[LG]《Compute as Teacher: Turning Inference Compute Into Reference-Free Supervision》D Jayalath, S Goel, T Foster, P Jain... [Meta Superintelligence Labs] (2025)
Compute as Teacher (CaT):用推理计算成就无参考监督的新范式
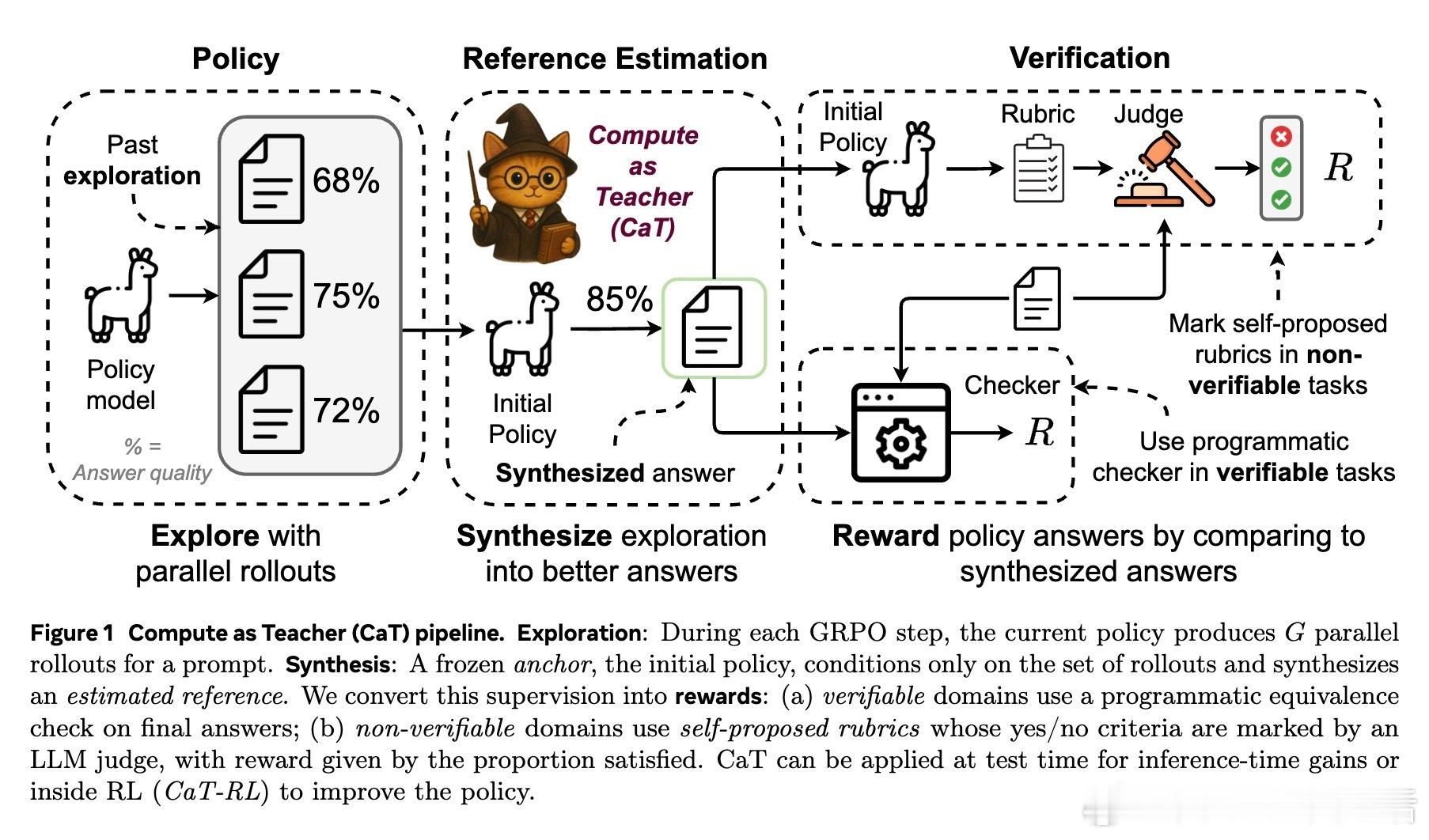
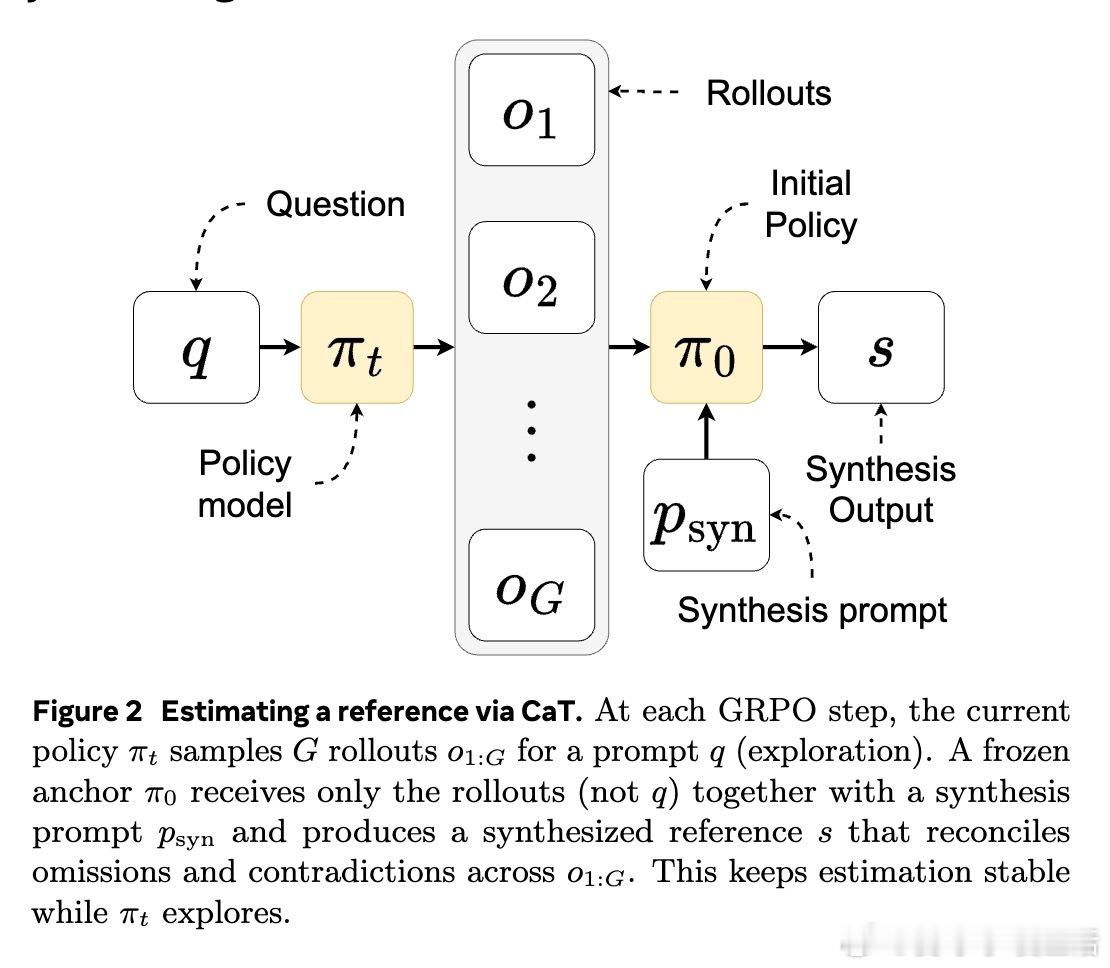
• CaT 利用模型推理时的并行多条生成(rollouts),由一个固定不变的初始策略(anchor)合成出一个“估计参考答案”,将额外推理计算转化为监督信号,无需人工标注或明确参考答案。
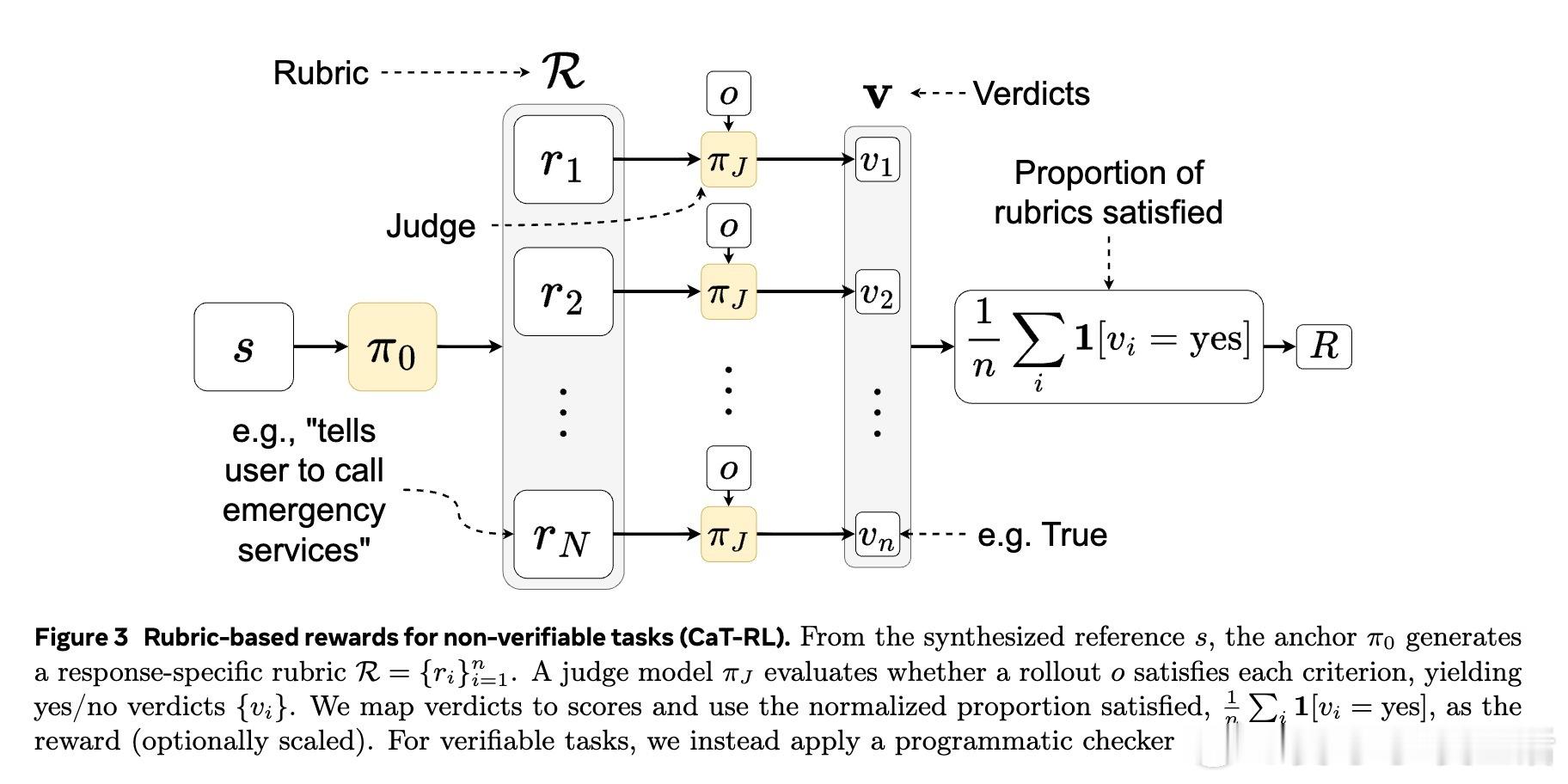
