[LG]《The Markovian Thinker》M Aghajohari, K Chitsaz, A Kazemnejad, S Chandar... [Mila] (2025)
提出了一种革新性的“马尔可夫思考”范式,实现了推理长度与上下文大小的解耦,大幅降低计算复杂度。
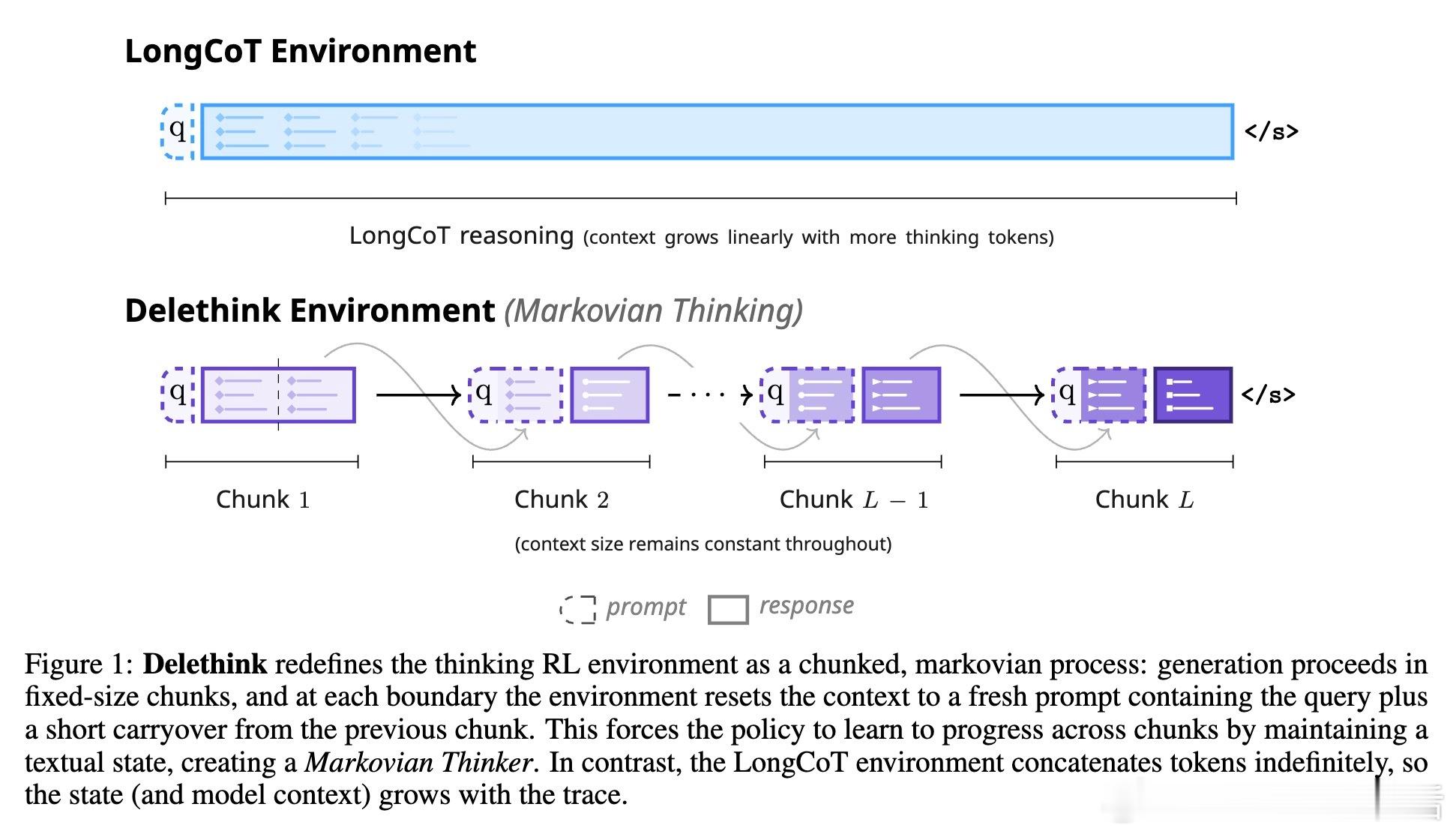
