[RO]《Data Retrieval with Importance Weights for Few-Shot Imitation Learning》A Xie, R Chand, D Sadigh, J Hejna [Stanford University] (2025)
重要权重引导的数据检索革新少样本模仿学习,显著提升机器人任务迁移性能。
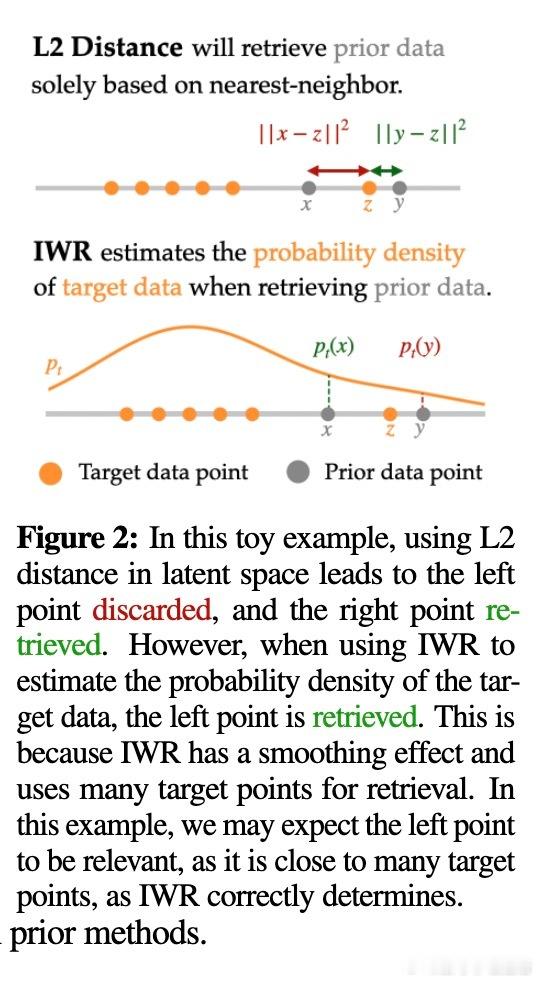
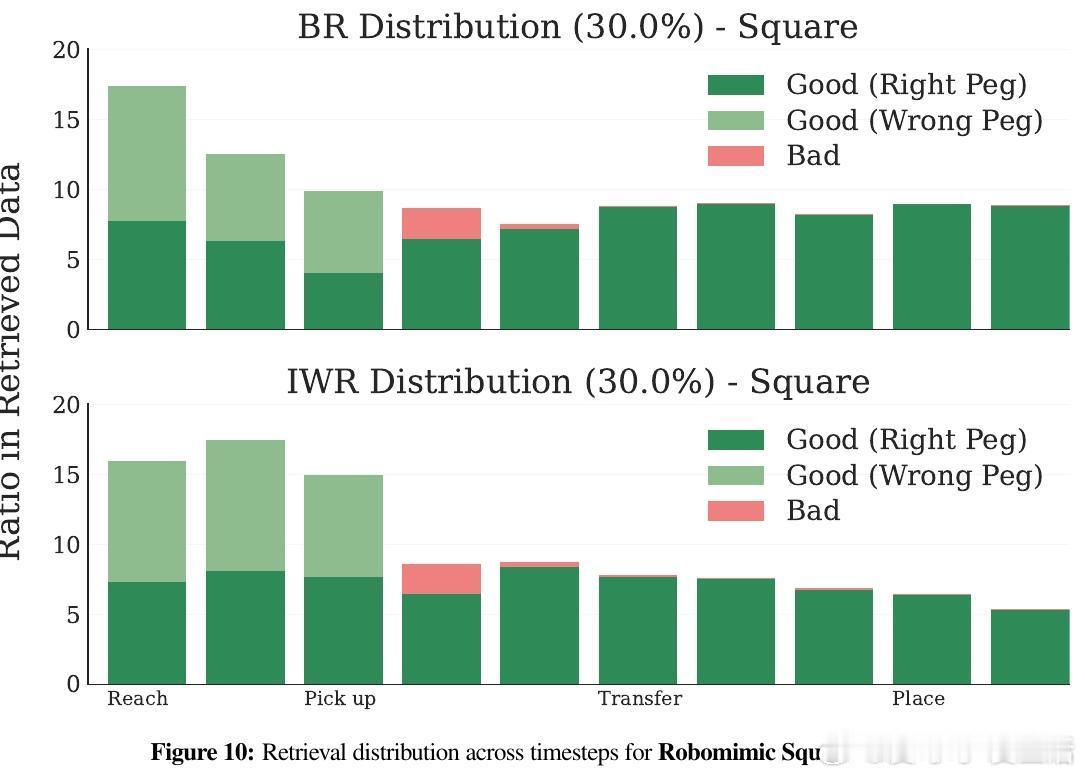
