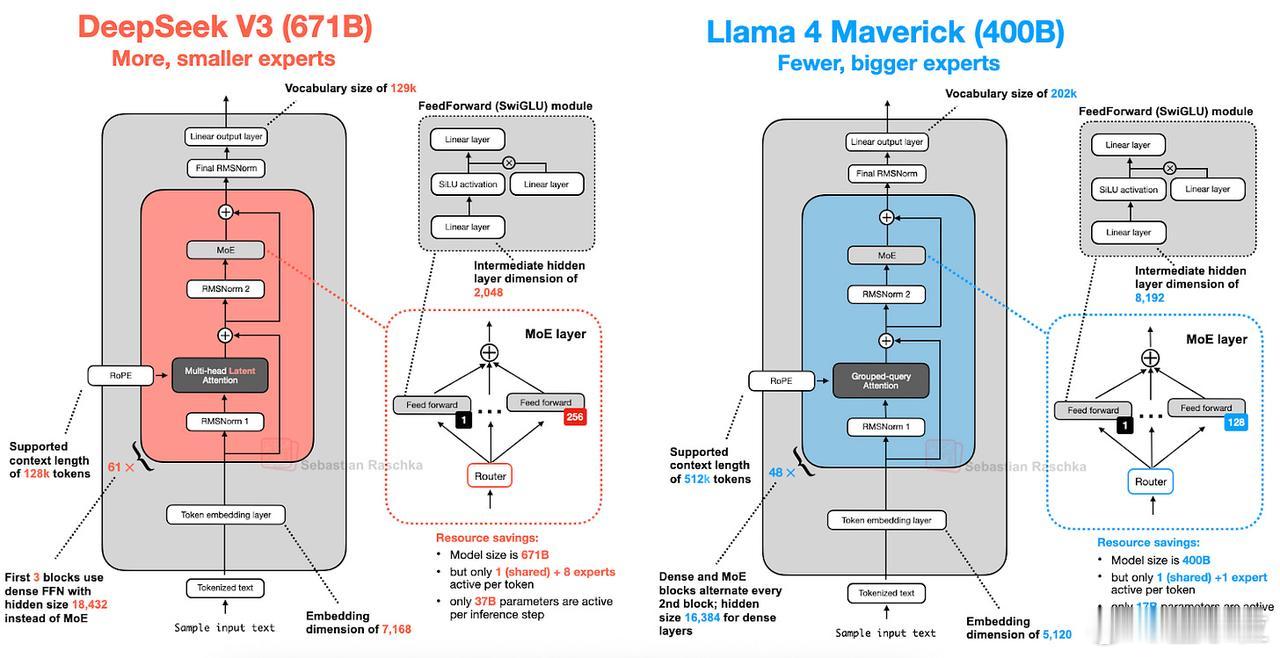
三、Llama 4
Llama 4 Maverick同样采用了MoE架构,其余部分则延续了相对标准的设计范式,这一点与DeepSeek-V3高度相似。【图8】
Maverick使用分组查询注意力,MoE配置比较传统,专家数量较少但规模更大(2个活跃专家,每个专家8192维隐藏层)。
相比DeepSeek几乎在每个Transformer块(前3层除外)都集成了MoE层,Llama 4每隔一个Transformer块轮换使用MoE层和标准稠密模块。
四、Qwen3
- Qwen3 (Dense)
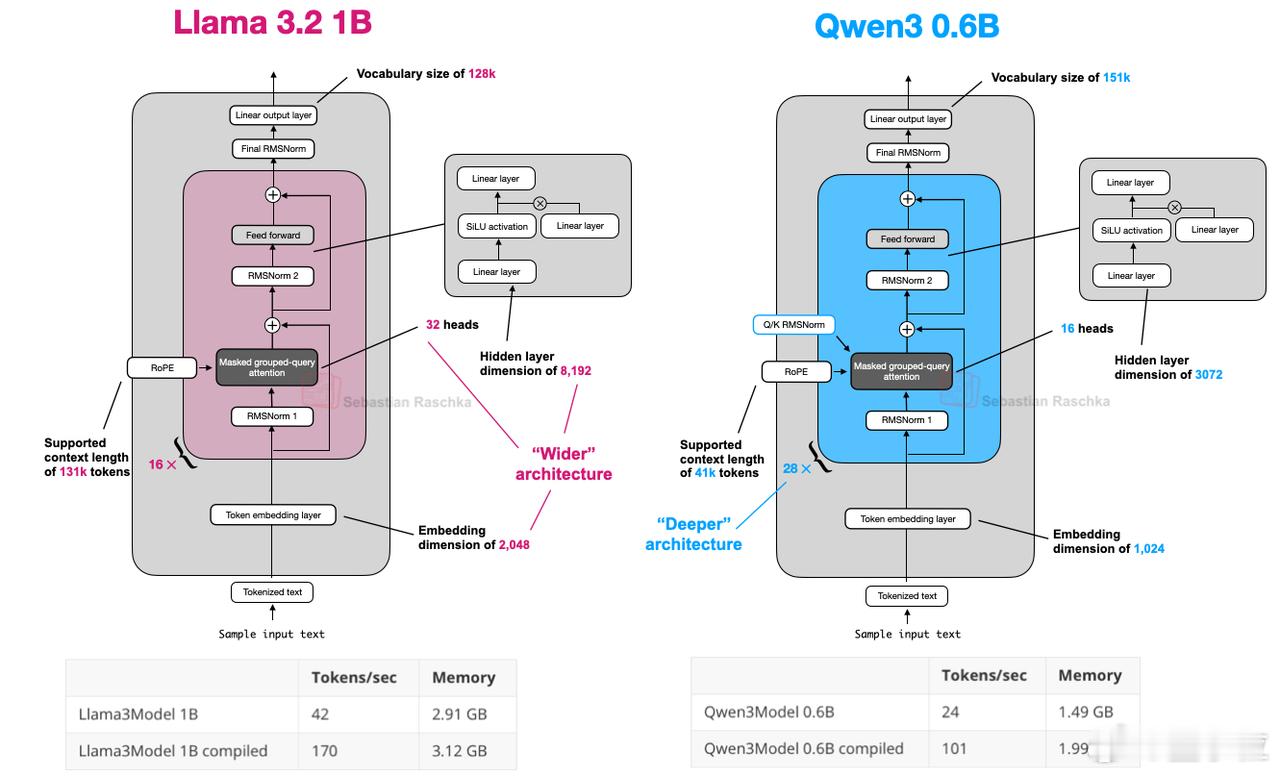
