DeepSeek突然拥抱国产GPU语言国产TileLang火了开发者直呼优雅
DeepSeek v3.2有一个新改动,在论文里完全没提,只在官方公告中出现一次,却引起墙裂关注。
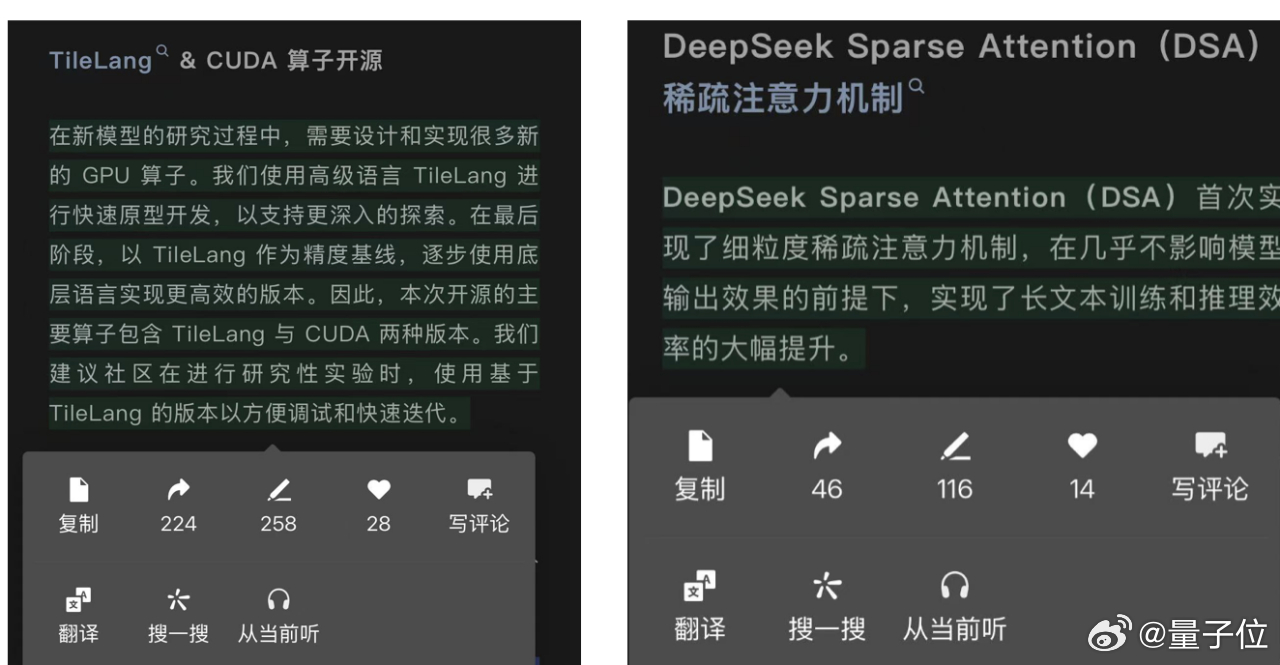
开源TileLang版本算子,其受关注程度甚至超过新稀疏注意力机制DSA,从画线转发的数量就可以看出来。【图1】
海外社区也注意到DeepSeek使用了它而不是OpenAI开发的Triton语言。
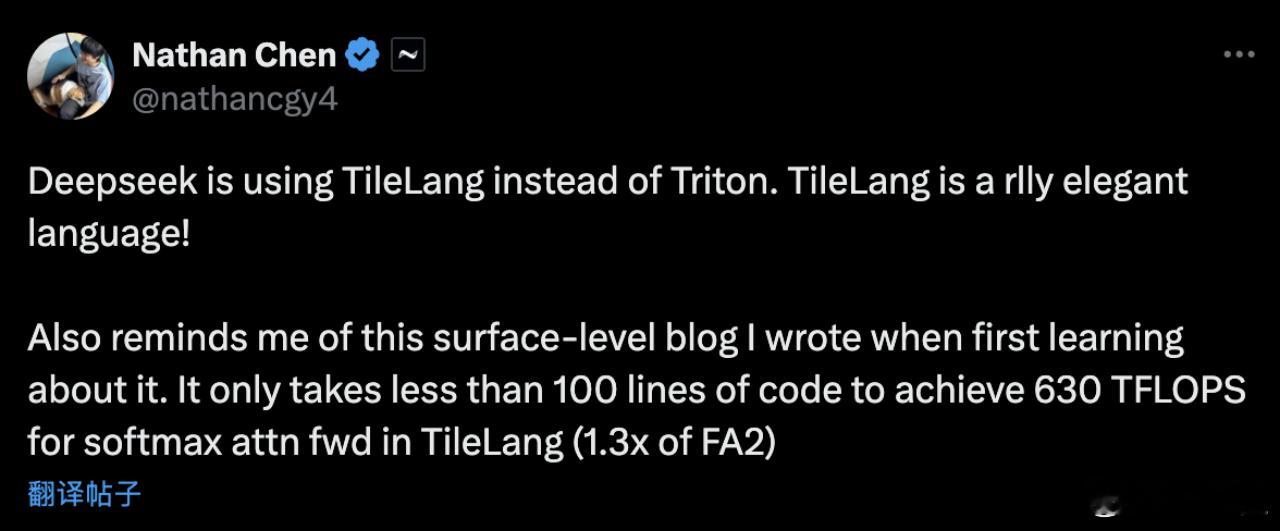
有接触过的开发者感叹TileLang是一种非常优雅的语言,只需不到100行代码就能写出比Flash Attention 2原版快30%的注意力实现。【图2】
那么什么是TileLang,又为何引人瞩目?