🔹 现有强化学习训练的长链思考(LongCoT)环境中,状态包含了所有历史推理内容,导致计算成本随思考长度呈二次增长,极大限制了可扩展性。
🔹 本文创新定义RL环境:将推理过程划分为固定大小的“块”,在块间重置上下文,只携带必要的“文本状态”传递信息,形成了“Delethink”环境。模型学会写下足够信息,实现连续推理而无需访问全部历史。
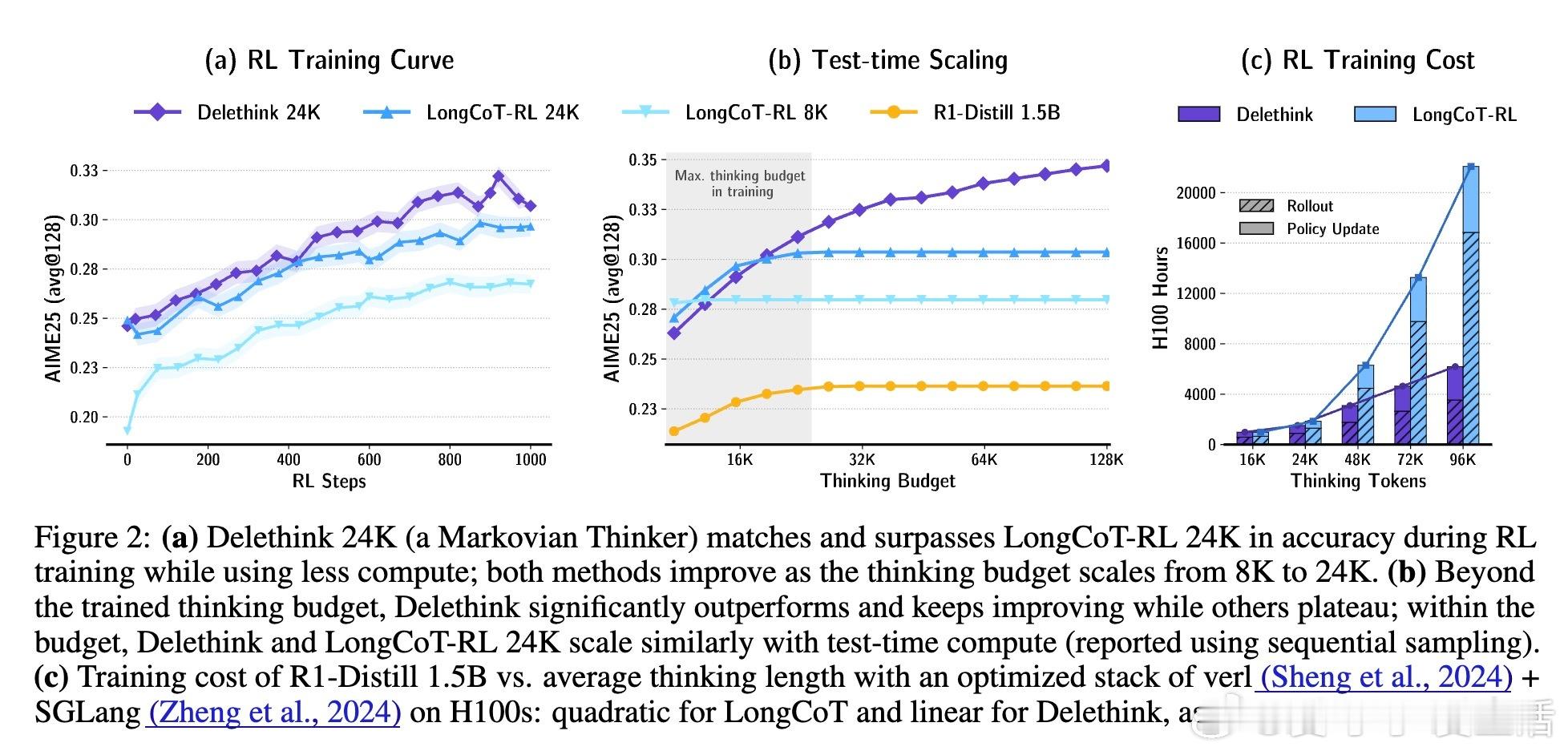
