[LG]《Not All Bits Are Equal: Scale-Dependent Memory Optimization Strategies for Reasoning Models》J Kim, E Ewer, T Moon, J Park... [KRAFTON & University of Wisconsin–Madison] (2025)
针对推理型大语言模型(LLMs),传统的4-bit权重量化策略未必适用。原因在于推理模型的记忆瓶颈更多来源于KV缓存而非模型权重本身。
核心发现:
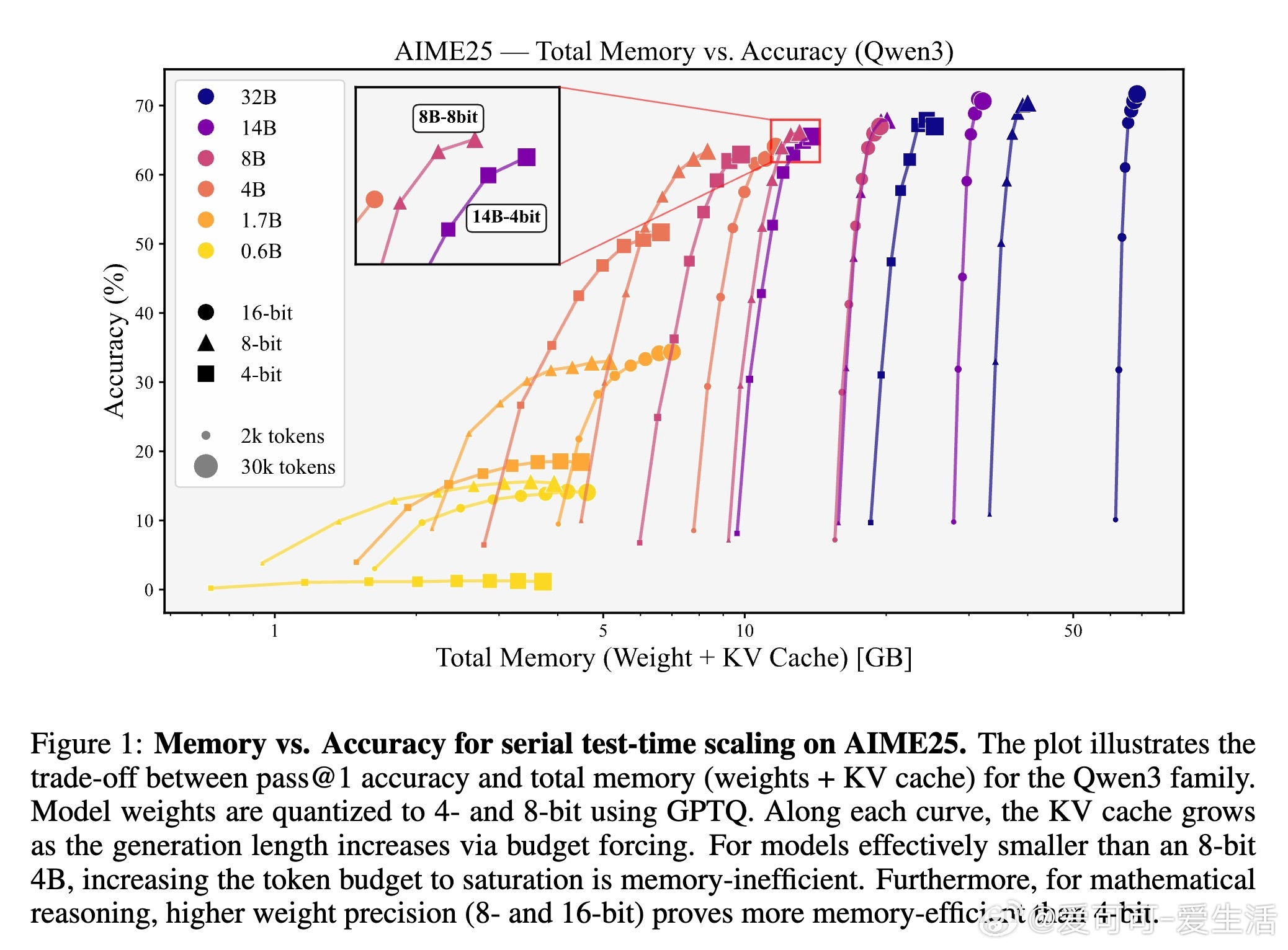
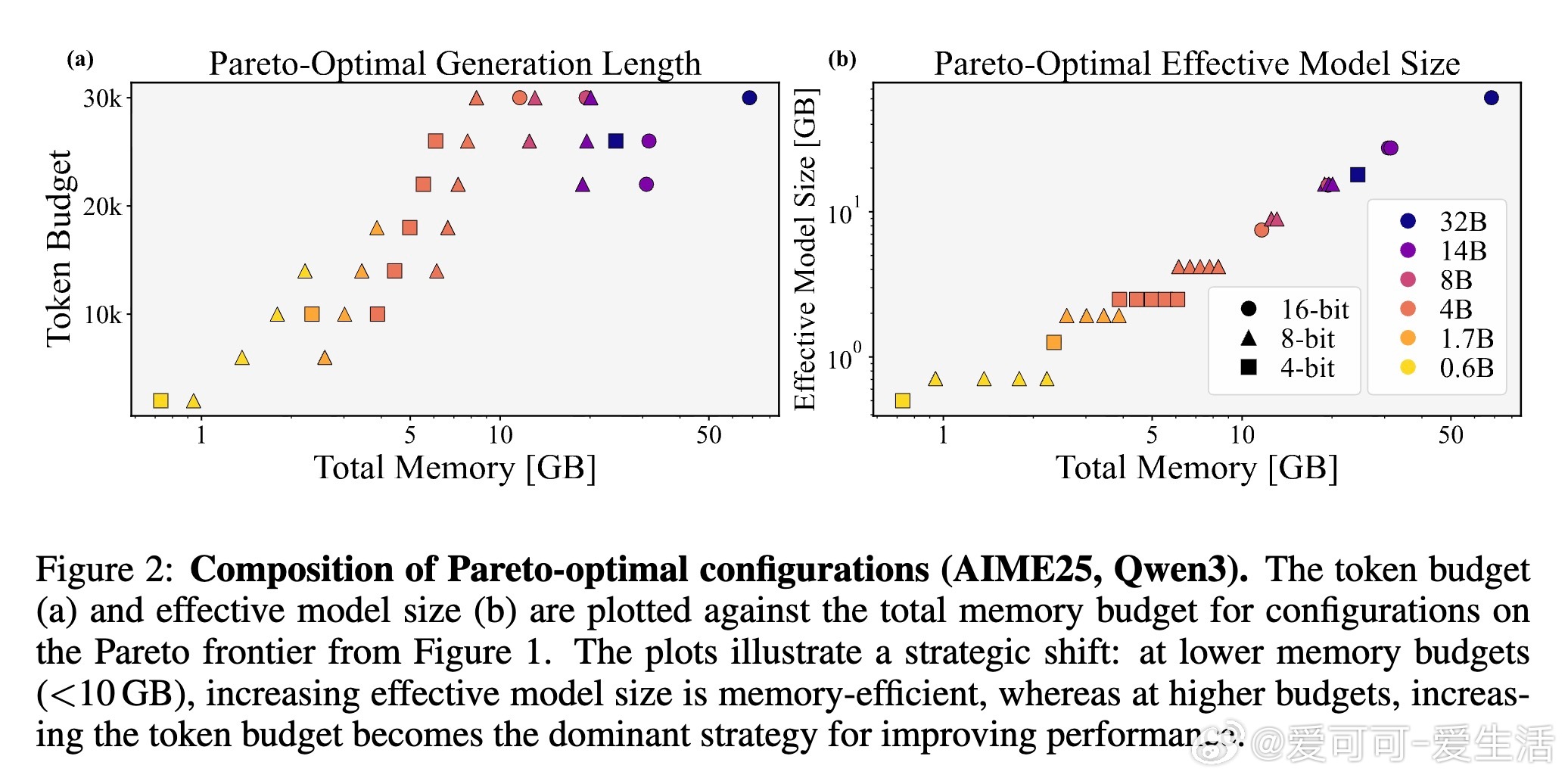