相比Llama 3 1B,Qwen3采用更深层架构,Transformer层数更多;而Llama 3则采用更宽架构,注意力头数更多。【图9】
Qwen3整体架构更精简,隐藏层维度更小、注意力头数更少,内存需求更低。但由于Transformer块数量更多,Qwen3的运行时延更高。
- Qwen3 (MoE)
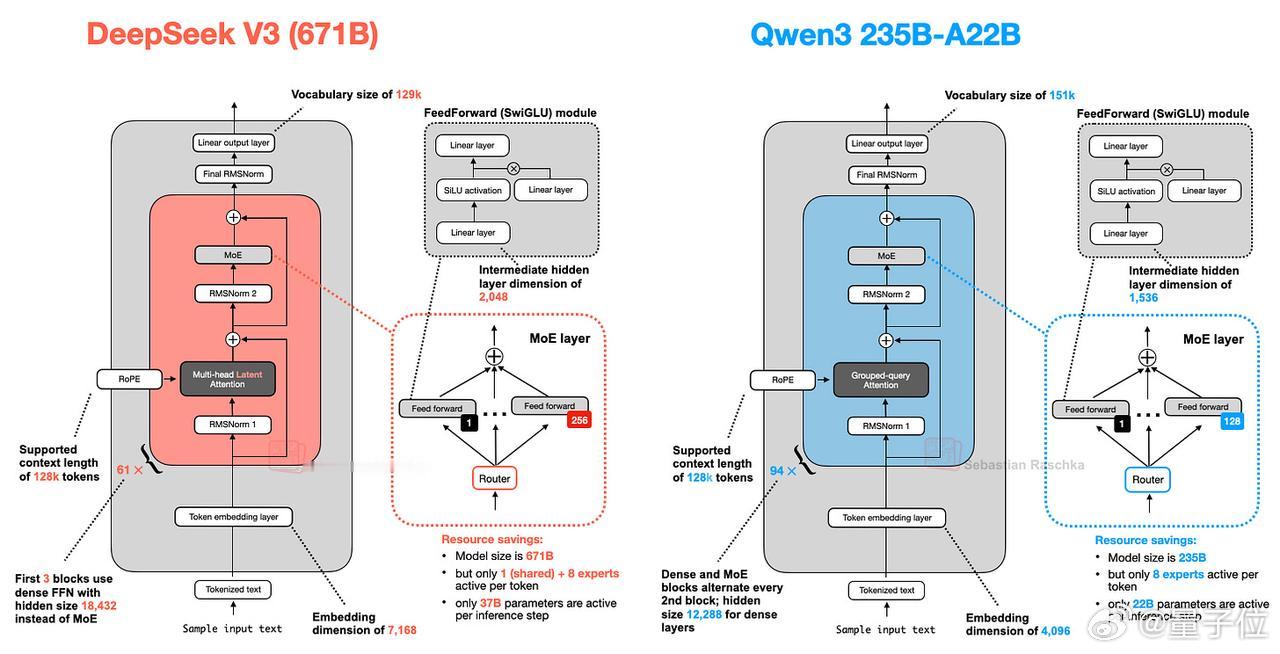
DeepSeek-V3的激活参数几乎是Qwen3的两倍(37B)。从图中可以看出,DeepSeek-V3和Qwen3 235B-A22B的架构非常相似。但值得注意的是,Qwen3没有使用共享专家机制。【图10】
