[LG]《Depth-Breadth Synergy in RLVR: Unlocking LLM Reasoning Gains with Adaptive Exploration》Z Yang, Z Guo, Y Huang, Y Wang... [The Hong Kong University of Science and Technology (Guangzhou) & ETH Zurich] (2025)
RLVR训练中“深度-广度”双维度优化揭示LLM推理能力提升新路径:
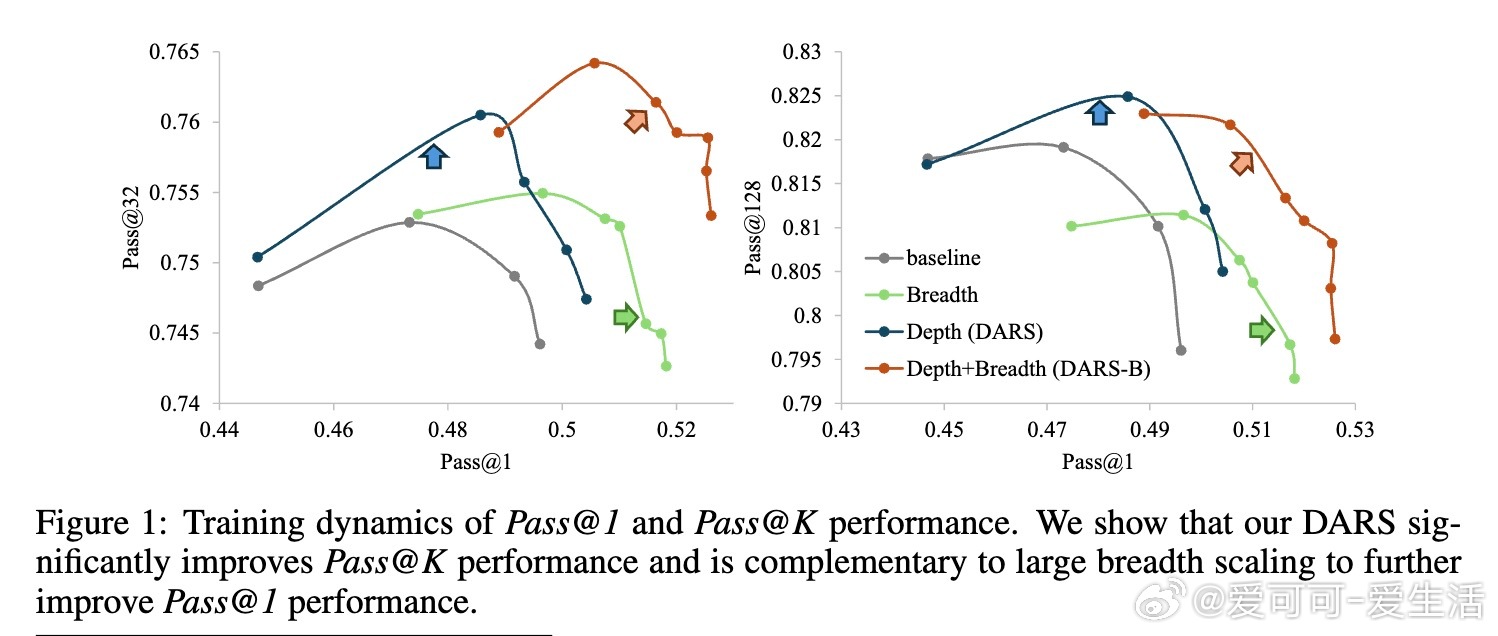
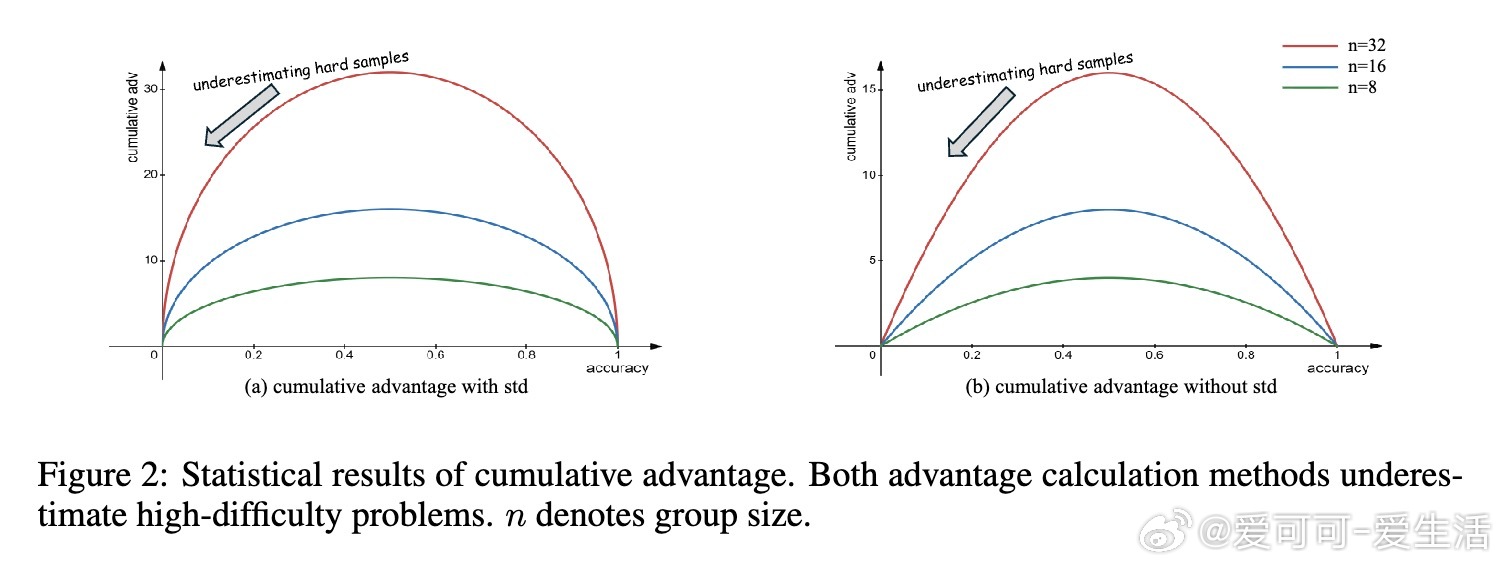