首先,TileLang是一种专门用来开发GPU内核的领域专用语言,性能上可以对标英伟达CUDA,DeepSeek官方推荐使用此版本做实验,在方便调试和快速迭代上有优势。
更重要的是,TileLang与国产算力生态适配,连华为昇腾都要在第一时间公告对TileLang的支持。【图3】
在几周前的华为全联接大会2025的开发者日上,TileLang团队成员董宇骐就介绍了TileLang实现FlashAttention算子开发,代码量从500+行减少至80行,并保持了与官方版本持平的性能。
此外TileLang团队成员王磊和沐曦集成电路的高级总监董兆华也在同一个圆桌沙龙上出现过,讨论了沐曦GPU与TileLang的适配。
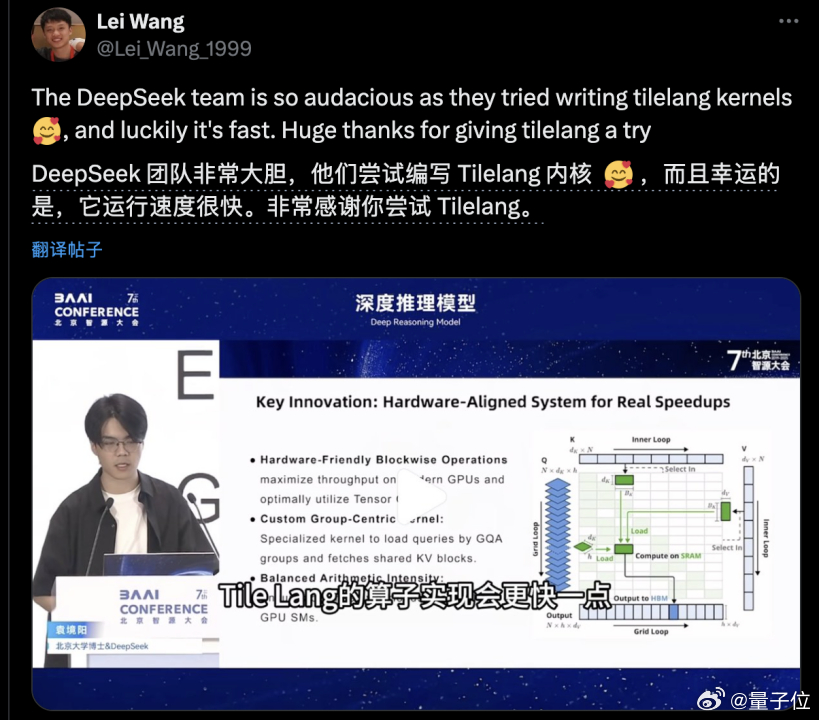
DeepSeek与TileLang第一次同框亮相,其实是在6月的北京智元大会。
在DeepSeek实习过的北大博士袁境阳,在报告中就提到"TileLang的算子实现会更快一点"。
TileLang的发起人之一,北大博士研究生王磊当时还专门发帖感谢DeepSeek尝试他们的语言。【图4】
TileLang由北大团队主导开发,核心人物除了王磊、董宇骐,还有北大计算机学院的副研究员、博士生导师杨智。【图5】
2025年1月,TileLang在GitHub上正式开源,至今已获得1.9k标星。【图6】