五、Kimi 2
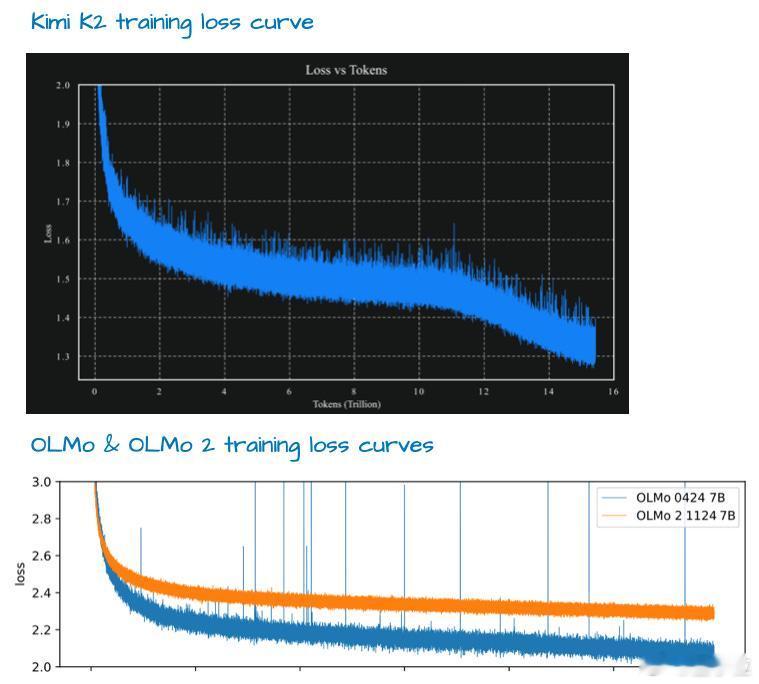
该模型采用了相对较新的Muon优化器变体而非AdamW,这使得训练损失曲线非常漂亮。【图11】
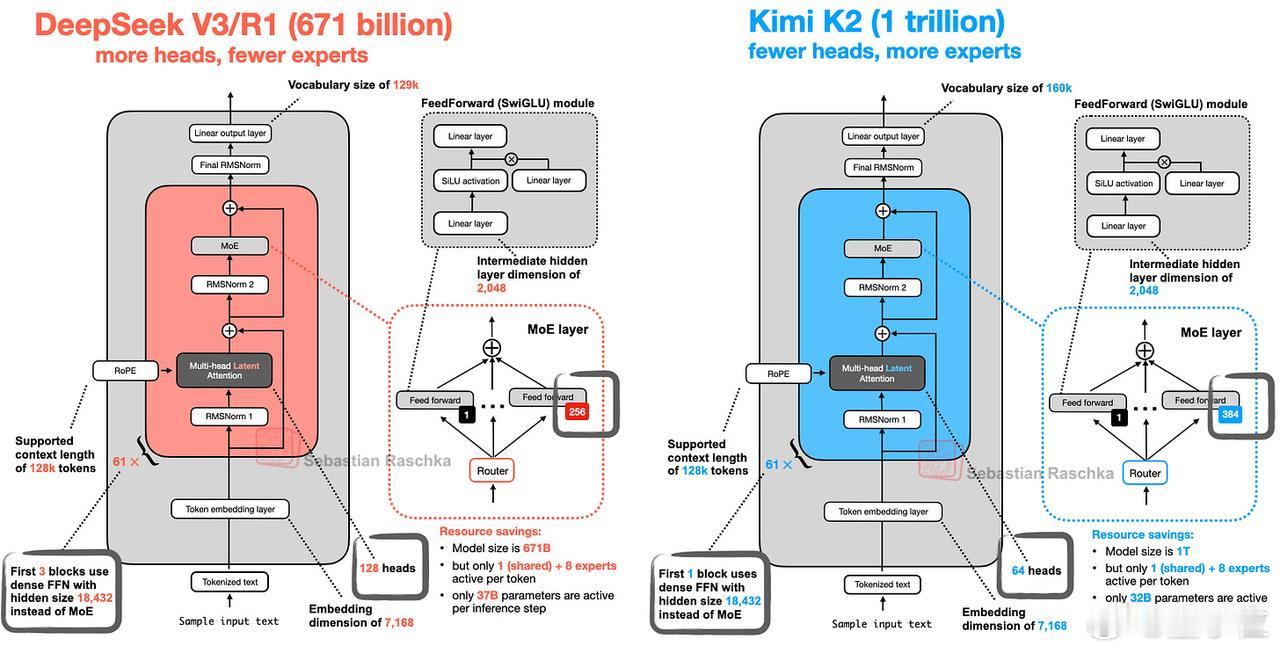
Kimi 2采用的正是本文开头介绍过的DeepSeek-V3架构,只是规模更大。主要区别在于:1. MoE模块中使用了更多专家;2. 多头潜在注意力(MLA)模块中的注意力头数有所减少。【图12】
这种架构微调既保留了原始设计的优势,又通过专家数量扩展提升了模型容量。
受限于篇幅,仅摘录部分内容,点击链接可查看完整博客: