[LG]《Attention Layers Add Into Low-Dimensional Residual Subspaces》J Wang, X Ge, W Shu, Z He... [Shanghai Innovation Institute & Fudan University] (2025)
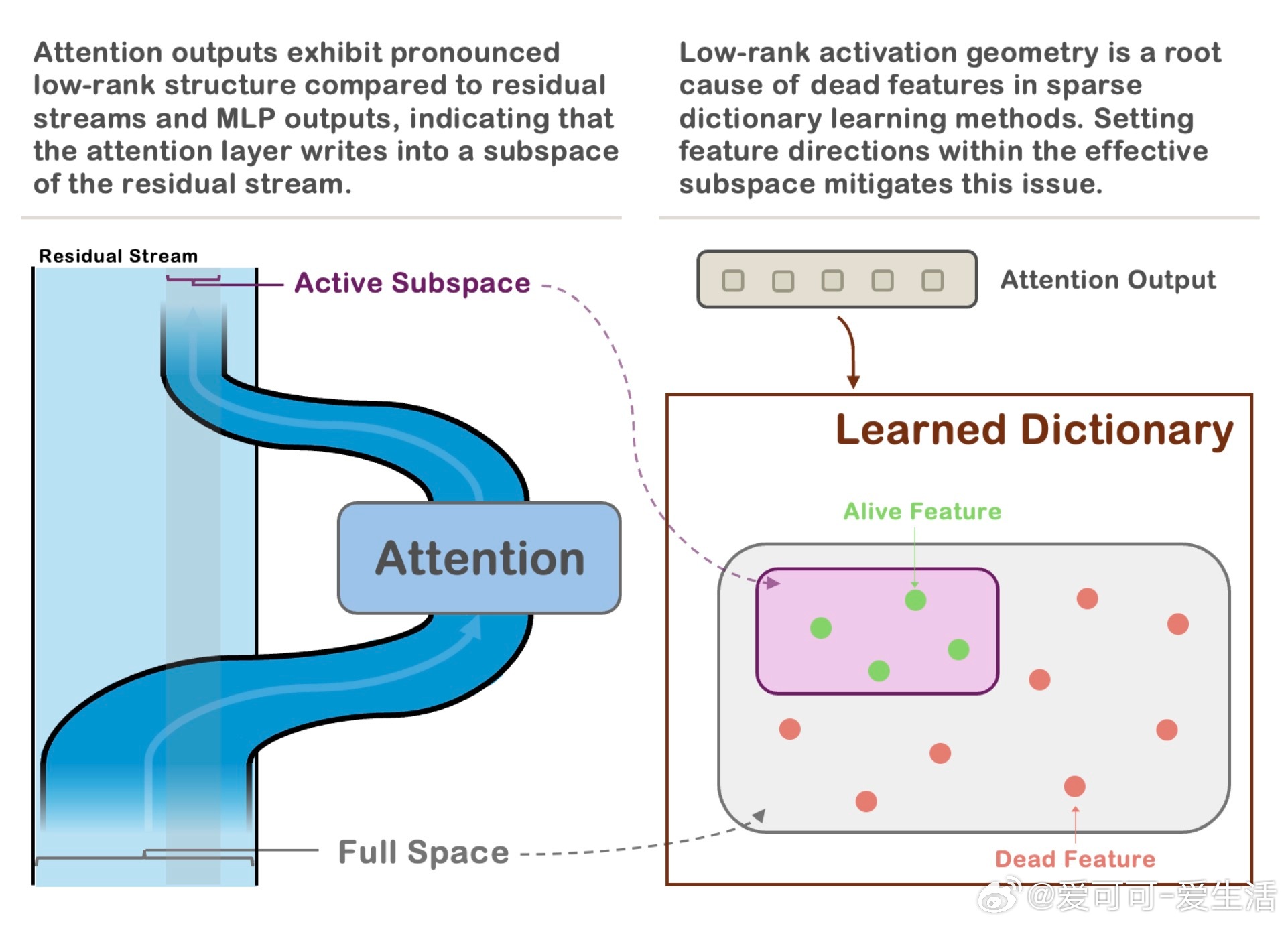