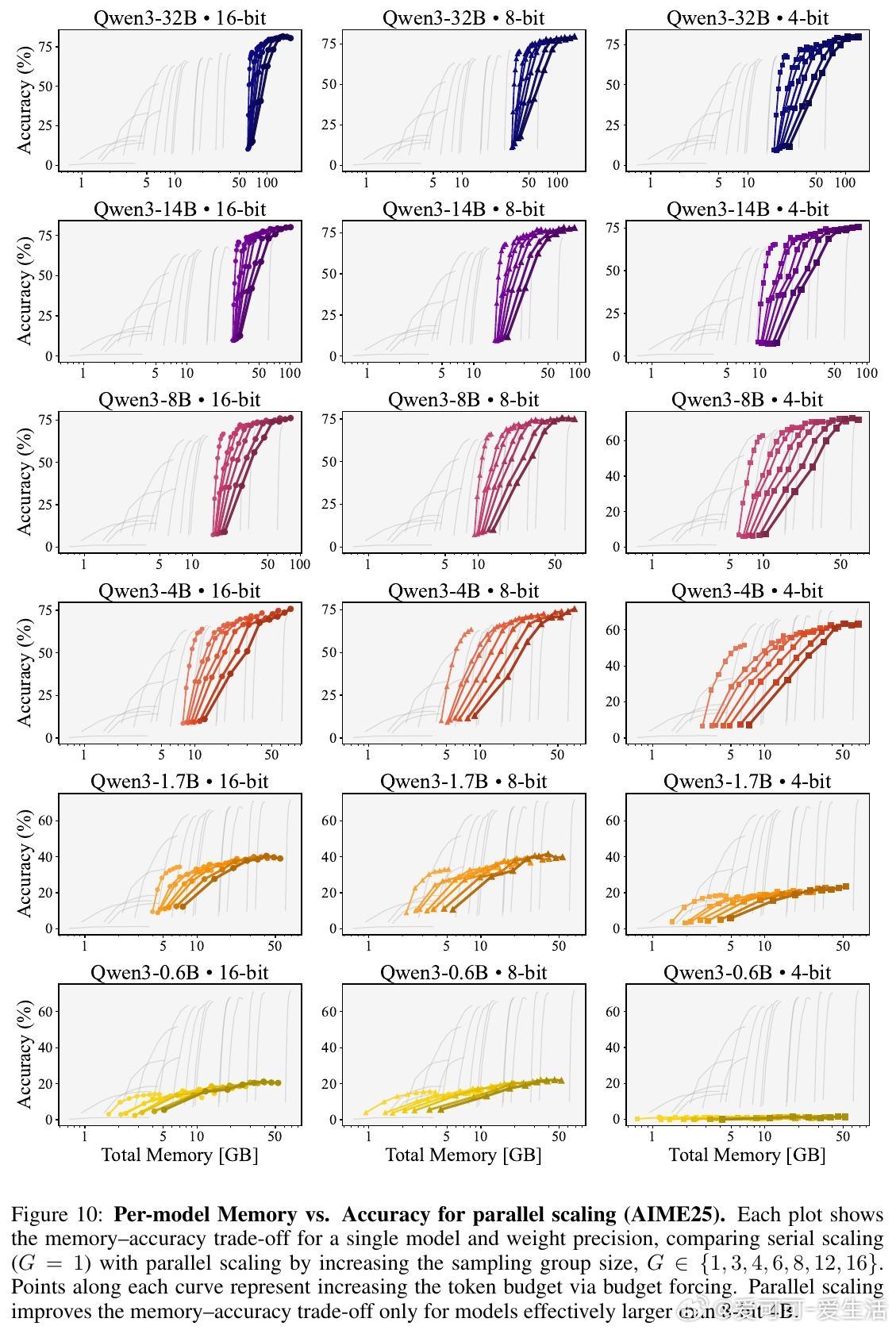
1. 内存分配的最优策略依赖于模型规模。对于有效规模小于“8-bit 4B参数”阈值的模型,优先增大模型权重数(即模型容量)优于延长生成长度;而超过该阈值的大模型,则应优先提升生成长度以获得更佳精度。
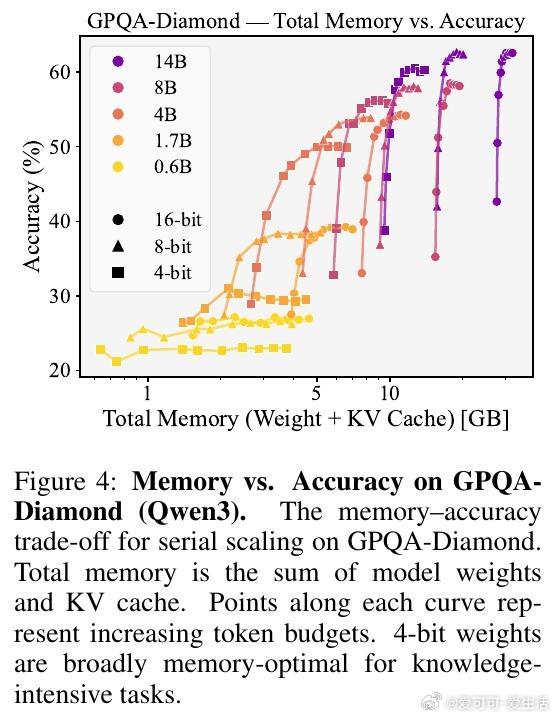
