[LG]《Small Models, Big Results: Achieving Superior Intent Extraction through Decomposition》D Cohen, Y Halpern, N Kahlon, J Oren... [Google] (2025)
用户意图提取面临准确性与资源限制的双重挑战。最新研究提出一种创新的分解式两阶段模型,有效提升小型多模态模型的意图理解能力,甚至超越部分大型MLLM表现。
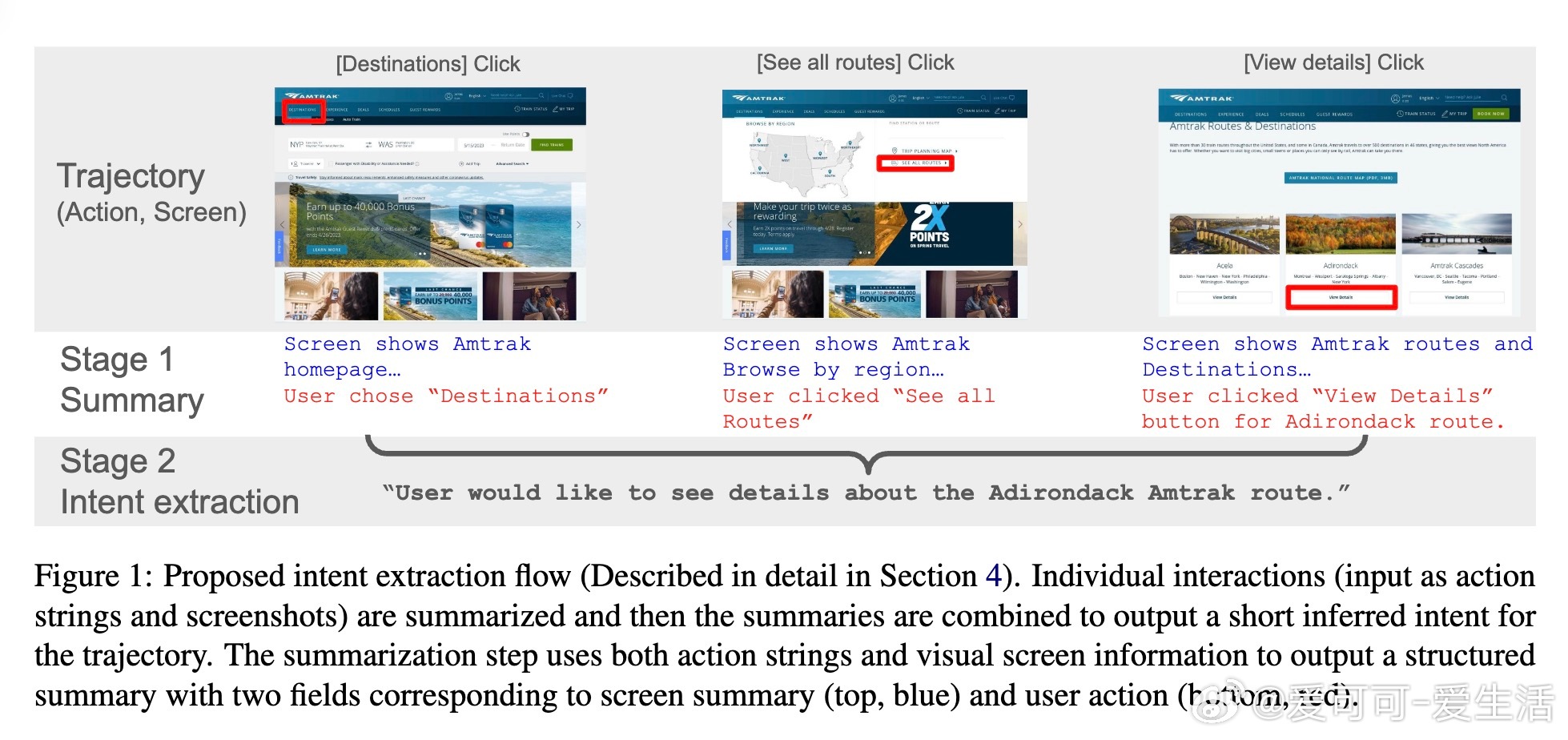
• 首阶段聚焦单步交互的结构化摘要,结合界面截图与文本动作,生成屏幕上下文与用户行为两部分摘要,辅以前后步骤上下文信息,极大减少信息遗漏与歧义。
• 次阶段基于首阶段生成的交互摘要序列,利用微调模型融合生成整体用户意图,针对训练数据中标签噪声进行细致清洗,降低模型幻觉和无关信息输出。