• 现有检索方法基于目标示范数据的最近邻L2距离进行样本选择,等价于高方差的高斯核密度估计(KDE)极限,忽视了先验数据分布,导致采样偏差和噪声敏感。
• 提出Importance Weighted Retrieval (IWR),利用双核密度估计分别拟合目标和先验数据分布,通过计算两者的概率密度比(重要性权重)来加权检索,平滑估计并校正偏差。
• IWR兼容多种潜在空间表示(如VAE编码的状态-动作对),仅需替换原有最近邻检索步骤,计算开销极低。
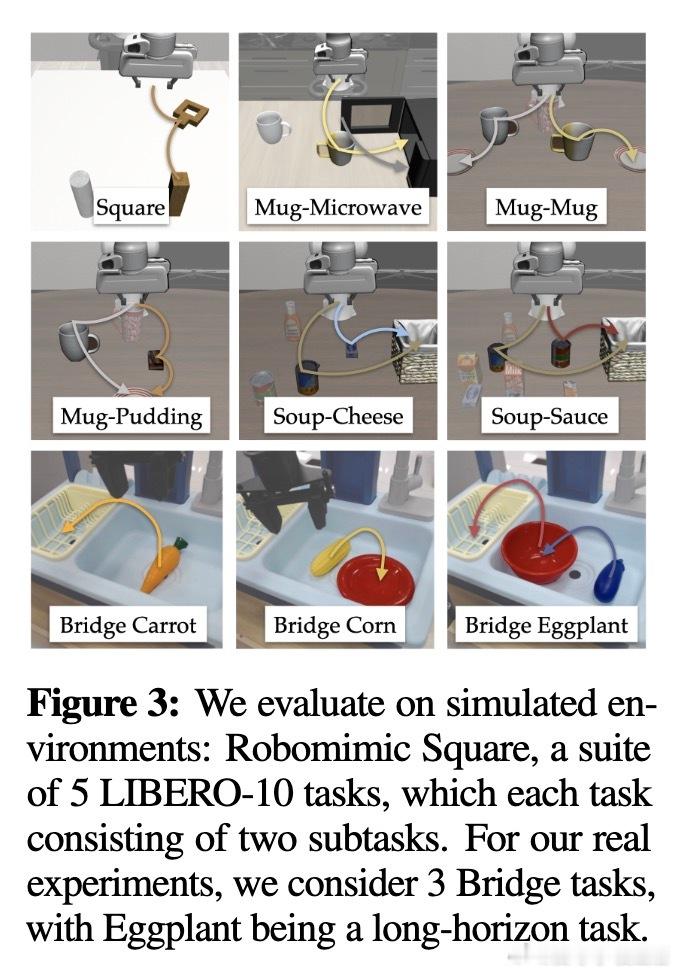
• 在模拟环境(Robomimic Square、LIBERO)及真实机器人Bridge任务上,IWR相较传统方法平均成功率提升5.8%至30%,尤其长时序任务表现更优。
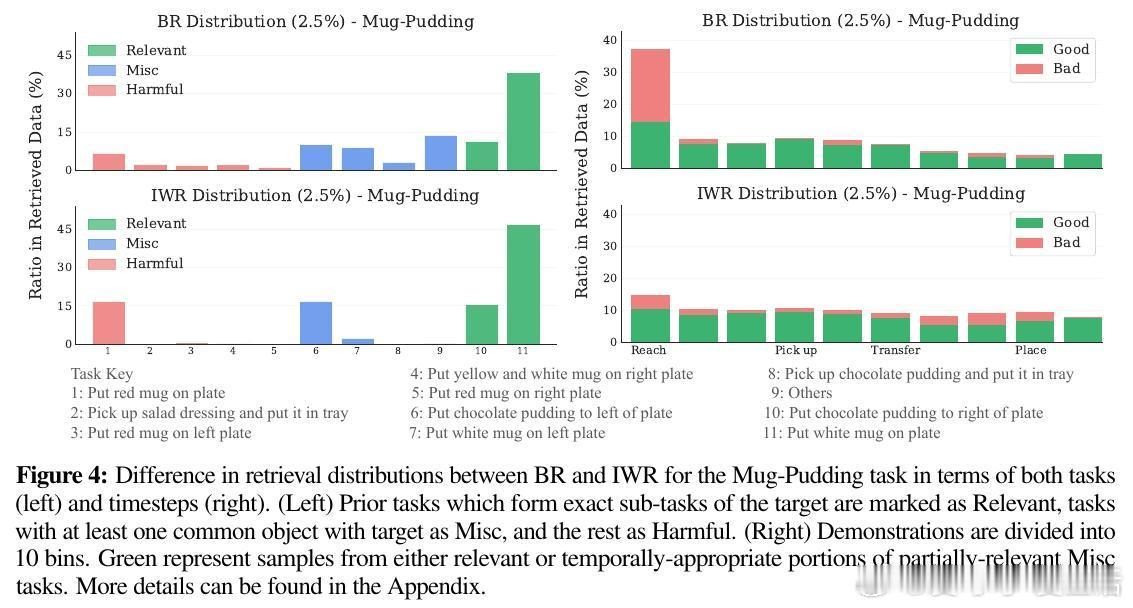
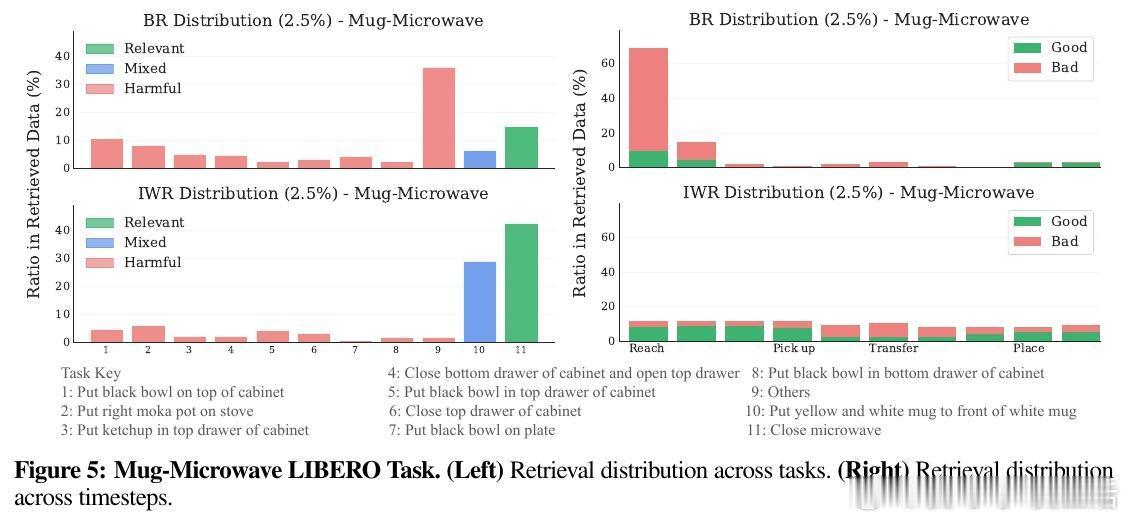
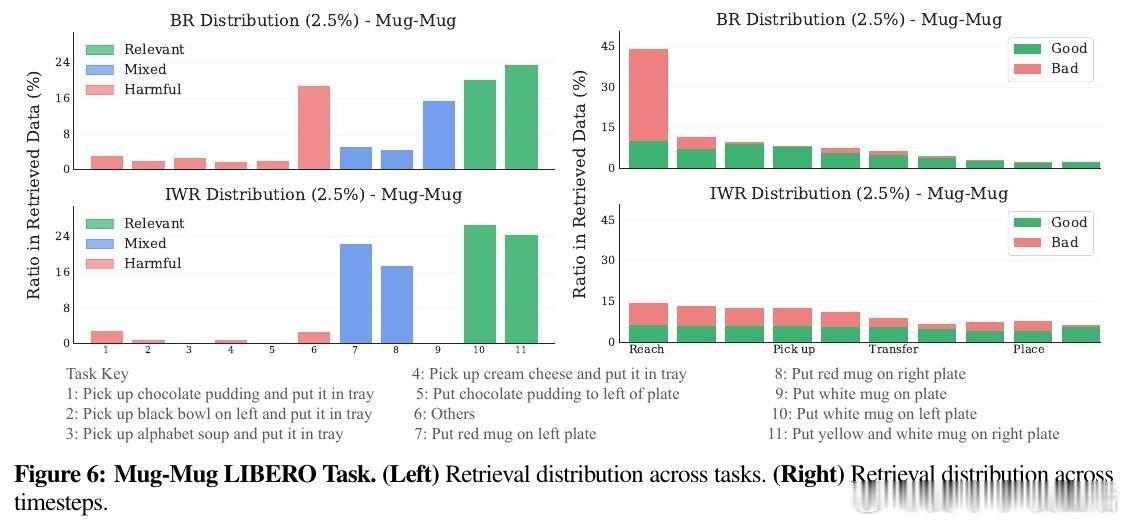
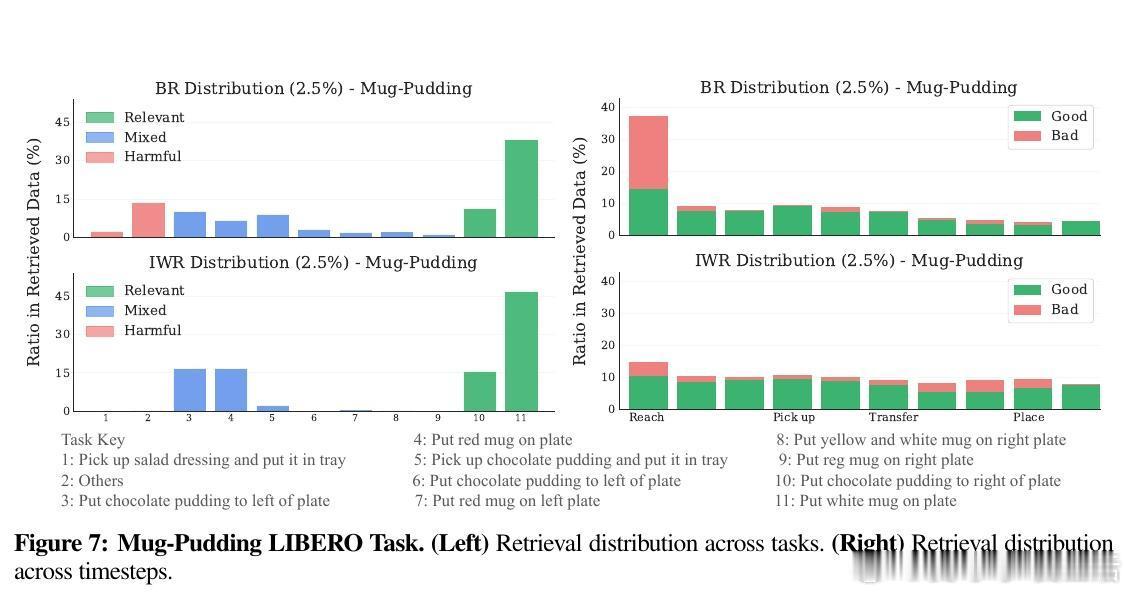