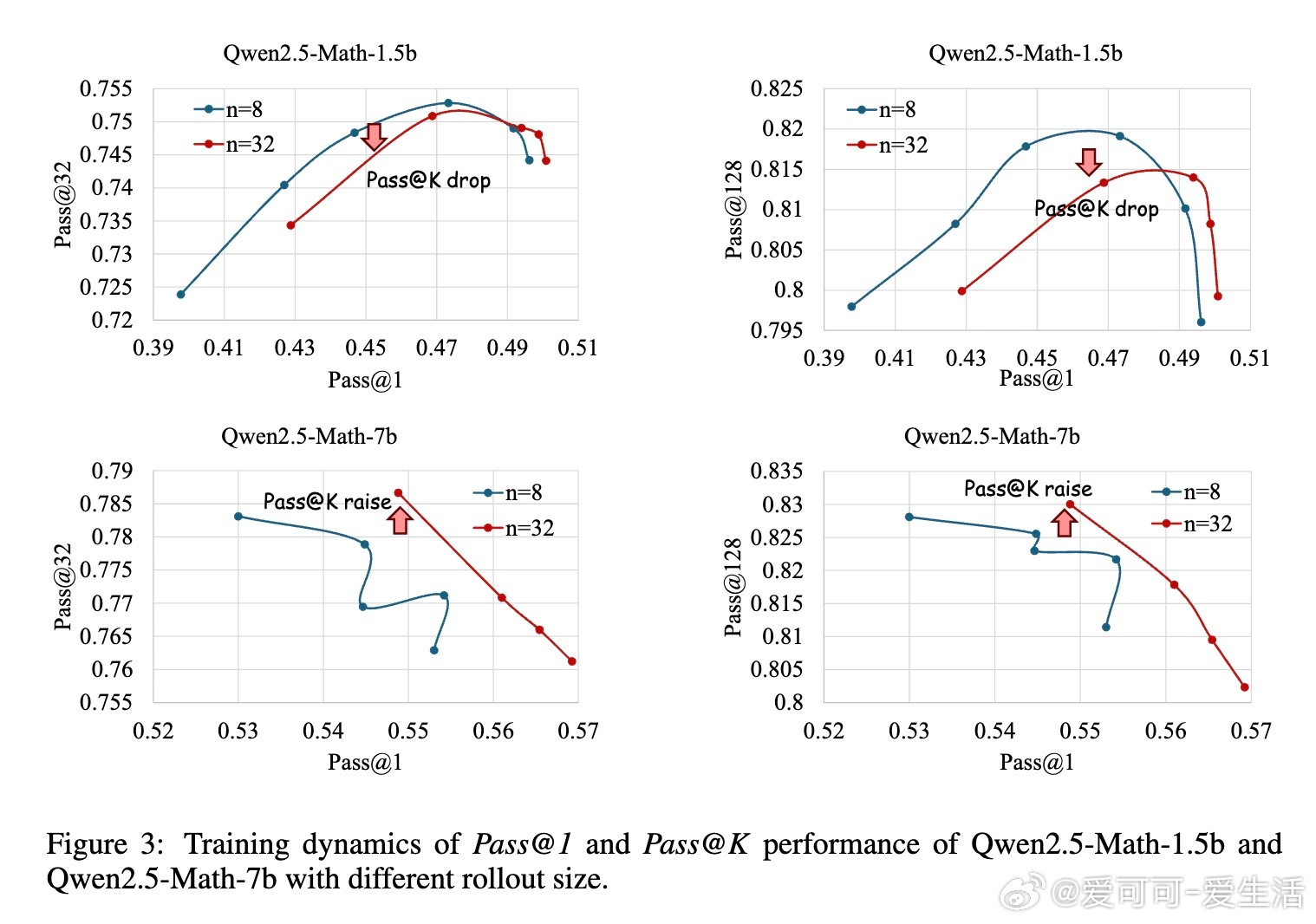
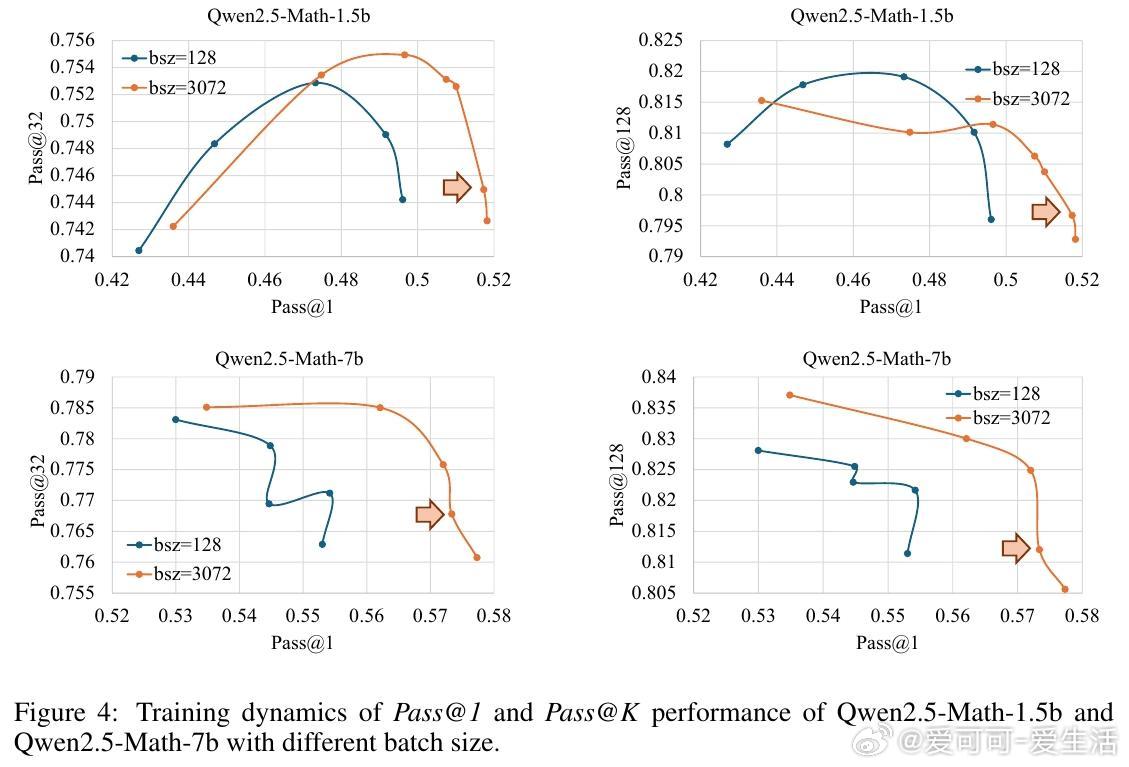
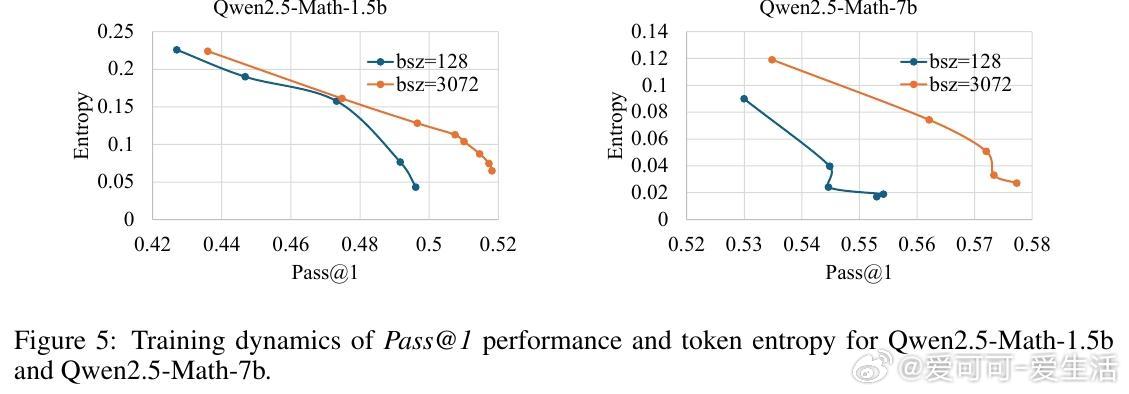