2. 任务类型决定权重精度选择。知识密集型任务(如GPQA-Diamond)适合4-bit权重量化以节省内存;数学推理任务(如AIME25)则需更高精度(8-bit或16-bit)以避免精度损失。
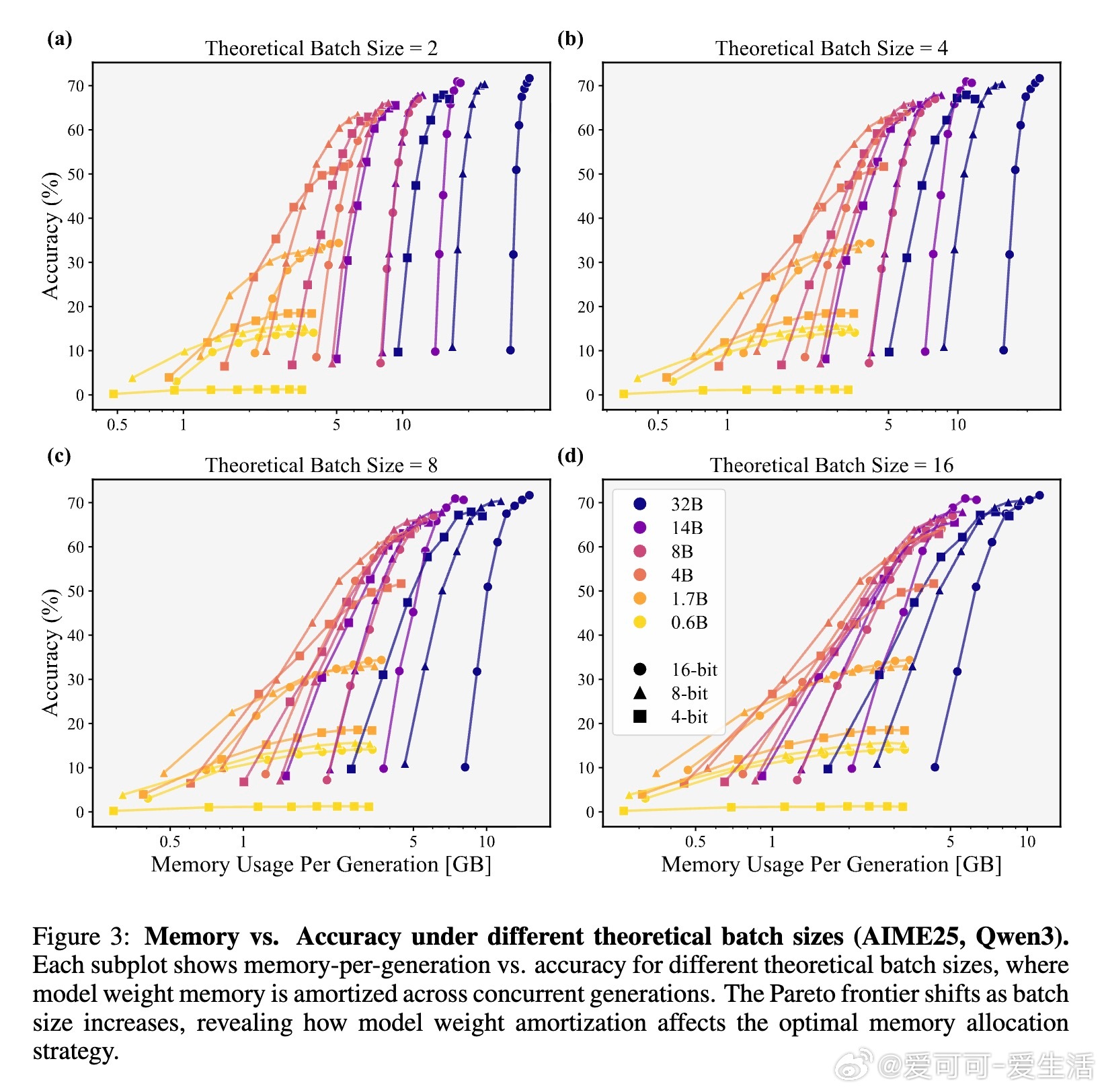
