[LG]《Tree-OPO: Off-policy Monte Carlo Tree-Guided Advantage Optimization for Multistep Reasoning》B Huang, T Nguyen, M Zimmer [Technical University Munich & Huawei R&D Munich & Huawei Noah’s Ark Lab] (2025)
Tree-OPO:利用离线MCTS前缀树的层级优势估计,推动多步推理中的偏好强化学习优化。
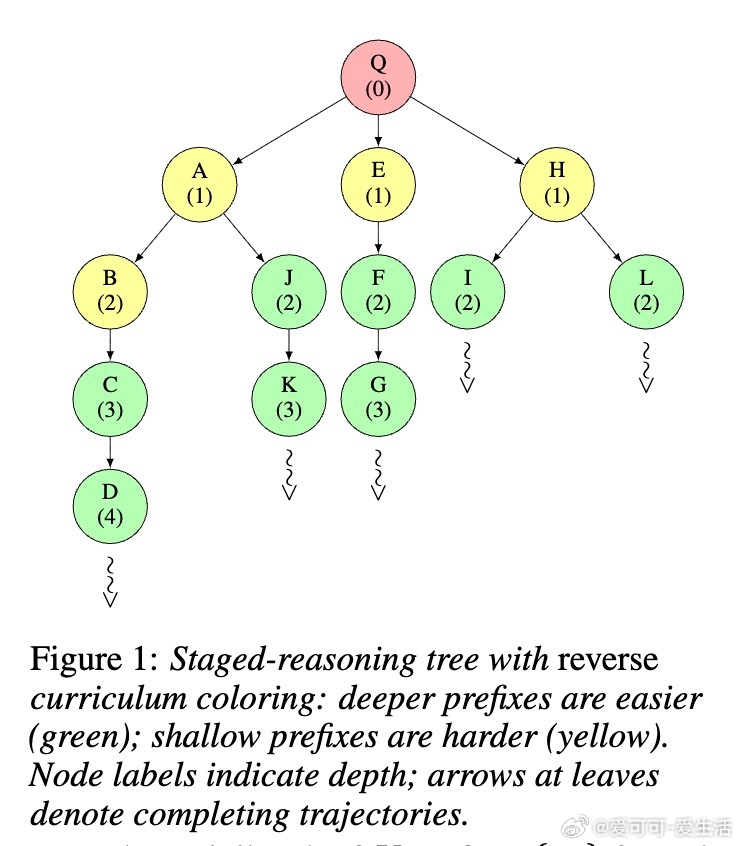
• 结合离线教师策略生成的多步MCTS轨迹,将复杂多步推理拆解为树结构的前缀-完成对,构建层级提示空间,实现基于偏好的相对策略优化。
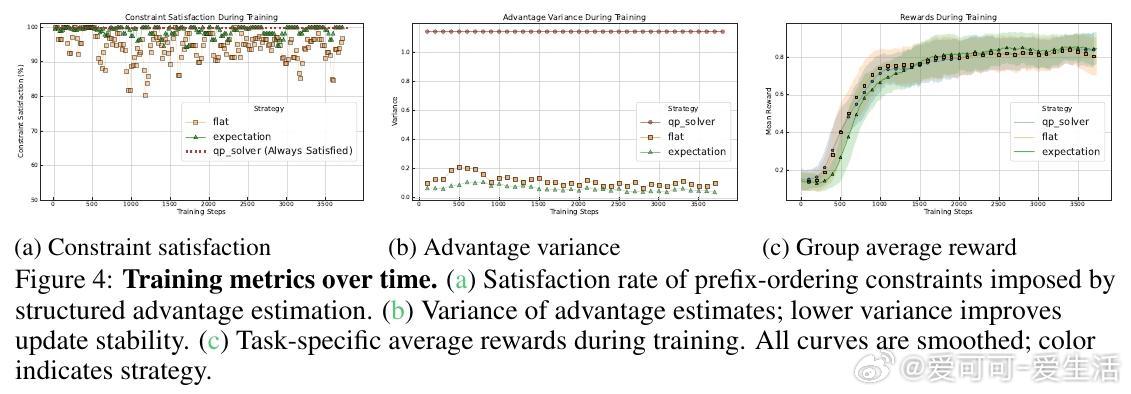
• 提出分阶段优势估计(SAE),通过约束二次规划融入树结构的顺序一致性,解决不同前缀期望回报差异导致的基线错配与梯度方差过大问题。
• SAE方法在理论上保证优势方差不增,强化梯度信号区分度,显著提升样本效率;实验证明基于经验期望的启发式基线在实际中平衡了方差与偏差。