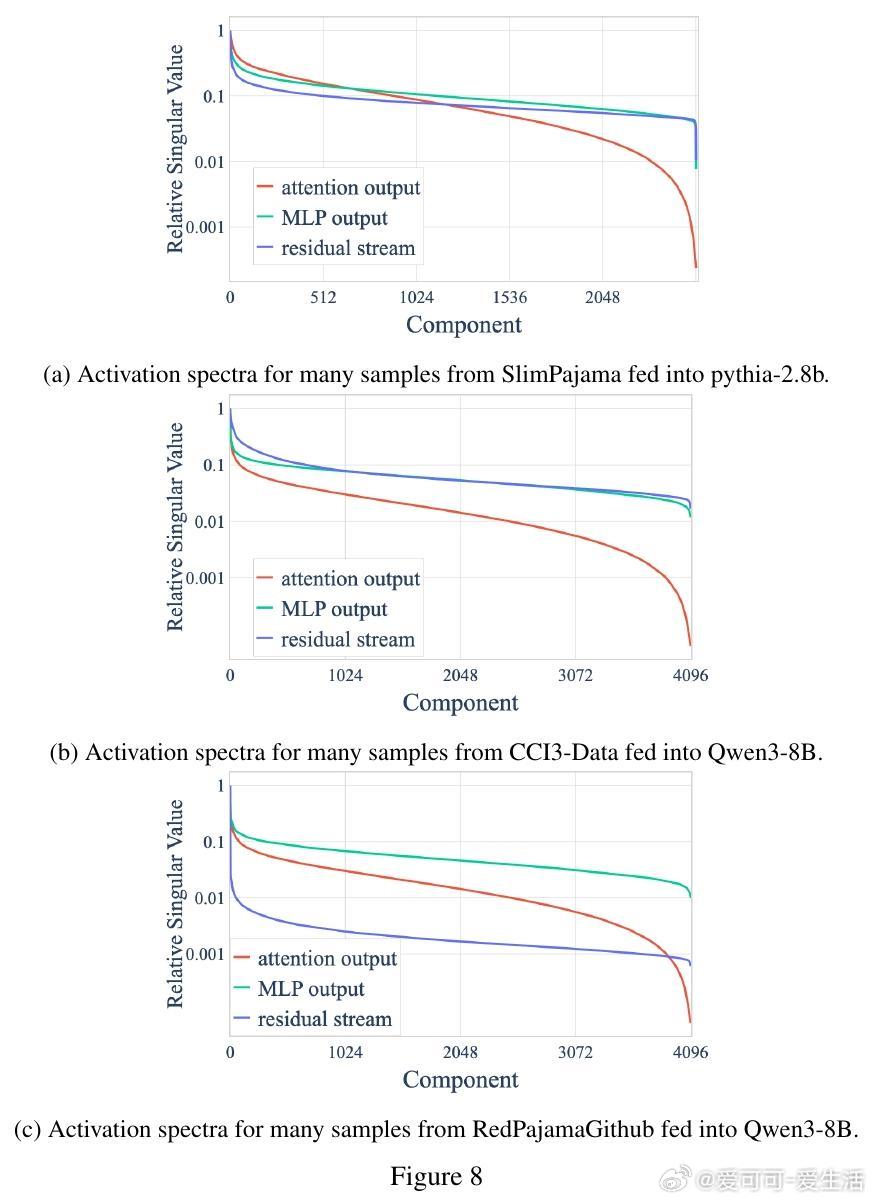
Transformer模型中,Attention层的输出意外地被限制在一个低维残差子空间内,约60%的方向承载了99%的方差。这一低秩结构由输出投影矩阵引发,遍及多模型和数据集,且是稀疏字典学习中死特征问题的根源。