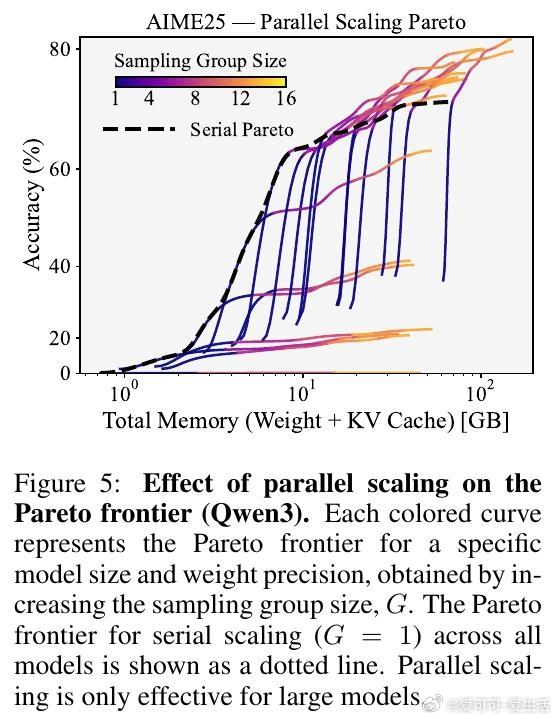
3. 并行扩展(增加采样组大小)只在大模型(≥8-bit 4B)上提升内存-准确率权衡,且最佳组大小随内存预算增长。
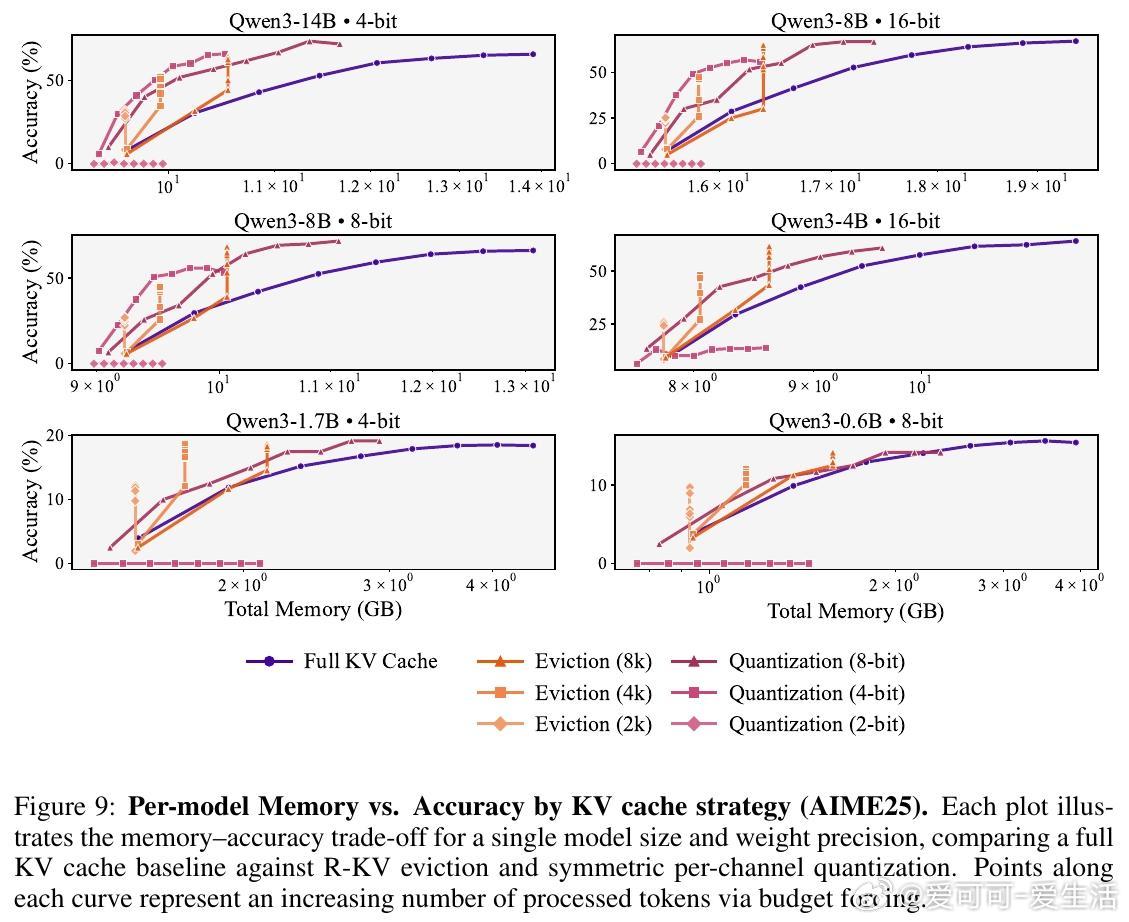
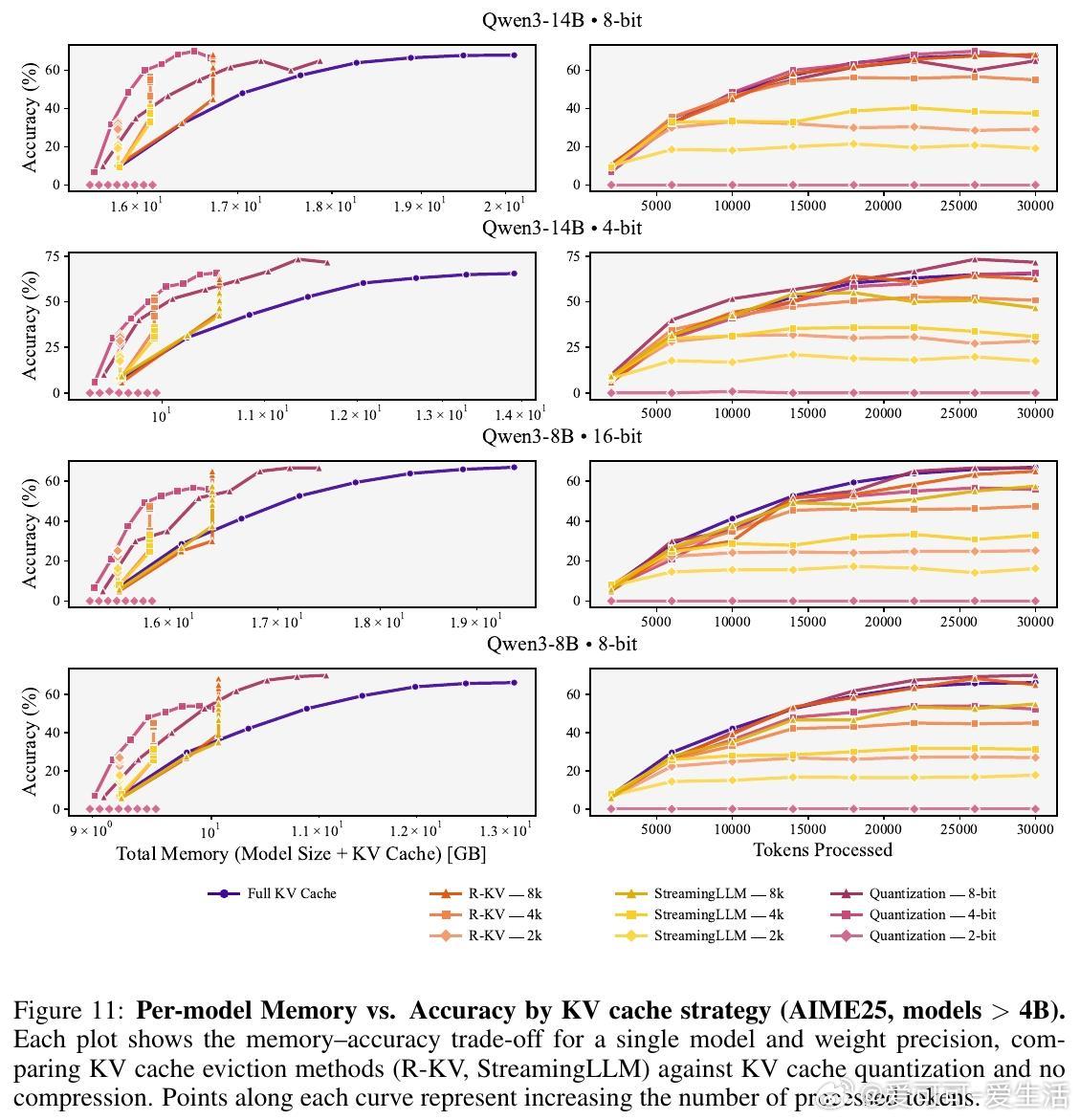