简单来说,Tile语言 ( tile-lang ) 是一种简洁的领域专用语言,旨在简化高性能 GPU/CPU 内核的开发。tile-lang采用Python式语法,并在TVM之上构建底层编译器基础架构,使开发者能够专注于提高生产力,而无需牺牲实现最佳性能所需的底层优化。【图7】
王磊曾在7月HyperAI超神经主办的Meet AI Compiler技术沙龙分享TileLang的核心设计理念:
将调度空间(包括线程绑定、内存布局、张量化和流水线等)与数据流解耦,并将其封装为一组可自定义的注解和原语。这种方法允许用户专注于内核的数据流本身,而将大部分优化工作交给编译器完成。
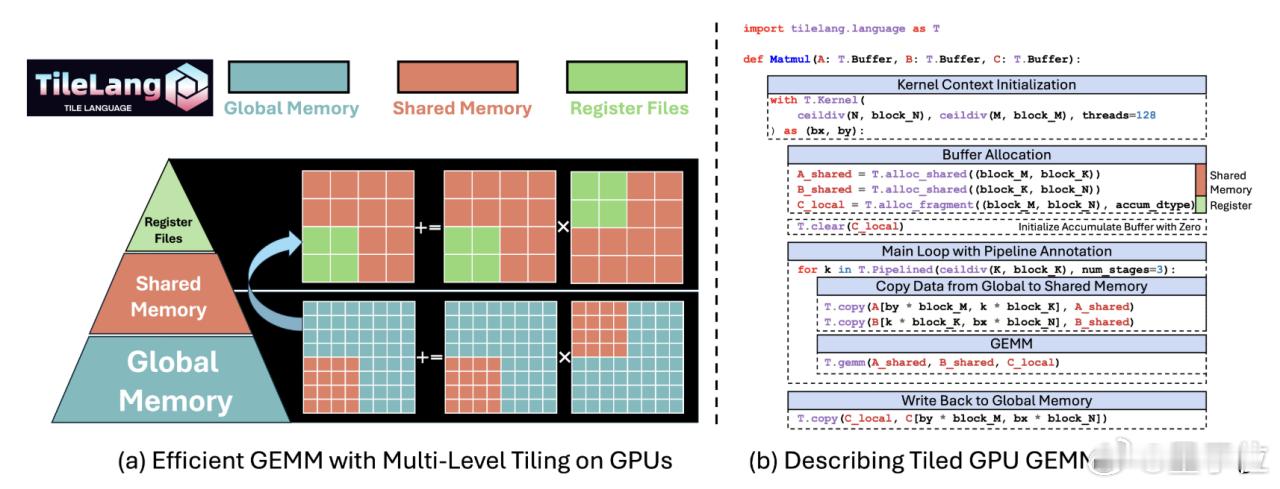
TileLang将"Tile"作为编程模型的核心概念,通过显式的Tile抽象,让开发者能够直观地控制数据在全局内存、共享内存和寄存器之间的流动。
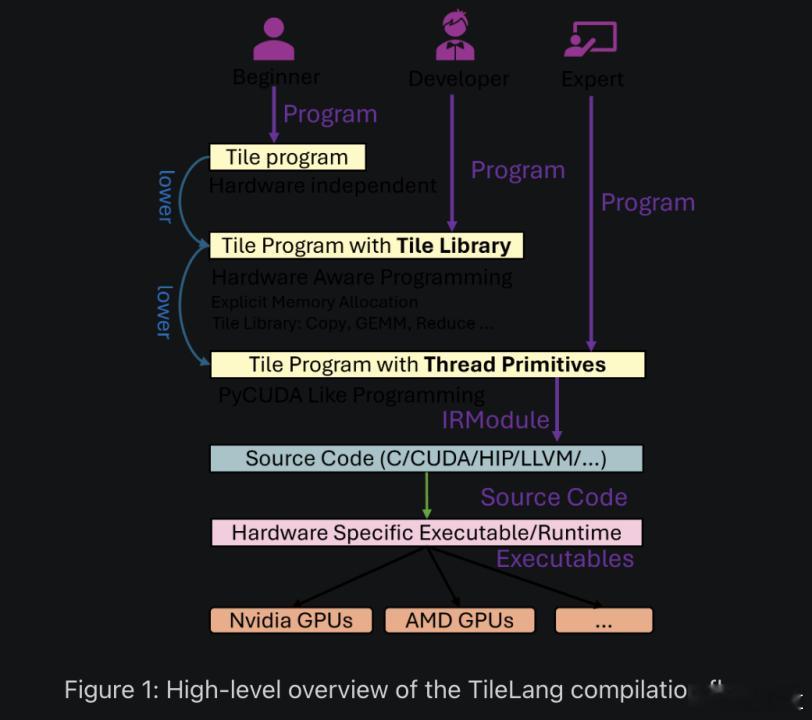
TileLang提供了三个不同层次的编程接口,满足不同水平开发者的需求。
初学者可以使用硬件无关的高层接口,专注于算法逻辑而不必关心底层细节。
有经验的开发者可以使用ile Library,这里包含了各种针对不同硬件架构优化过的预定义操作。