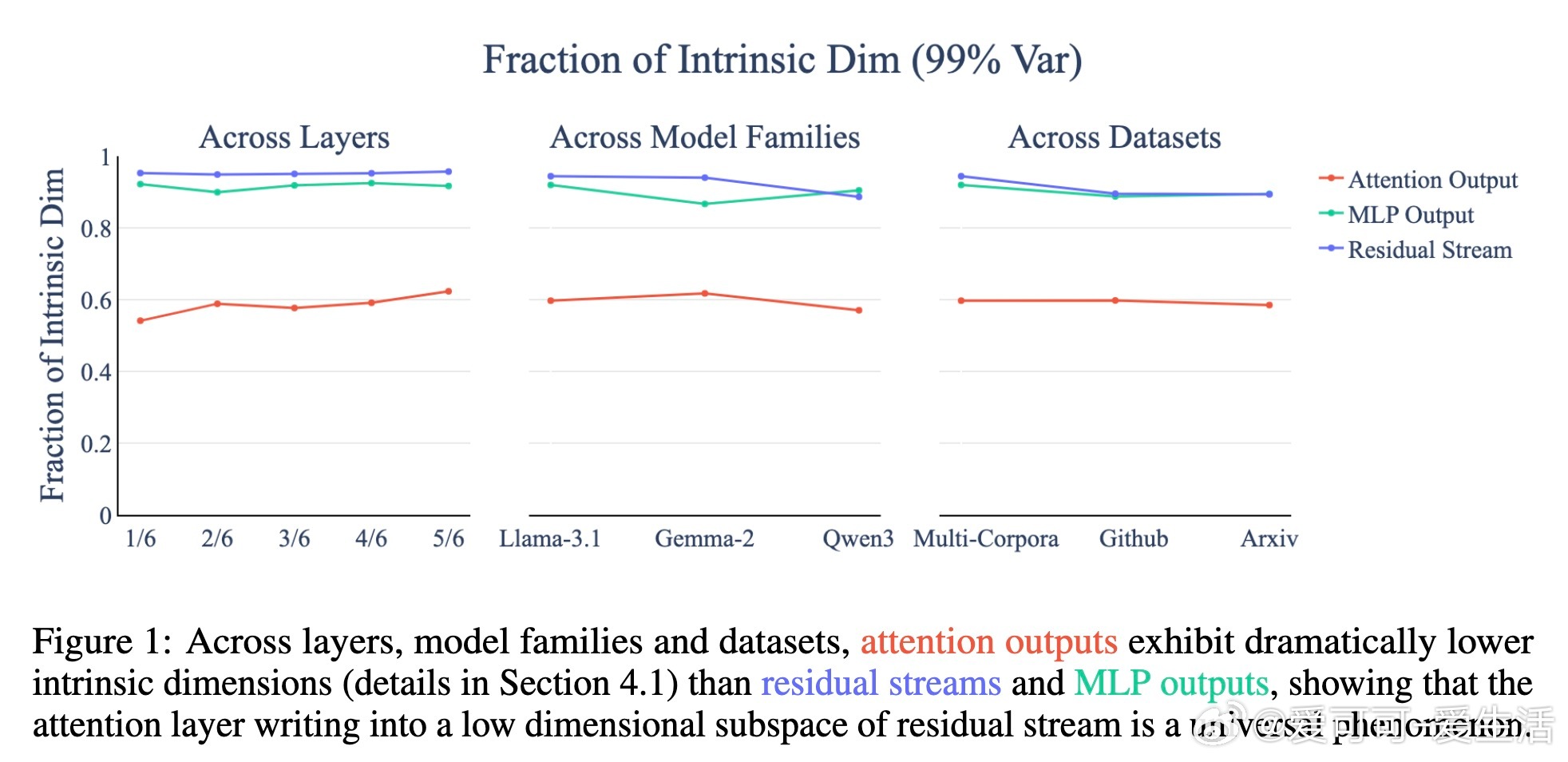
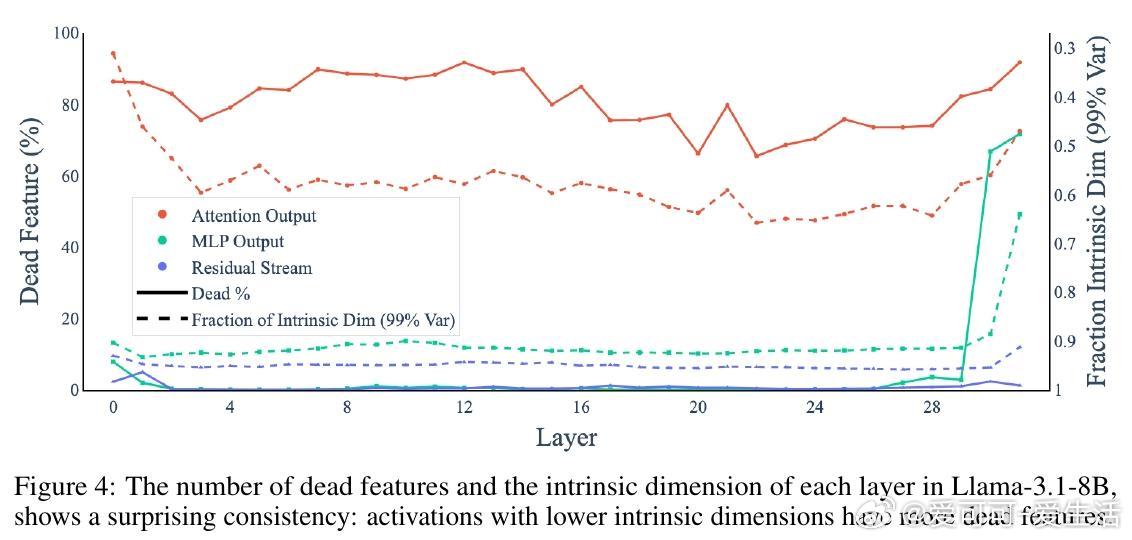
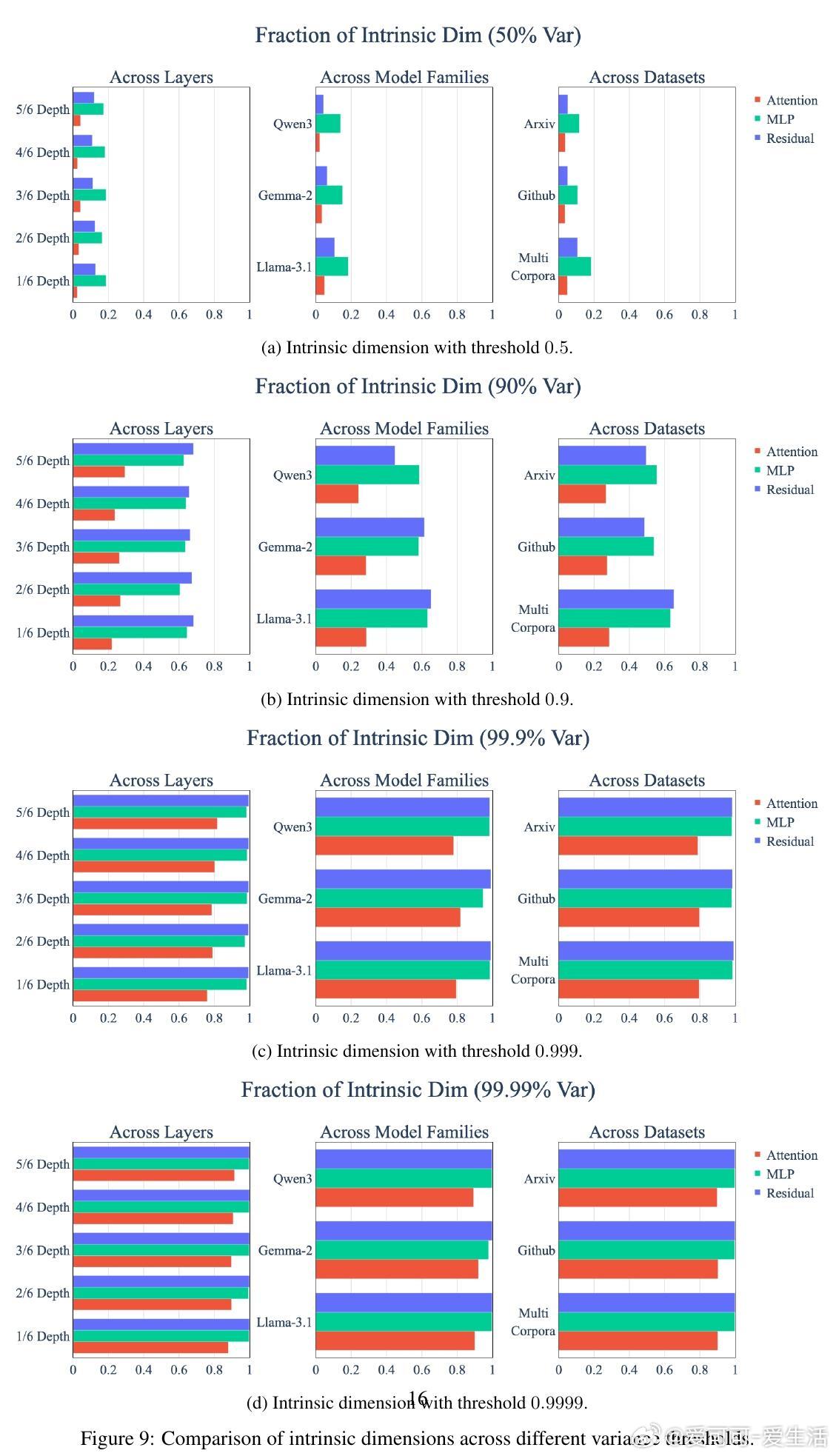
• Attention输出的内在维度显著低于MLP和残差流,约为总维度的60%,而后者均高于90%。