• 在可验证任务(如数学题)中,通过程序化的答案等价性检查给予奖励;在不可验证任务(如自由对话、医疗咨询)中,模型自拟细化的二元评分标准(rubrics),由另一独立大模型进行判定,奖励为满足标准的比例。
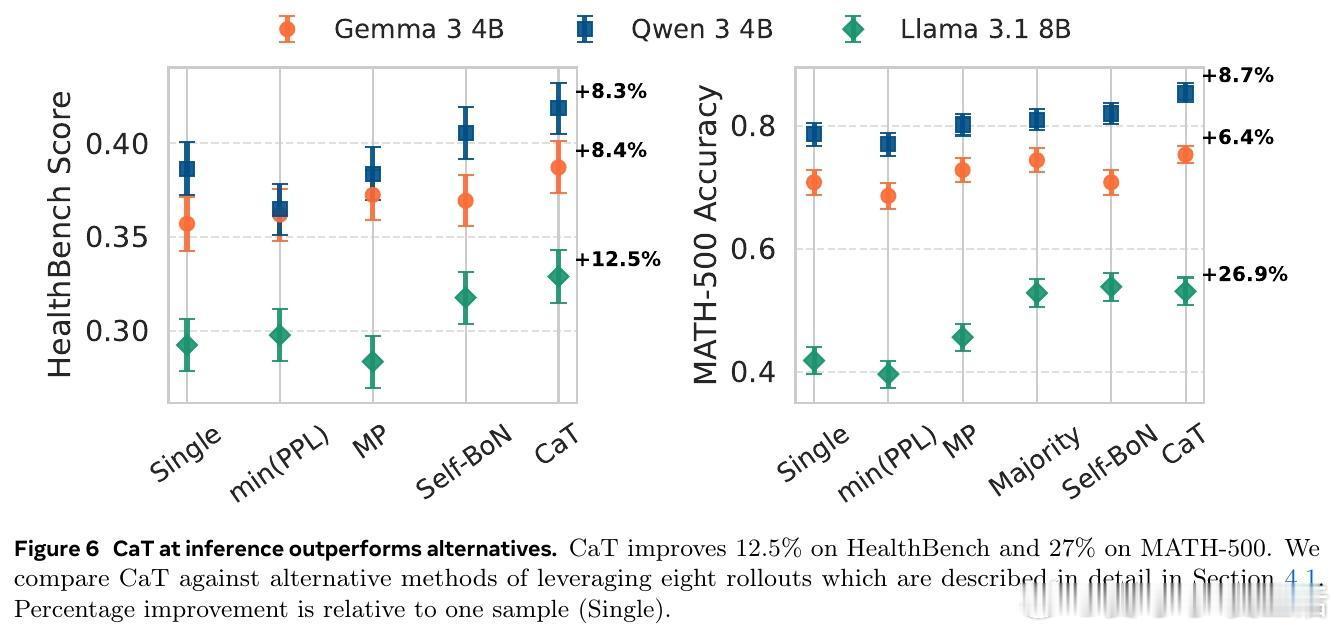
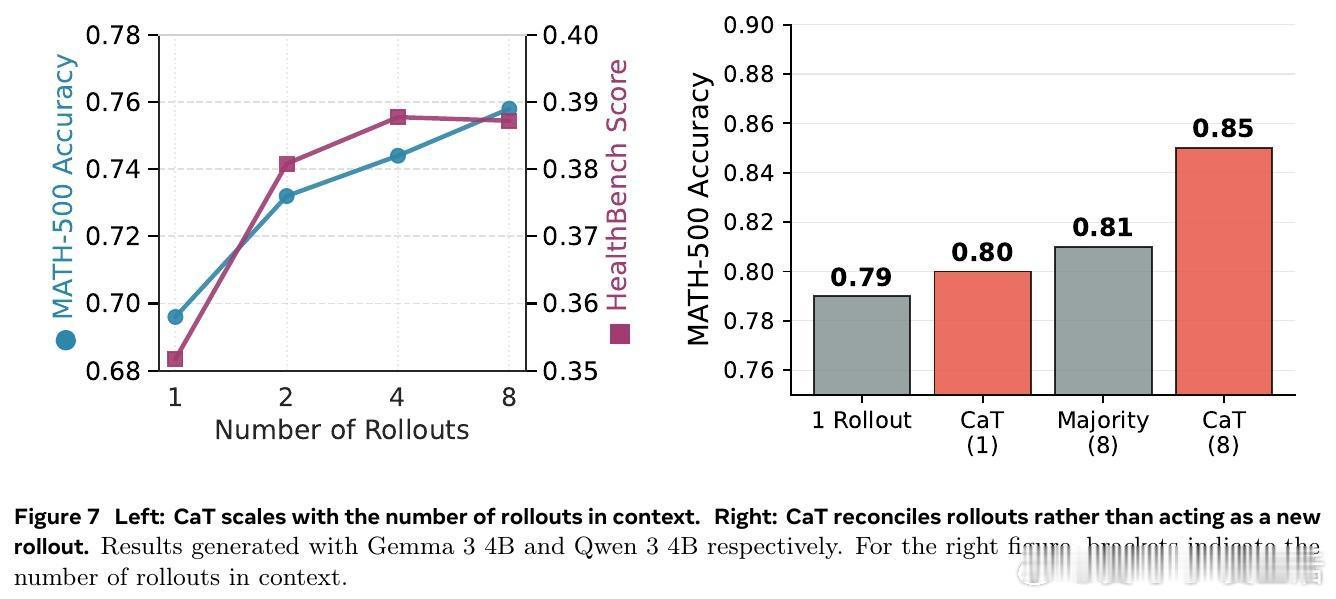