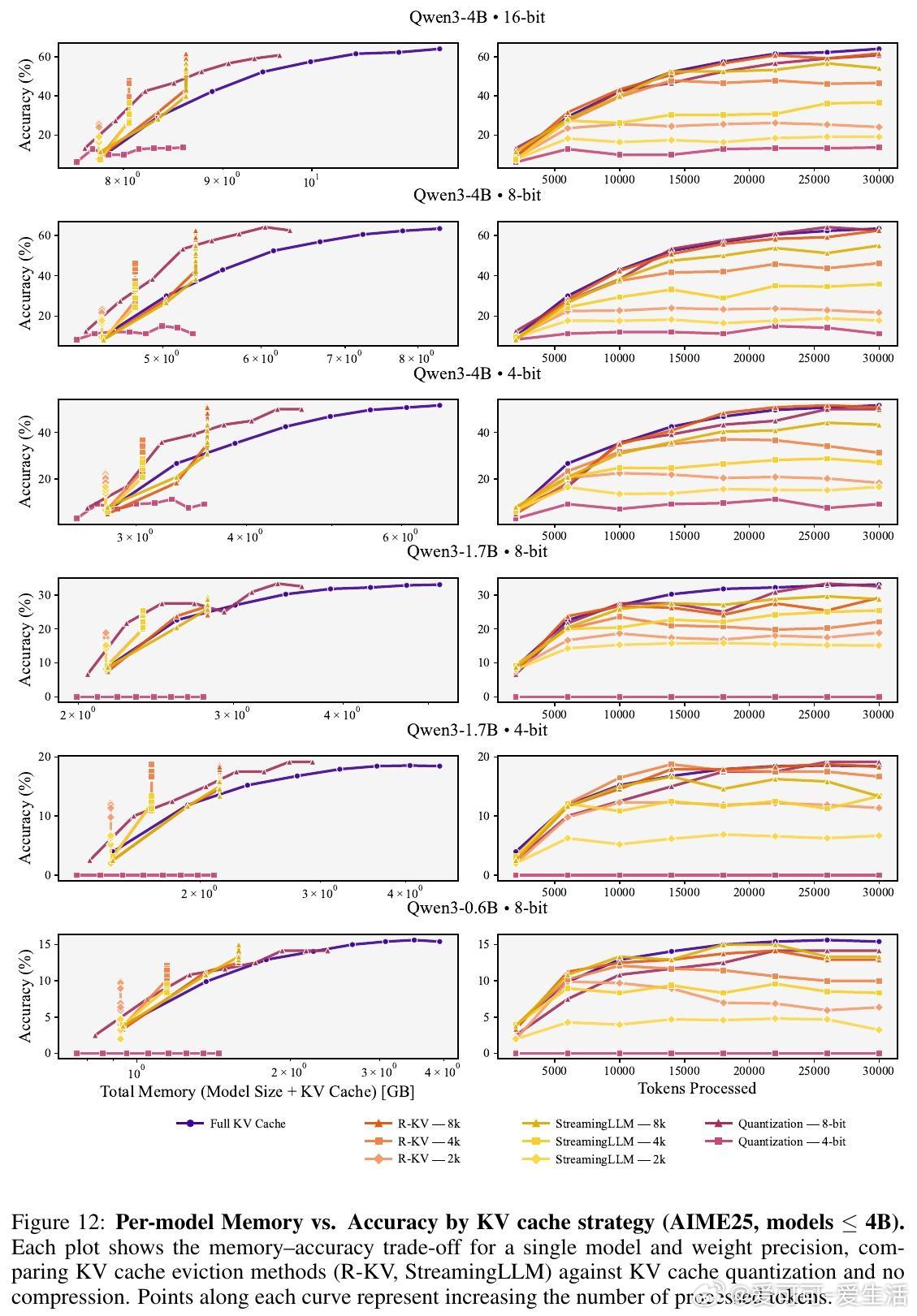
4. 单纯权重量化不足以实现内存最优化,KV缓存压缩(包括缓存驱逐和缓存量化)是关键手段。
5. 小模型更适合采用KV缓存驱逐策略以获得更优权衡;大模型则可采用缓存量化,两者效果相当。
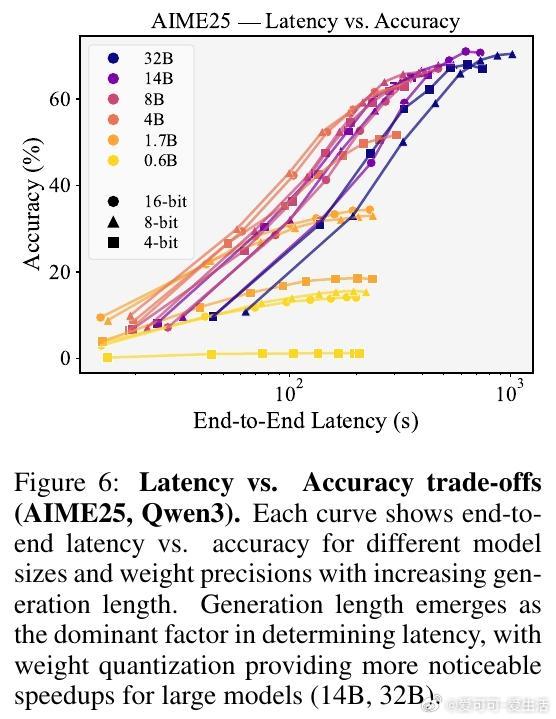