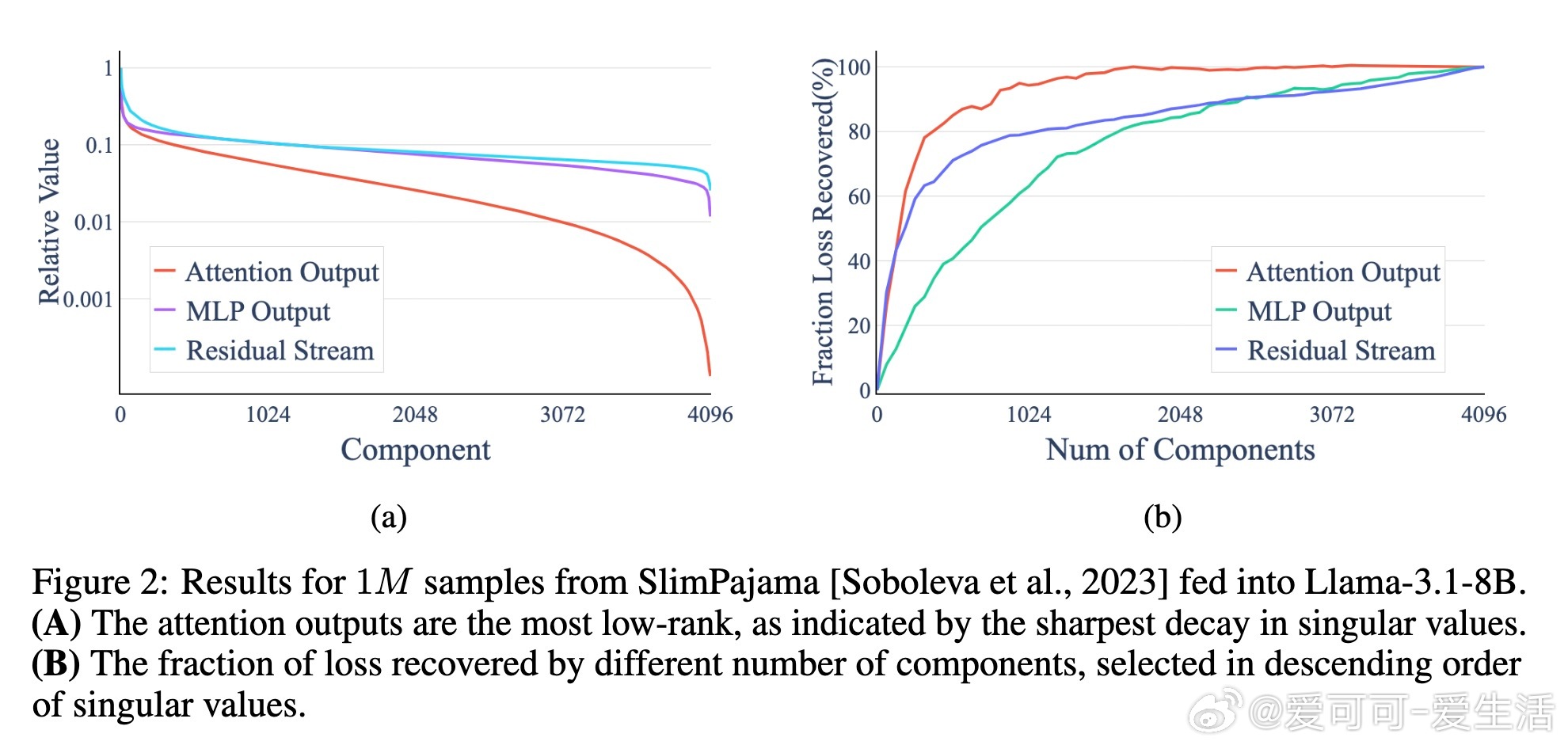
• 奇异值谱快速衰减,仅少数主成分捕获绝大部分能量,维度效率极高,25%维度即可恢复95%下游损失。
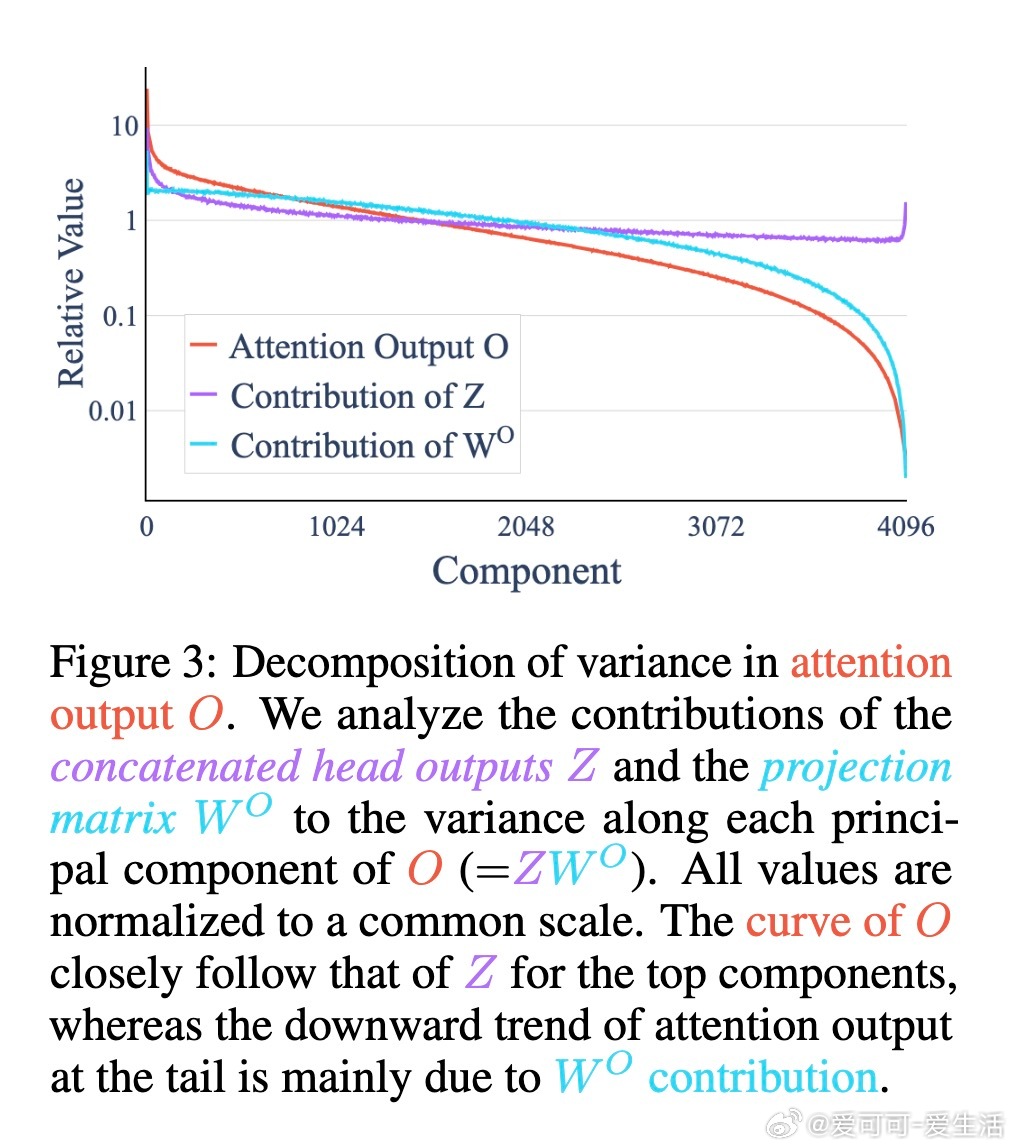
• 该低秩现象主要源于输出投影矩阵W^O的各向异性压缩,导致多头子空间重叠,整体维度远小于理论最大值。