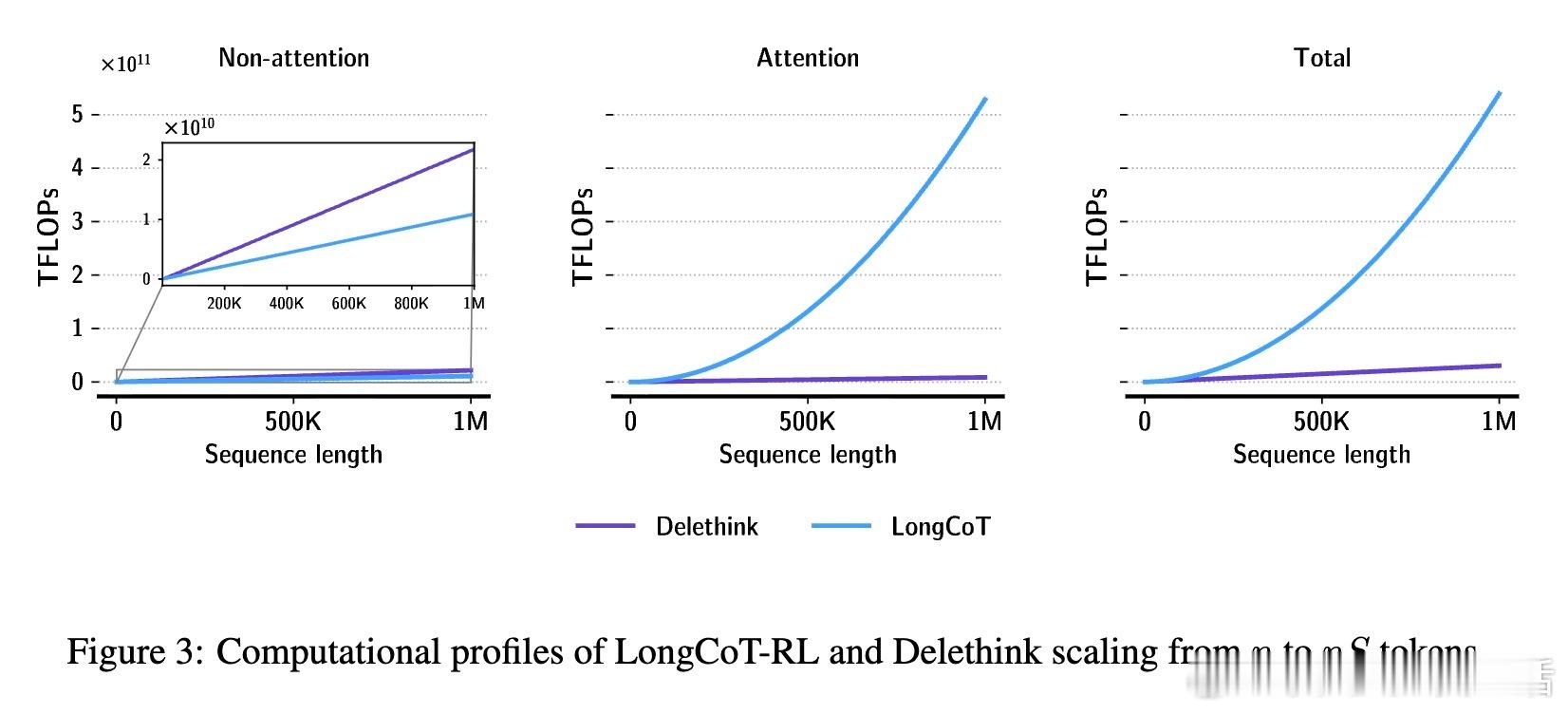
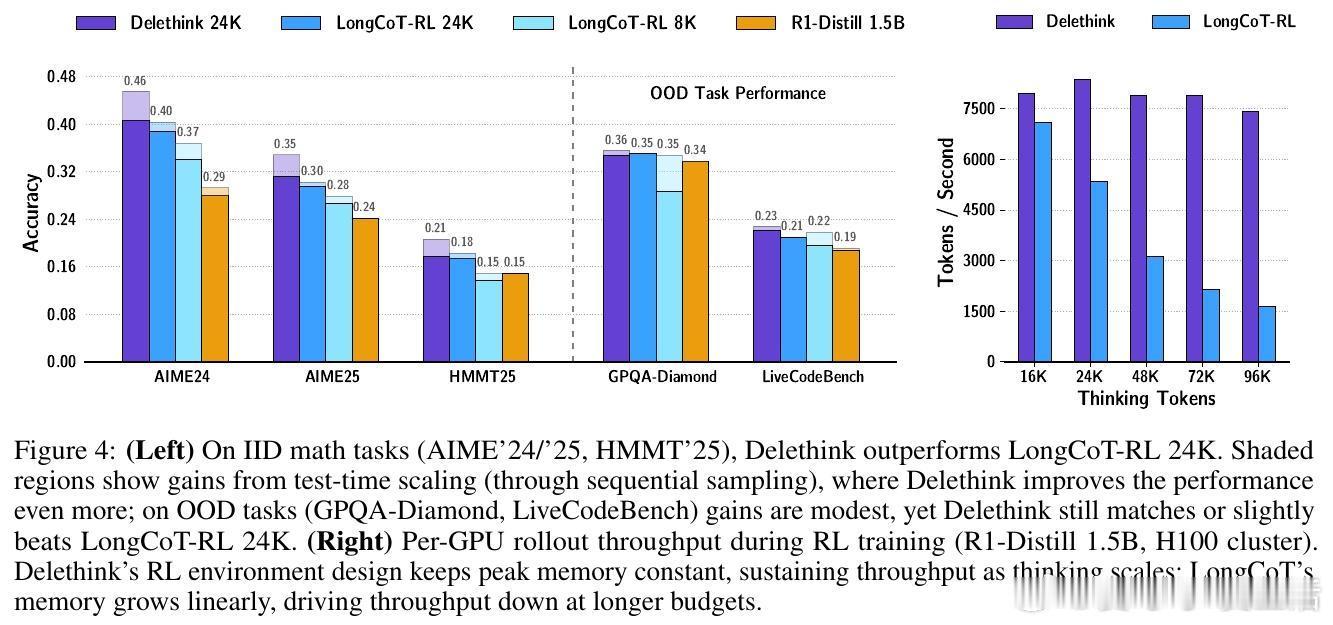
🔹 该方法使得计算和显存需求随思考长度线性增长,极大提升训练与推理效率。例如,推理长度达96K时,传统LongCoT训练耗费27个H100 GPU月,而Delethink仅需7个,节省近4倍计算。