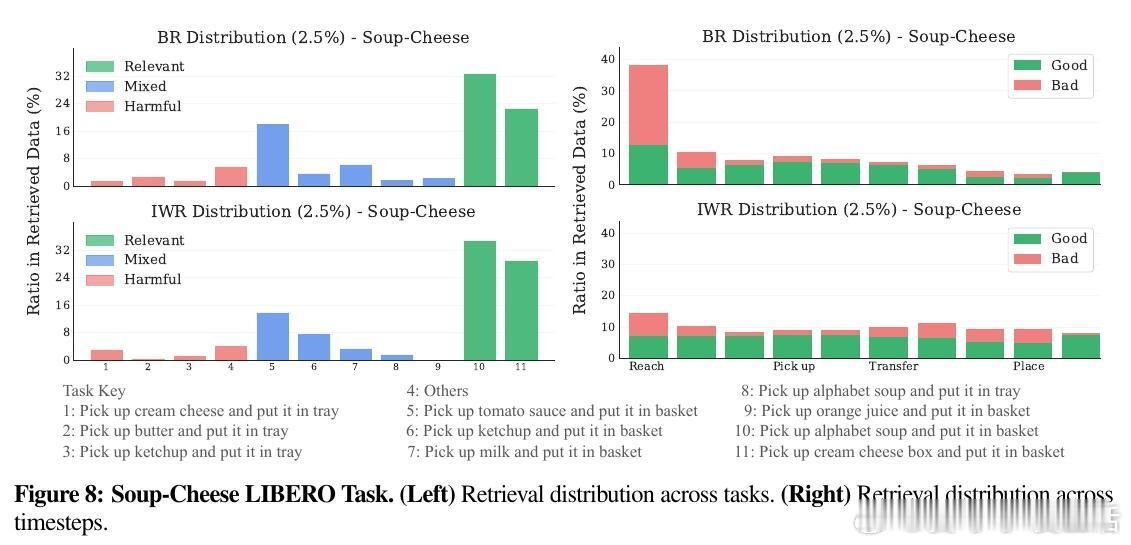
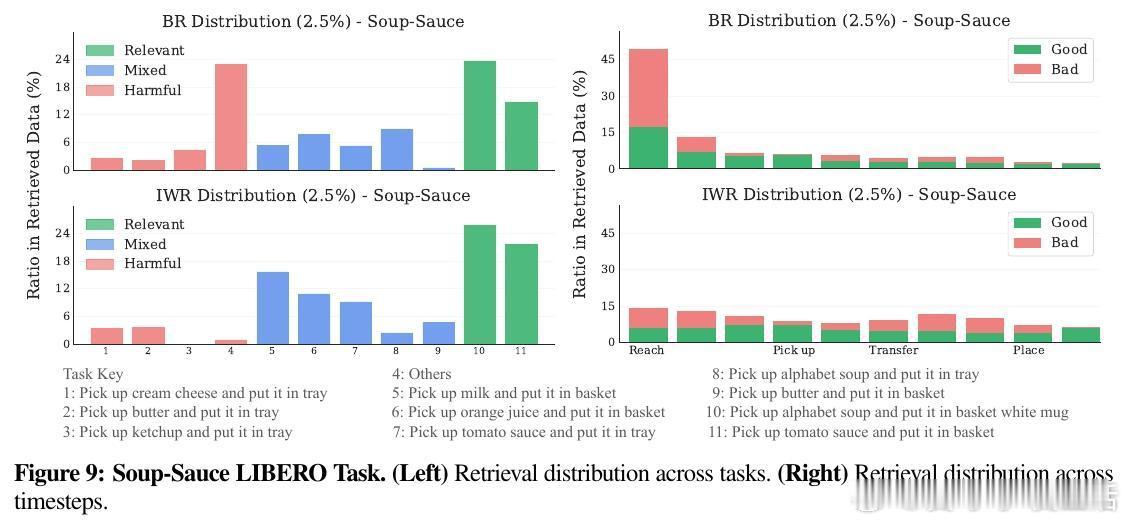
• 实验显示IWR能避免检索无关或有害样本,平衡时序分布,提升数据多样性和相关性,缓解任务初期样本偏移问题。
• 通过重要性权重归一化,IWR显著降低了估计方差,带来更稳定的策略训练效果。
• 目前IWR对潜在空间的平滑性有依赖,对非平滑编码(如BYOL)效果有限,且高维KDE计算复杂,未来可探索更高效的密度比估计方法。
心得:
1. 从概率视角出发,检索不仅是最近邻搜索,而是目标与先验分布密度比的估计,精准把握数据“相关性”本质。
2. 利用全局核密度估计代替局部极值,显著降低噪声带来的高方差,体现数据选择中平滑性的重要性。
3. 结合先验分布调整采样权重,实际任务中能有效减少无关样本干扰,提升少样本模仿学习的泛化能力。
论文🔗arxiv.org/abs/2509.01657
详见🔗 rahulschand.github.io/iwr/
机器人学习少样本学习模仿学习重要性采样核密度估计数据检索