• 与传统的选优方法(best-of-N、投票、多模型评分)不同,CaT 通过合成策略能纠正多数乃至全部生成的错误,实现超越共识的答案改进,且性能随着并行生成数量递增而提升。
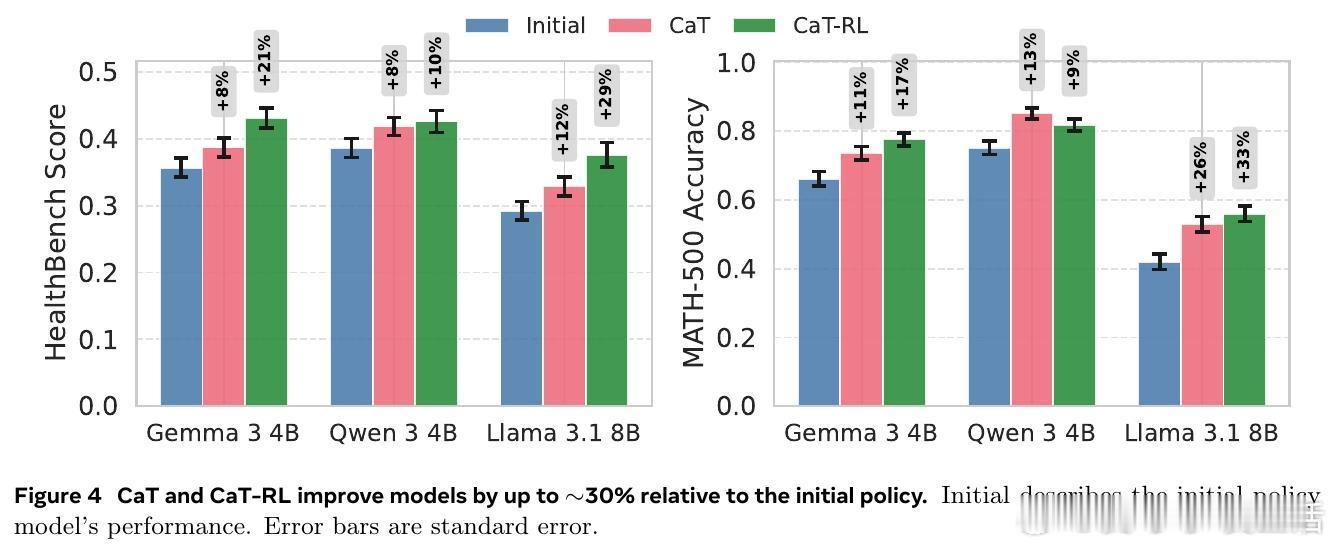
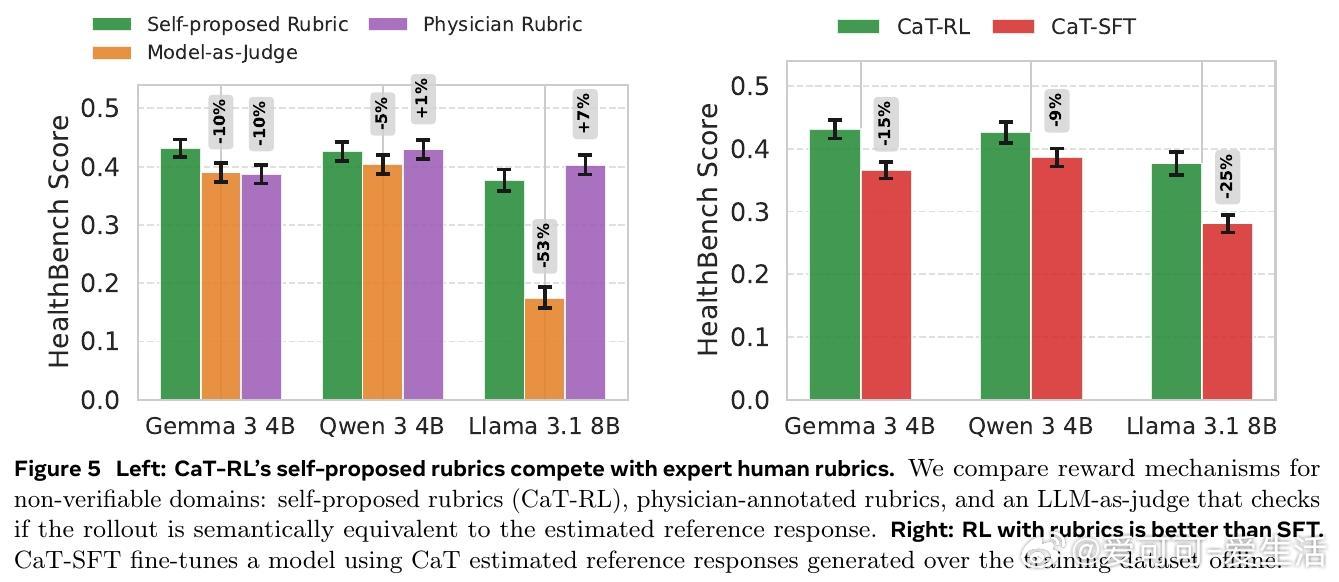
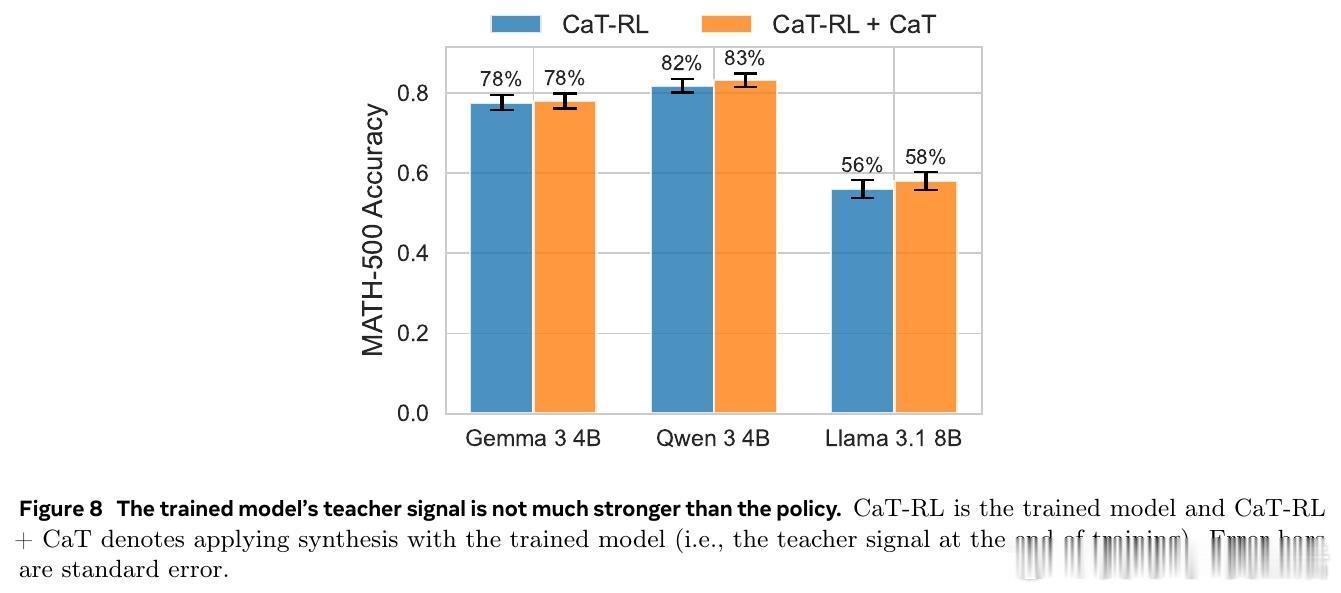
• RL 训练版本 CaT-RL 利用 CaT 产生的参考信号进行强化学习,显著提升模型表现(数学任务提升最高33%,医疗对话提升30%),并超过初始锚点策略。
• CaT 兼容多模型架构(Gemma 3 4B、Qwen 3 4B、Llama 3.1 8B),可作为推理时增强或训练时优化的低开销插件。
心得:
1. 让模型“自我监督”的关键是从多样化的并行探索中整合信息,纠正彼此矛盾和遗漏,实现类似集成的错误校正,突破单一生成的局限。
2. 自拟细化评分标准(rubrics)通过拆解整体评价为可核查的细粒度判据,显著降低奖励函数的不稳定性和表面形式偏差,提升训练信号的可靠性。
3. 计算资源不仅仅是推理成本,更能转化为训练信号,揭示了推理计算与监督学习之间未被充分利用的联系,为无标注条件下大模型持续自我提升提供新路径。
了解详情🔗arxiv.org/abs/2509.14234
大语言模型强化学习无监督训练模型自监督推理优化