• 采用逆向课程策略,策略在线从教师MCTS前缀中启动续航,利用子问题难度层次实现多难度混合训练,提升训练稳定性和泛化能力。
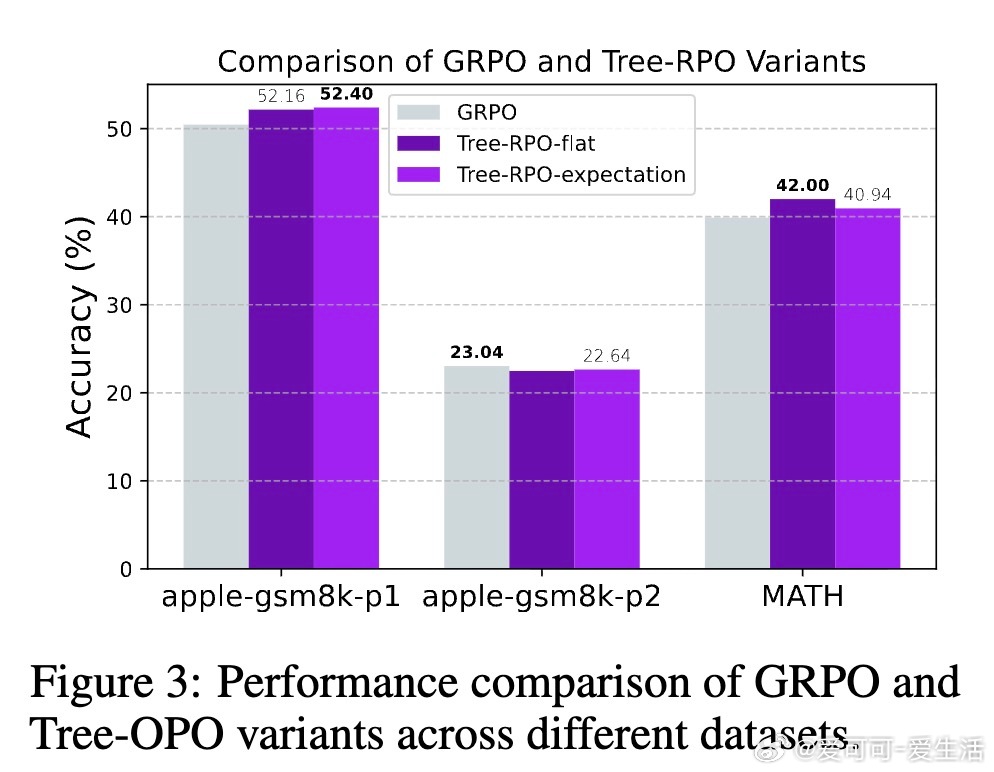
• 与传统GRPO及KL蒸馏方法相比,Tree-OPO无需价值网络和教师策略在线rollouts,减少计算资源,且在数学推理基准GSM8K及扩展测试集表现优异,准确率提升明显。
• 结合启发式基线(经验期望、乐观与悲观)与软约束QP求解,兼顾计算效率与优势估计的结构性一致性,缓解稀疏奖励和优势饱和等实际挑战。
心得:
1. 利用MCTS生成的结构化轨迹数据,将复杂任务转化为层级子任务,显著降低了学习难度并提升了训练信号密度,体现了分治思想在强化学习中的深度应用。
2. 通过结构化优势估计强化梯度信号的区分性与稳定性,是提升多步推理强化学习样本效率的关键,说明合理的结构约束是解决稀疏奖励与高方差问题的有效路径。
3. 跨领域的逆向课程学习隐含了“从易到难”的训练范式,促进模型在不同难度层次上的均衡发展,具备指导未来复杂任务分层训练设计的启示。
详见🔗arxiv.org/abs/2509.09284
强化学习多步推理蒙特卡洛树搜索策略优化大语言模型