Nature子刊:大模型临床推理能力的量化!
11月6日,发表在Nature Communications上的一篇新论文,研究人员探讨了量化大模型在临床案例中的推理能力。
近年来,推理增强型大型语言模型在多个领域展现出卓越能力,但其在临床医学这一高风险、高复杂性领域的应用潜力尚未得到充分评估。现有医学基准测试多聚焦于模型输出的最终准确性,而缺乏对推理过程质量的系统性量化分析。
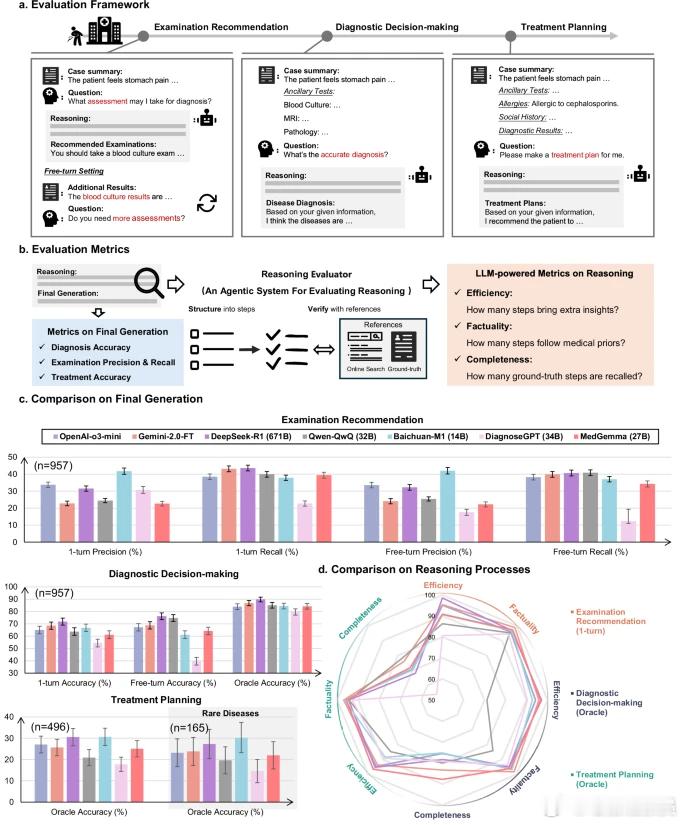
为填补这一空白,研究人员提出了MedR-Bench评估框架,该数据集包含1453个源自真实临床病例报告的结构化案例,覆盖13个身体系统和10个医学专科,兼顾常见病与罕见病。
该基准测试模拟临床诊疗全流程,在患者管理的三个关键阶段对模型进行评估:检查建议阶段模拟初诊场景,要求模型推荐实验室或影像学检查;诊断决策阶段基于收集信息进行判断;治疗计划阶段则制定相应治疗方案。
为客观评估推理质量,研究人员还开发了基于大模型的推理评估器,从效率、事实准确性和完整性三个维度对模型的自由文本推理进行自动化评分。
通过对七种前沿推理大模型的测试发现,当检查结果充分时,模型在诊断任务中的准确率超过85%,但在检查建议和治疗规划方面表现有所下降。尽管模型生成的内容通常具备事实准确性,但其推理过程往往缺失关键步骤,影响临床实用性。
值得注意的是,开源模型如DeepSeek-R1与专有模型之间的性能差距正在缩小,这为开发更普惠的临床人工智能工具带来了希望。
这项研究通过构建贴近真实临床场景的评估体系,揭示了当前大模型在医疗推理中的优势与局限。所有数据集、代码及评估流程均已开源,旨在推动临床推理大模型的透明化发展与持续改进。
热门微博 科技快讯 ai医疗 人工智能