• 死特征(训练中几乎未激活的特征)数量与激活的内在维度密切相关,反映初始化特征与激活空间几何不匹配。
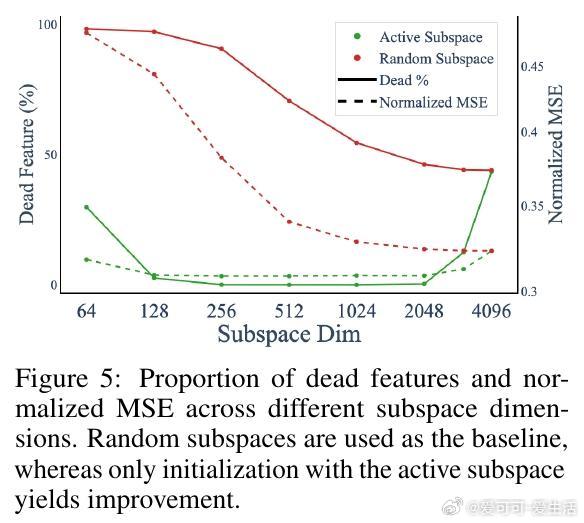
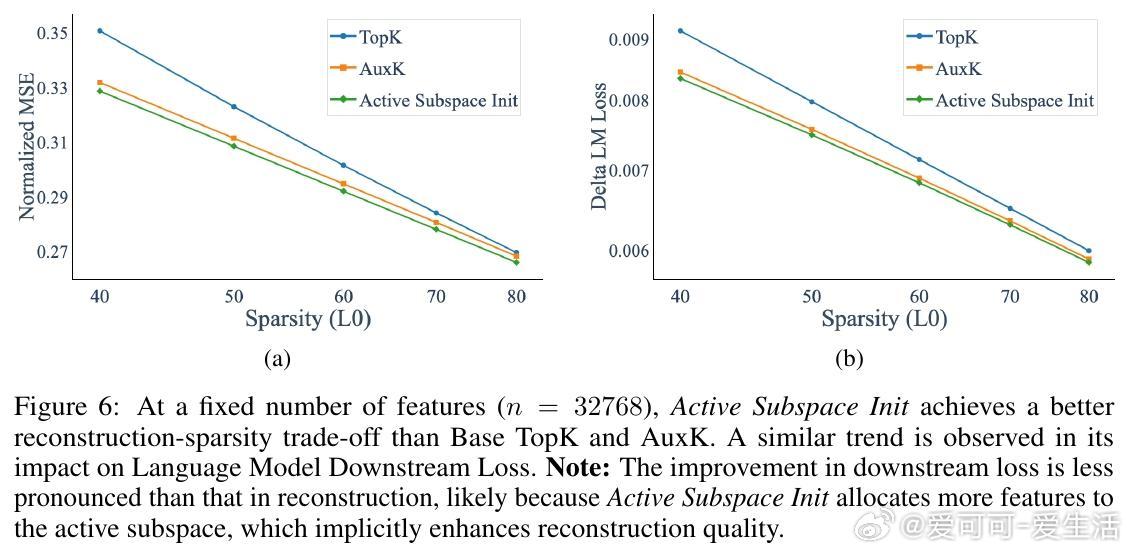
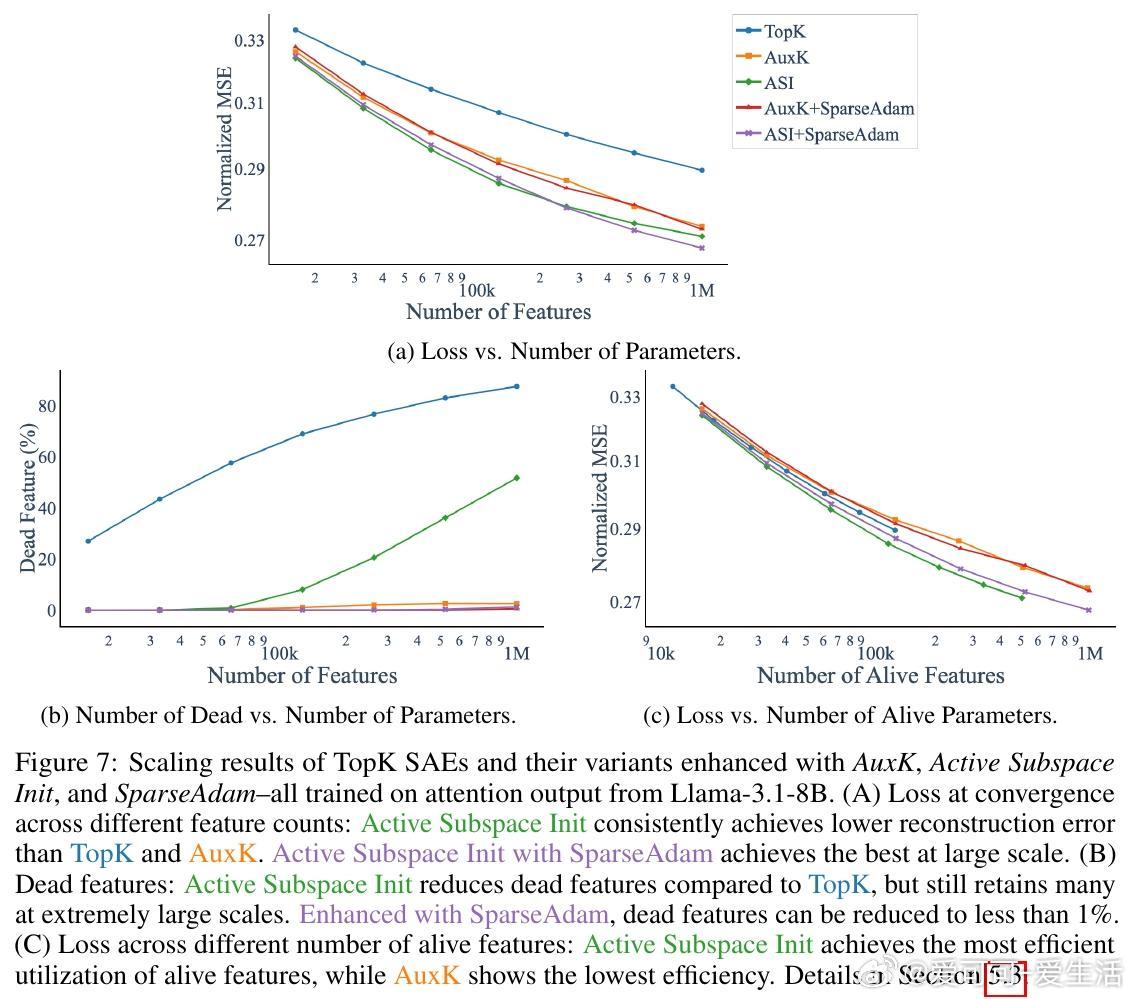
• 提出“Active Subspace Initialization”(ASI):用激活的主奇异向量子空间初始化稀疏自编码器(SAEs)特征方向,显著降低死特征比例(从87%降至1%以下),提高重构性能。
• ASI无需额外计算开销,且在大规模特征数下表现优越,结合SparseAdam优化器进一步减少死特征,提升训练稳定性和效率。
• ASI方法推广至其他稀疏替代模型,如Lorsa,减少死参数比例,并略微改善重构误差。
• 研究涵盖多模型(Llama-3.1-8B、Qwen3-8B、Gemma-2-9B)与多语料,验证该低秩结构的普适性。
心得:
1. Transformer Attention层并非在全维空间自由运作,其输出本质上受到强烈的低维约束,这挑战了普遍的高维隐空间假设。
2. 死特征问题根植于模型激活的几何结构,随机初始化与激活空间错配是核心瓶颈,调整初始化策略能有效提升稀疏学习效率。
3. 结合激活子空间信息与专用优化器,能实现高容量稀疏模型的训练扩展,为未来大型语言模型的可解释性和参数高效利用提供新范式。
详情🔗arxiv.org/abs/2508.16929
Transformer 稀疏自编码器 低秩结构 注意力机制 模型可解释性 大语言模型 优化器