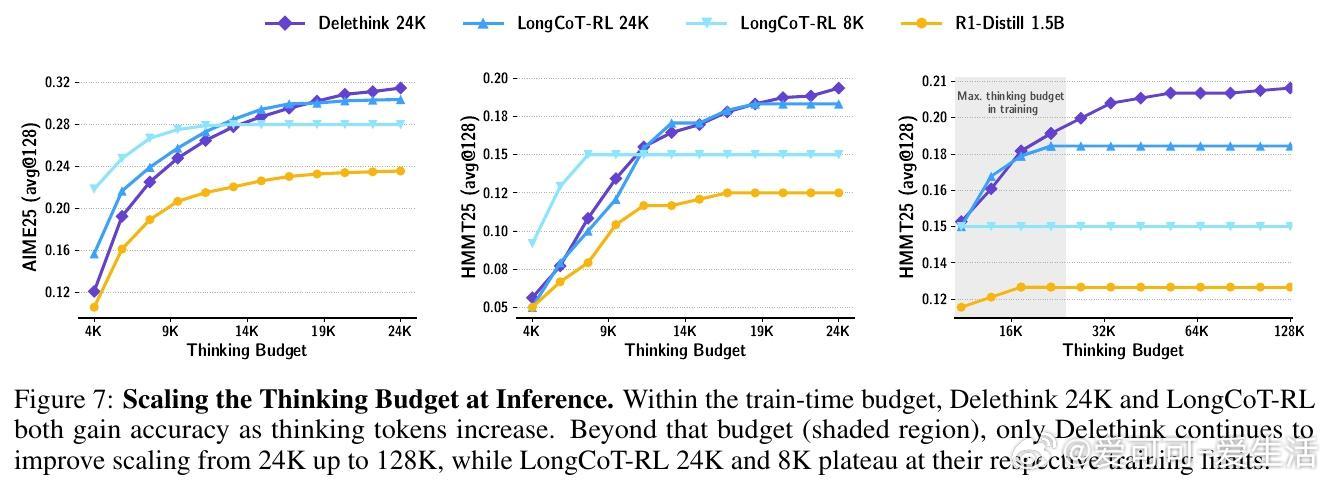
🔹 实验验证:Delethink在数学竞赛任务(AIME、HMMT)上匹配或超越24K LongCoT RL训练效果,且支持远超训练预算的测试时扩展,展现出真正的长程思考能力。
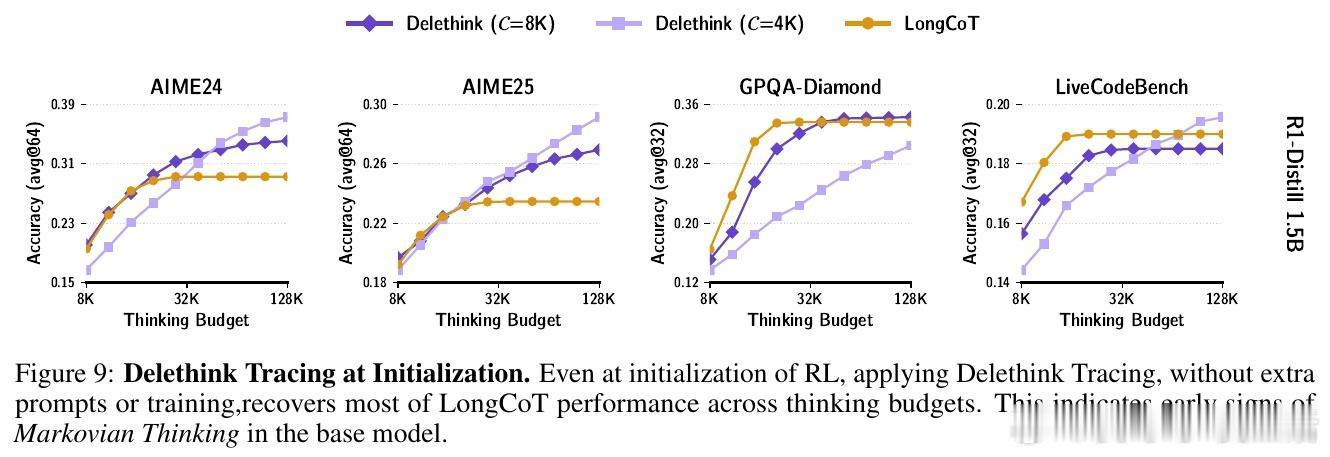
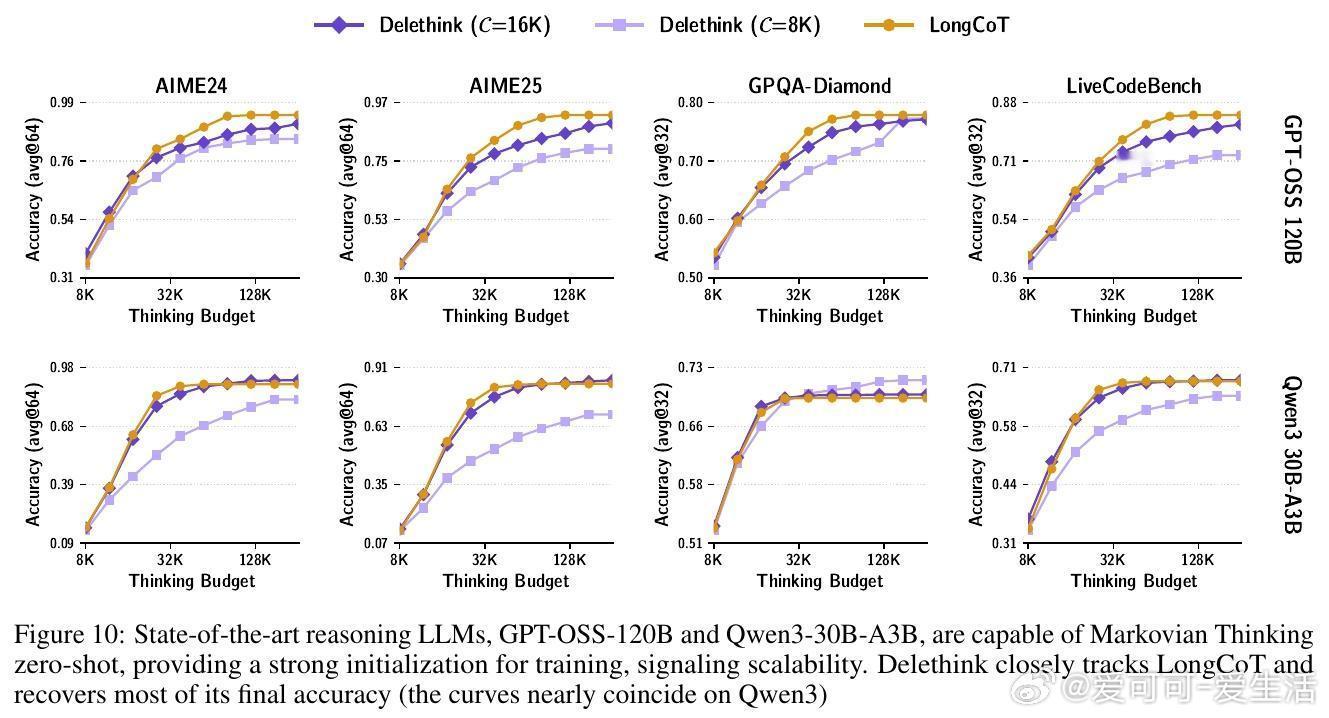
