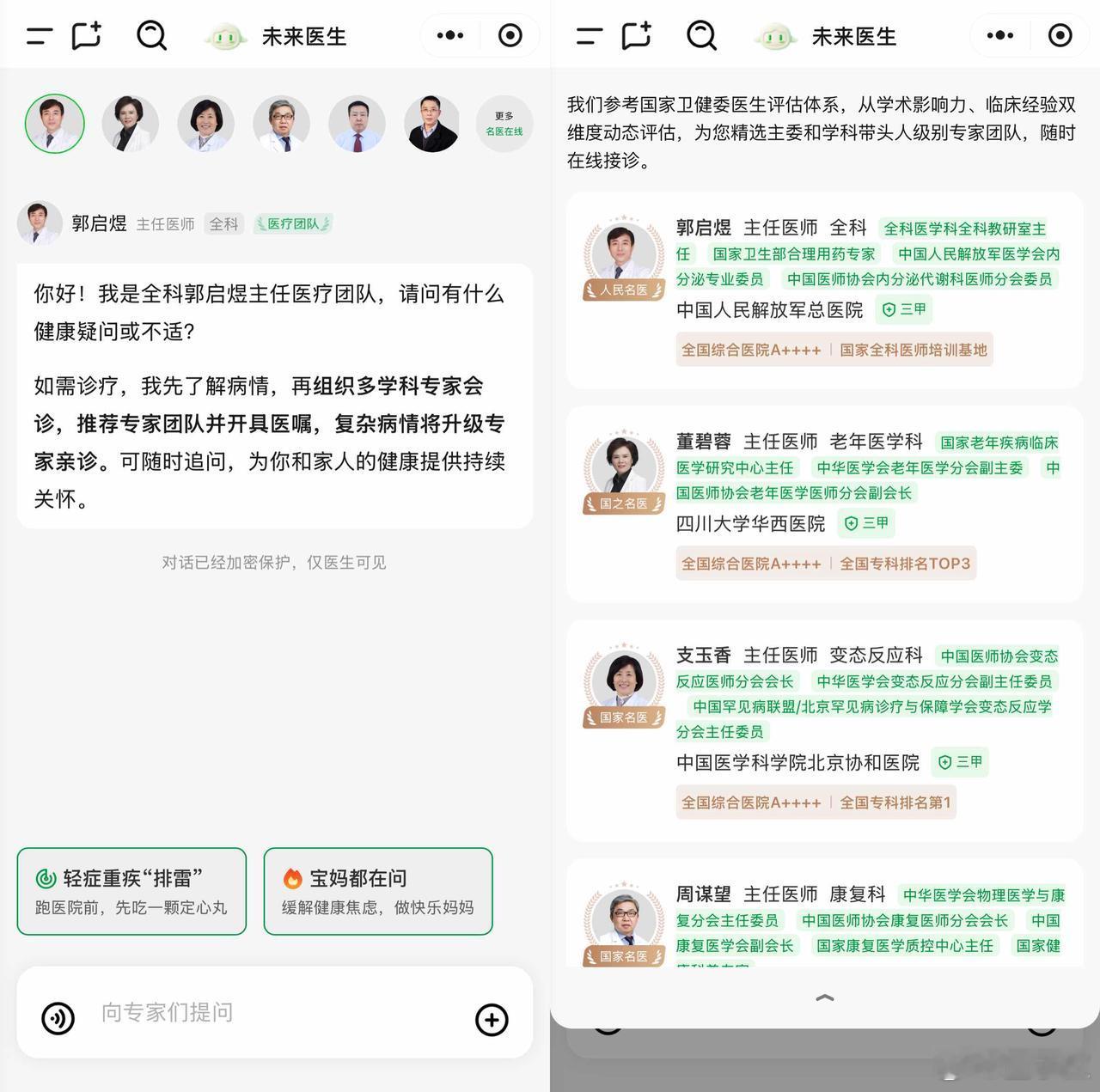
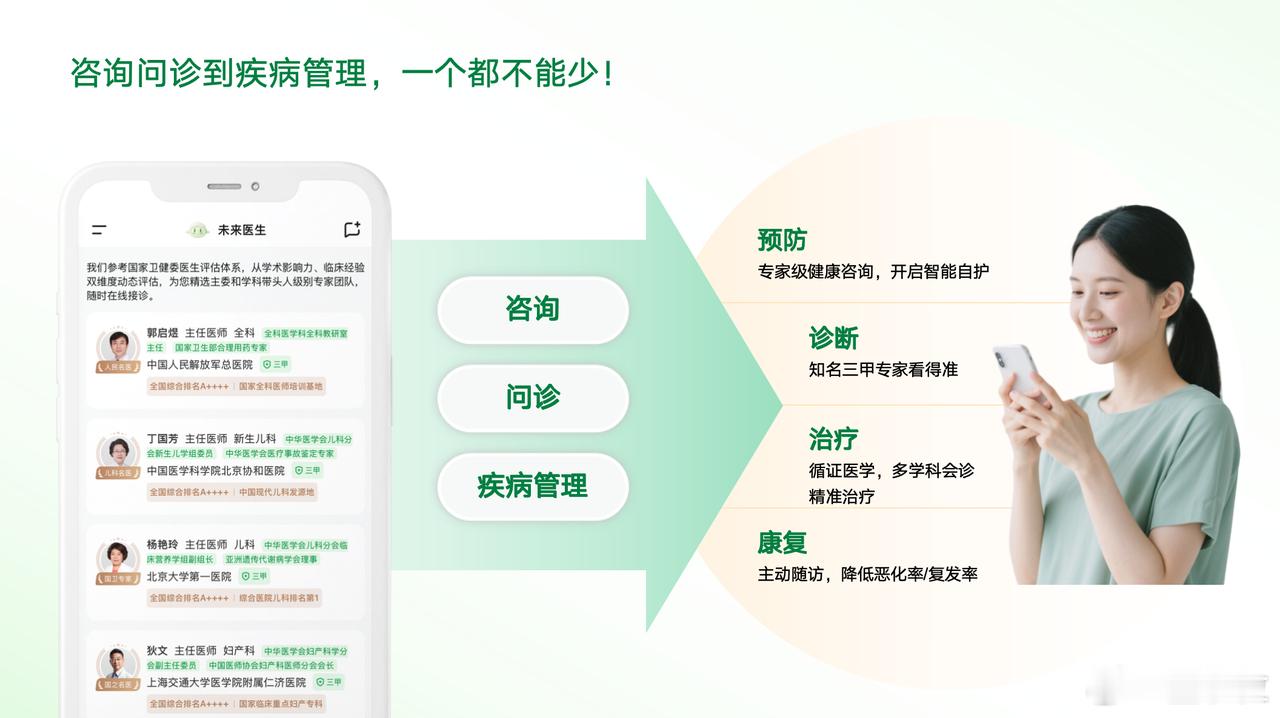
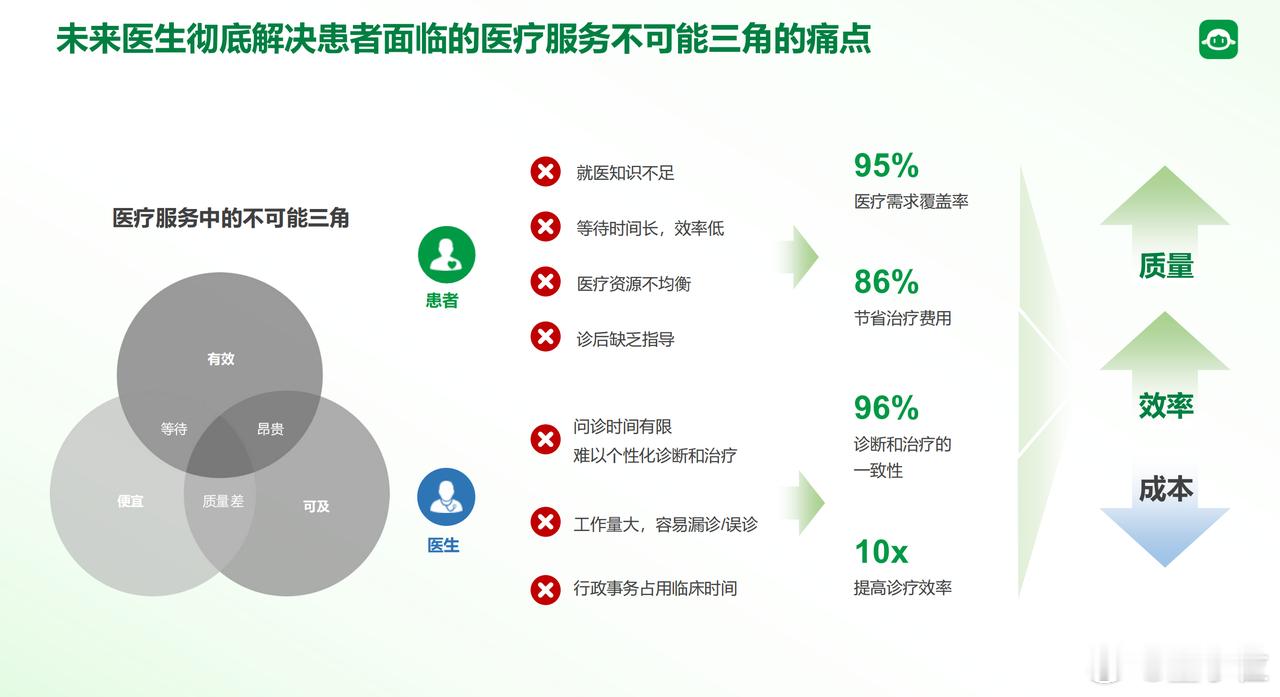
“我最近喉咙像刀割一样痛,还伴随鼻塞,但没有咳嗽……这是染上流感,还是又中招了?”上面这个场景,已逐渐成为大众与AI互动的日常之一。但这背后隐藏的是医疗AI真实能力与临床期待之间的落差,北京协和医院胸外科主任医师梁乃新表示,虽然不时传出“AI在xx执业医师考试中拿下高分”的新闻,但现实并不尽如人意。为了解决这个评估落差,中国23家医院的临床专家共同制定了一套全球首个医疗AI临床适用性标准:CSEDB(Clinical Safety-Effectiveness Dual-Track Benchmark)。