• 评测覆盖Mind2Web与AndroidControl两大公开UI交互数据集,采用先进的双向语义一致性指标BiFact及NLI,结果显示分解模型在F1、准确率和召回率上均显著优于端到端和CoT基线,且在领域、任务和网站未见样本中展现强泛化能力。
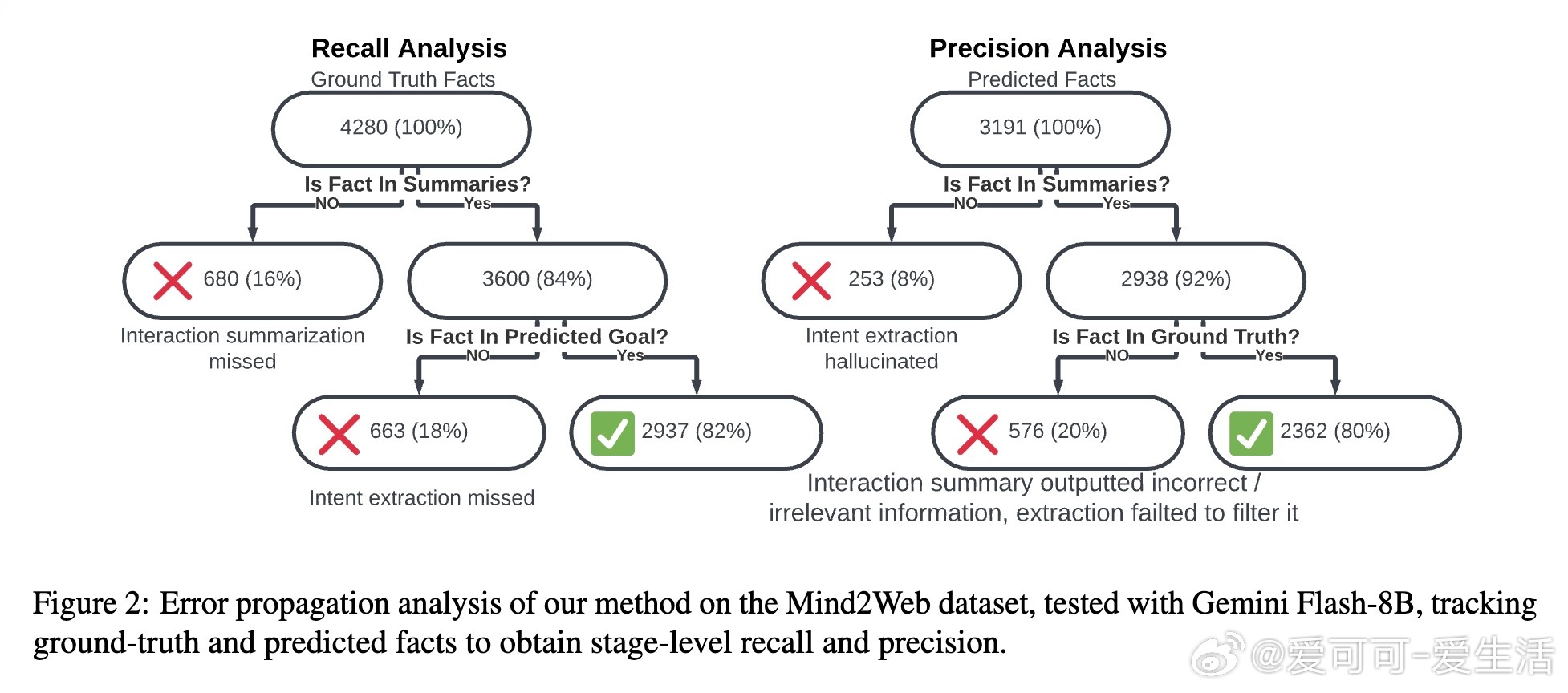
• 细粒度误差分析揭示,交互摘要与意图提取两阶段均存在约16%-18%的事实遗漏,幻觉率低至8%,模型设计有效控制误差传播。
• 计算成本虽较基础方法增加2-3倍,但仍远低于大型MLLM,且通过延迟优化可保持低延迟,适合隐私敏感且资源有限的移动端和浏览器端部署。
心得:
1. 分解复杂任务为结构化摘要与意图融合两步,既降低单步处理难度,也支持小模型高效利用多模态信息。
2. 标签清洗与微调相结合显著缓解了真实数据中的噪声影响,提升模型稳健性与解释性。
3. 结构化摘要设计兼顾详尽与去幻觉,成为提升整体意图提取精度的关键因素。
详见🔗arxiv.org/abs/2509.12423
用户意图多模态模型小模型大效果人机交互自然语言处理