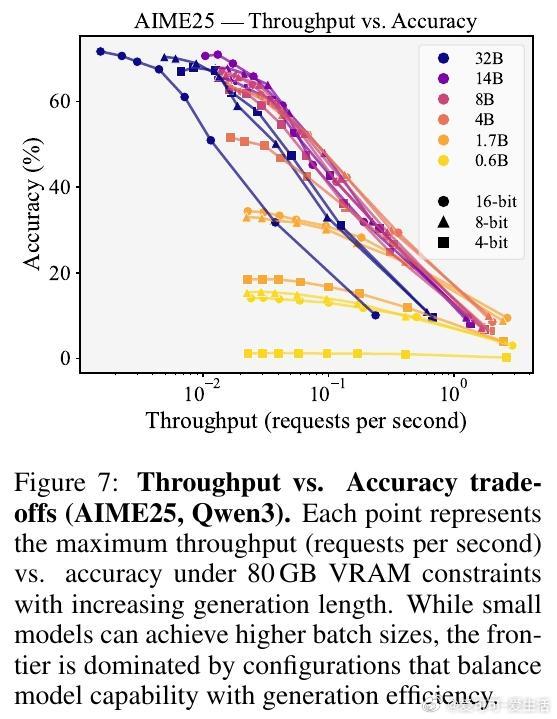
此外,研究还分析了延长生成长度对延迟和吞吐率的影响,发现生成长度是延迟的主要瓶颈,而4-bit权重量化虽节省内存,却不一定带来延迟优势。
实践意义:
- 部署推理模型时,不能一味追求极低位宽,而要结合模型规模和任务类型做出权衡。
- 对小规模模型,应优先保证权重容量和较高精度,辅以KV缓存驱逐。
- 对大规模模型,应优先扩展生成长度和并行采样,结合KV缓存量化。
该研究为推理模型的内存优化提供了系统且细致的指导原则,强调了“尺寸不同,策略不同”的重要性。
全文链接:arxiv.org/abs/2510.10964
欢迎收藏转发,助力推理模型高效部署!