它不再用答题正确率来衡量AI,而是聚焦两个核心维度:- 安全性:比如有没有识别高风险药物相互作用、会不会忽视致命并发症、能否避免禁忌用药。- 有效性:诊断合不合理,方案有没有参考指南,是否充分考虑个体病史。整个评估体系共2069个真实临床推演问答,覆盖26个专科和30个核心指标。每一个错误根据临床风险被打分,最高5分代表“潜在致命后果”,把评分和病人结果直接挂钩。在这次严格的评估中,一个由中国团队打造的大模型MedGPT,以总分0.895位列第一,是唯一一个“安全性得分 > 有效性”的模型,击败了OpenAI的o3、Gemini-2.5、Claude-3.7等一众海外大厂。更有价值的是,这个模型不仅会“说得像医生”,还正在“像医生一样思考”。基于MedGPT的技术能力,背后团队推出了“未来医生”平台,核心理念是人机协作:医生可以把部分流程交给AI自动完成,AI则通过解释推理让医生随时介入,最终所有建议由医生签字审核。平台现已引入50多位中华医学会主委级专家参与服务和模型训练,高水平医生的知识、沟通和流程设计被AI结构化吸收,从而释放出规模化的经验。用团队的话说,是把医生变成拥有三头六臂的超人。而CSEDB这套标准也将全球开放,任何医疗AI团队都可以用它做测评优化,这是整个行业的一次基础设施升级。过去我们说大模型答题能力很强,但医生的世界不只考选择题。这次,标准与落地之间,终于有了一座桥,而构桥的是中国团队。