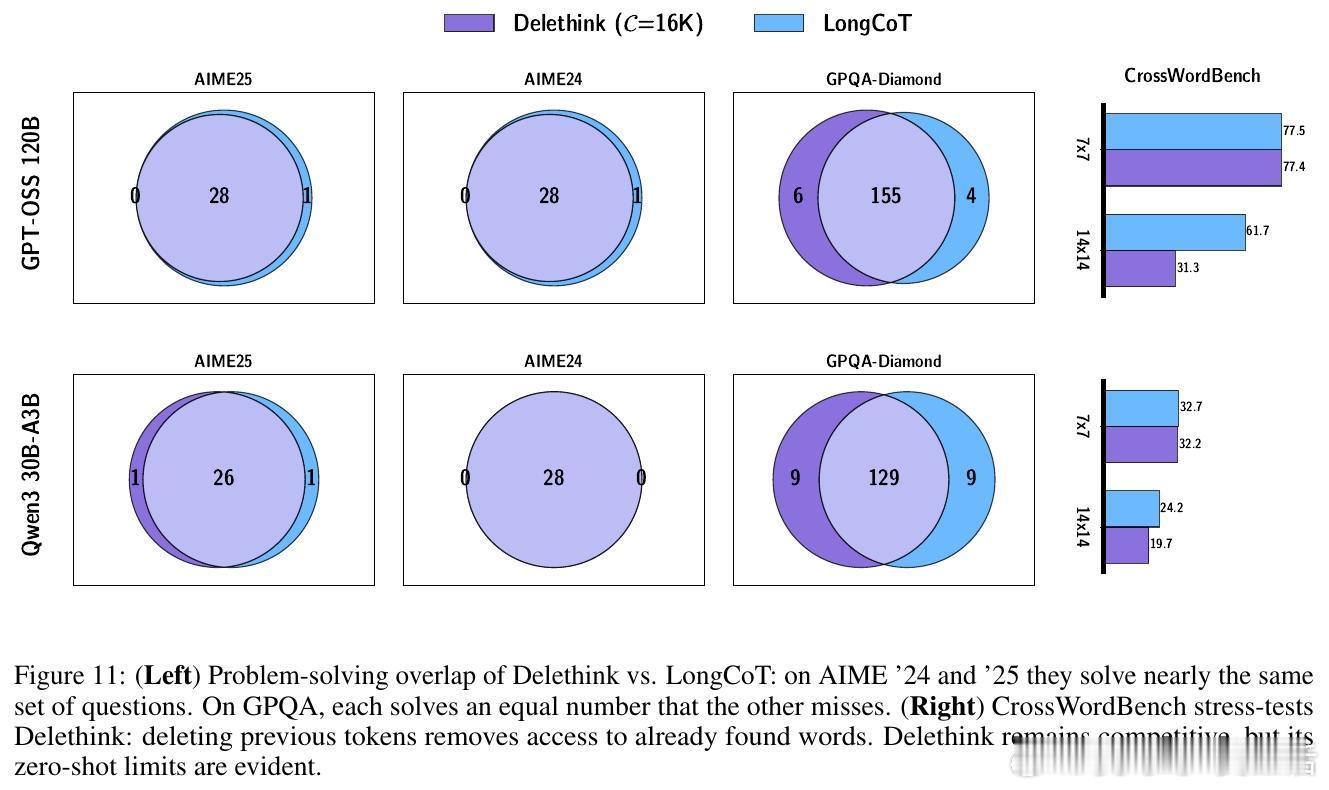
🔹 深入分析显示,主流大模型(1.5B至120B参数)在未训练前即具备零样本马尔可夫思考能力,为Delethink的高效训练奠定基础。
🔹 此范式为设计高效、可扩展的推理大模型开辟新路径,亦与非二次注意力机制架构(滑动窗口、稀疏注意力、状态空间模型等)高度兼容。
全文模型权重与代码开源:
huggingface.co/McGill-NLP/the-markovian-thinker
github.com/McGill-NLP/the-markovian-thinker
【核心贡献总结】
1️⃣ 提出马尔可夫思考范式,状态固定大小,推理长度无限制,计算复杂度由二次降为线性。
2️⃣ 设计Delethink RL环境,训练模型学会写文本状态实现跨块连续推理。
3️⃣ 在多项数学与开放领域任务中达到或超越传统长链思考性能。
4️⃣ 展示强大的测试时扩展能力,实现百万级推理令牌的潜力。
5️⃣ 通过实证和理论分析,揭示其对主流模型训练的适用性与优势。
这项工作不仅突破了长上下文推理的计算瓶颈,更启发我们重新思考大模型推理的环境与架构设计。期待未来基于马尔可夫思考的模型能实现百万级令牌的高效推理,推动AI推理能力迈向新高度。
arxiv.org/abs/2510.06557