对于追求极致性能的专家用户,TileLang还提供了线程原语级别的控制,允许他们直接操作线程同步、内存合并等底层特性。【图8】
DeepSeek显然就属于追求极致性能的专家用户了,根据v3.2公告的说法,在早期DeepSeek团队使用TileLang快速开发原型,之后用更底层的方法进一步优化性能。
v3.2论文中提到在内核层面共享k-v提升计算效率,让DSA的闪电索引器机制(lightning indexer)运行速度远超传统实现。【图9】
在TileLang的文档中也有相关的技术介绍,在计算过程中缓存中间数据,比全局内存快得多。【图10】
更早之前,在DeepSeek连续一周发布开源代码库的第一天,王磊就曾向DeepSeek团队推荐TileLang语言。【图11】
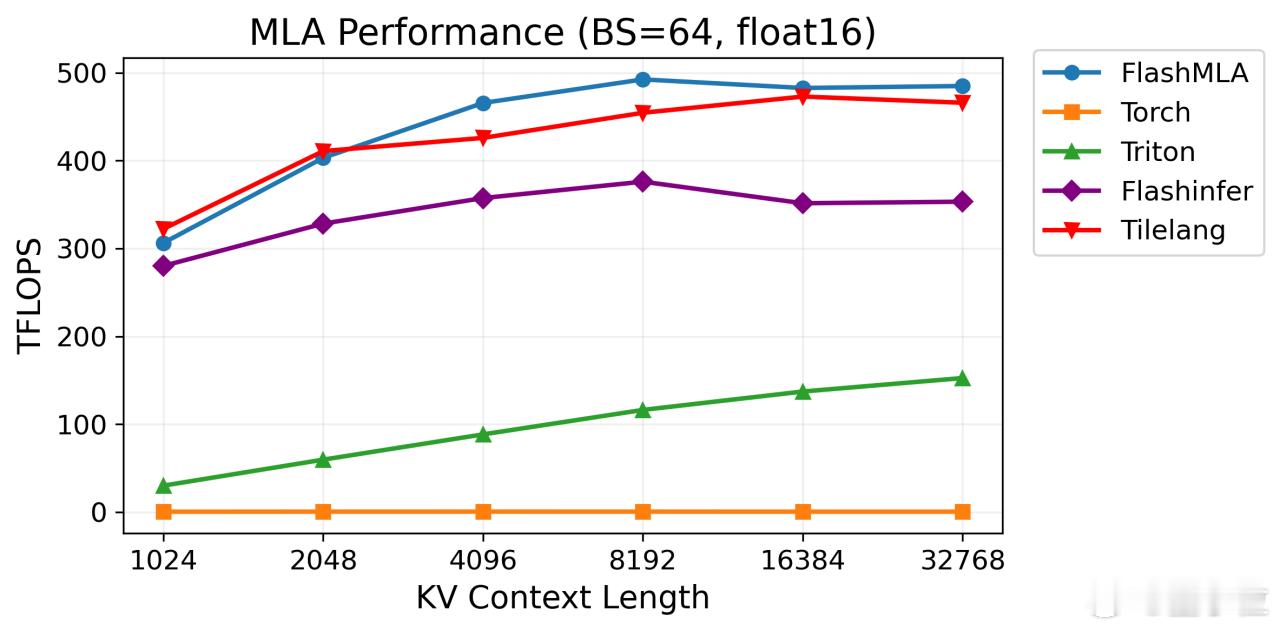
后来TileLang也以DeepSeek在这天发布的FlashMLA内核作为评测基准,在H100上的MLA解码速度,TileLang编写的内核做到与FlashMLA相当。【图12】
在最新的DeepSeek v3.2发布之后,王磊也发帖致敬DeepSeek敢于使用一门新的编程语言来开发核心产品。
并且DeepSeek v3.2也验证了TileLang确实可以用来训练模型。【图13】
DeepSeek V3.2技术报告:
TileLang: