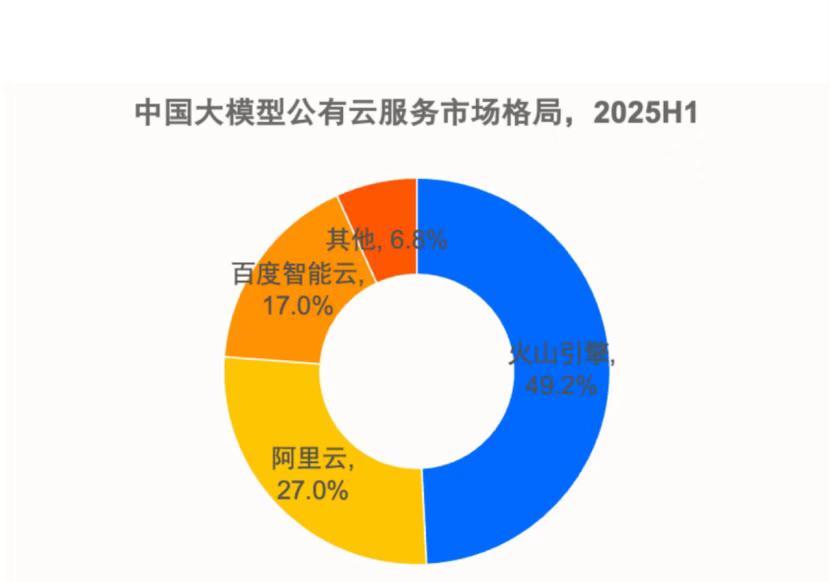
DeepSeek创始人梁文峰再次语出惊人!他说:“我们经常说中国AI和美国有一两年差距,但真实的差距是原创和模仿之差。如果这个不改变,中国永远只能是追随者,所以有些探索也是逃不掉的。” 梁文峰这话听着扎心,却没半点虚的——他敢把“原创差”这层窗户纸捅破,是因为自己亲身踩过中美AI发展的“温差”。你可能不知道,他早年在谷歌DeepMind待过5年,跟着团队参与过AlphaGo后续的强化学习算法优化,那段经历让他看清了两国AI的核心分野:美国团队敢花两年时间死磕一个“看不到即时回报”的底层算法,而国内当时不少团队,还在盯着“人脸识别变现”“推荐算法优化”这类应用层生意。他后来在内部分享里说过,“那时候国内谈AI,先问‘能不能赚钱’,美国谈AI,先问‘能不能突破认知边界’,这两种思路的差距,比技术本身大得多。” 回国创立DeepSeek时,他没走“跟风路”。2022年大模型热潮刚起,投资人都劝他“先做个类似ChatGPT的产品抢占市场”,他却把融资来的80%资金砸进了“数学推理大模型”的底层研发。要知道,数学推理是AI原创能力的硬指标——不像生成文案能靠数据堆砌,数学题需要模型理解逻辑、自主推导,当时国内没几家企业愿意碰。团队熬了11个月,才让DeepSeek-Math在国际数学竞赛数据集上追上GPT-4,有员工吐槽“这钱花得比烧纸还快”,梁文峰却反问“不啃硬骨头,难道永远靠微调别人的模型过日子?” 他说的“模仿困境”,在行业里其实随处可见。比如前两年国内扎堆出“中国版ChatGPT”,细看底层架构,大多是在开源的LLaMA模型上做微调,换了个中文界面就敢叫“自主研发”;再看AI算力,咱们依赖的A100、H100芯片是美国的,常用的TensorFlow、PyTorch框架也是美国的,就像盖房子,地基和钢筋都靠借,再漂亮的外墙也扛不住风险。梁文峰在一次行业论坛上举过个例子:“有次国内某大厂展示‘AI自主研发成果’,结果代码里还留着OpenAI的底层函数注释,这哪是创新?顶多算‘精装修’。” 更戳人的是,他自己吃过“模仿”的亏。早年他刚回国时,曾尝试在现有开源模型基础上做优化,想快速推出产品,结果上线后发现,模型遇到“没见过的新场景”就会出错——比如给它一个没收录过的数学公式,它会胡编推导过程。那次教训让他彻底醒悟:“模仿就像抄作业,就算抄得再像,换个题型还是不会。中国AI要想不被卡脖子,就得自己学会‘出题’。”现在DeepSeek的核心团队里,有近40%的人在做“非应用层”的基础研究,甚至专门设了“算法探索岗”,允许研究员花半年时间研究“暂时没用”的技术,这在追求短期回报的国内AI圈,算是个“异类”。 说白了,梁文峰的“惊人之语”不是唱衰,是敲警钟。咱们总说“中国AI用户规模大、数据多”,可这些优势如果只用来做应用层的“锦上添花”,不往底层原创挖深,永远只能跟在美国后面跑。就像他常说的,“一两年的技术差距能靠加班补上,但原创思维的差距,得靠一代人心态的转变——敢慢下来,敢做‘无用功’,才有可能真的超车。” 各位读者你们怎么看?欢迎在评论区讨论。