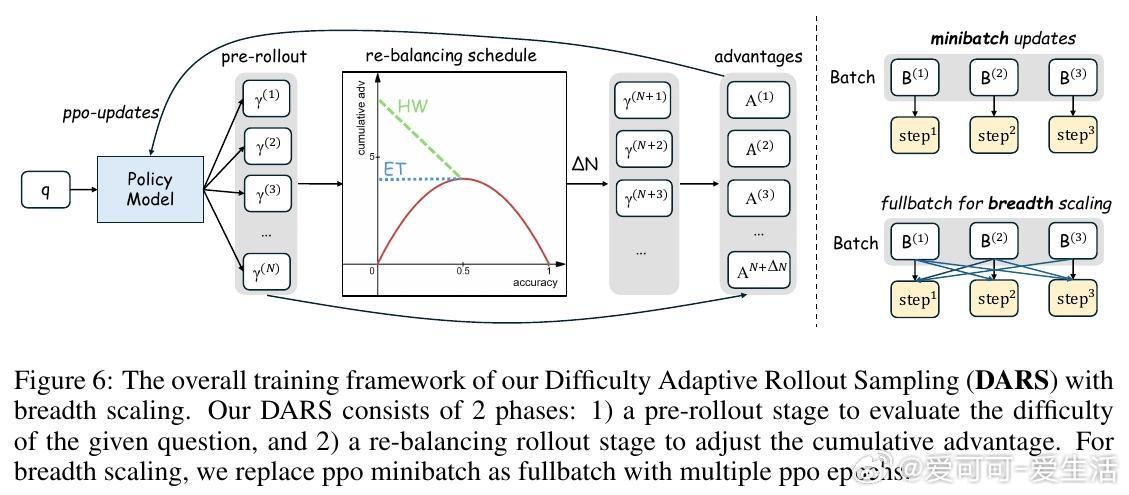
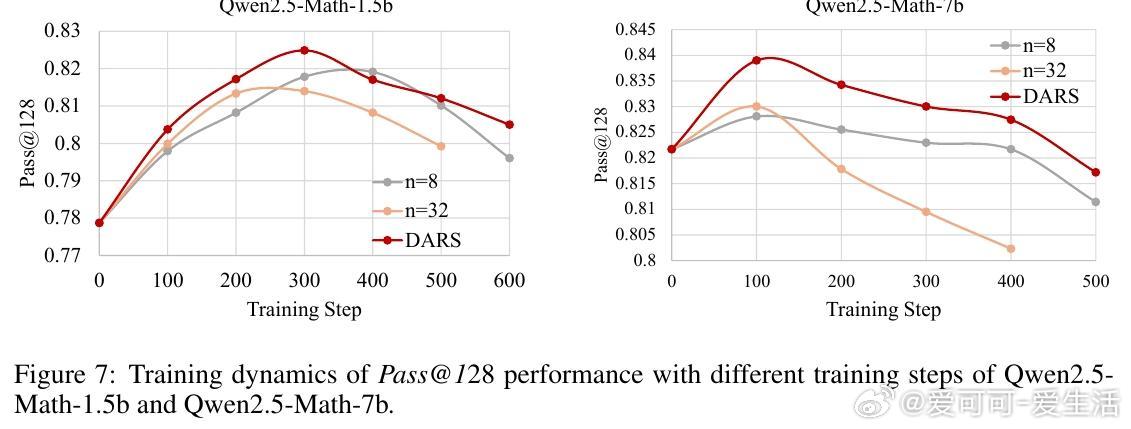
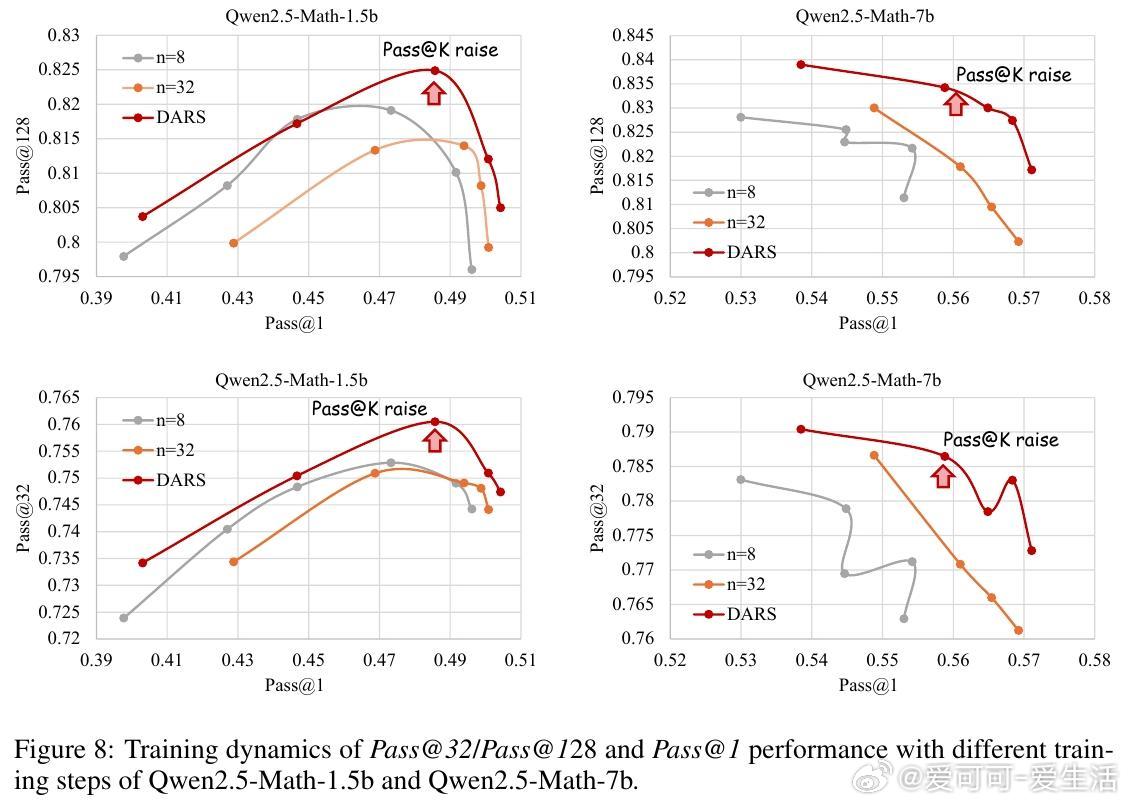
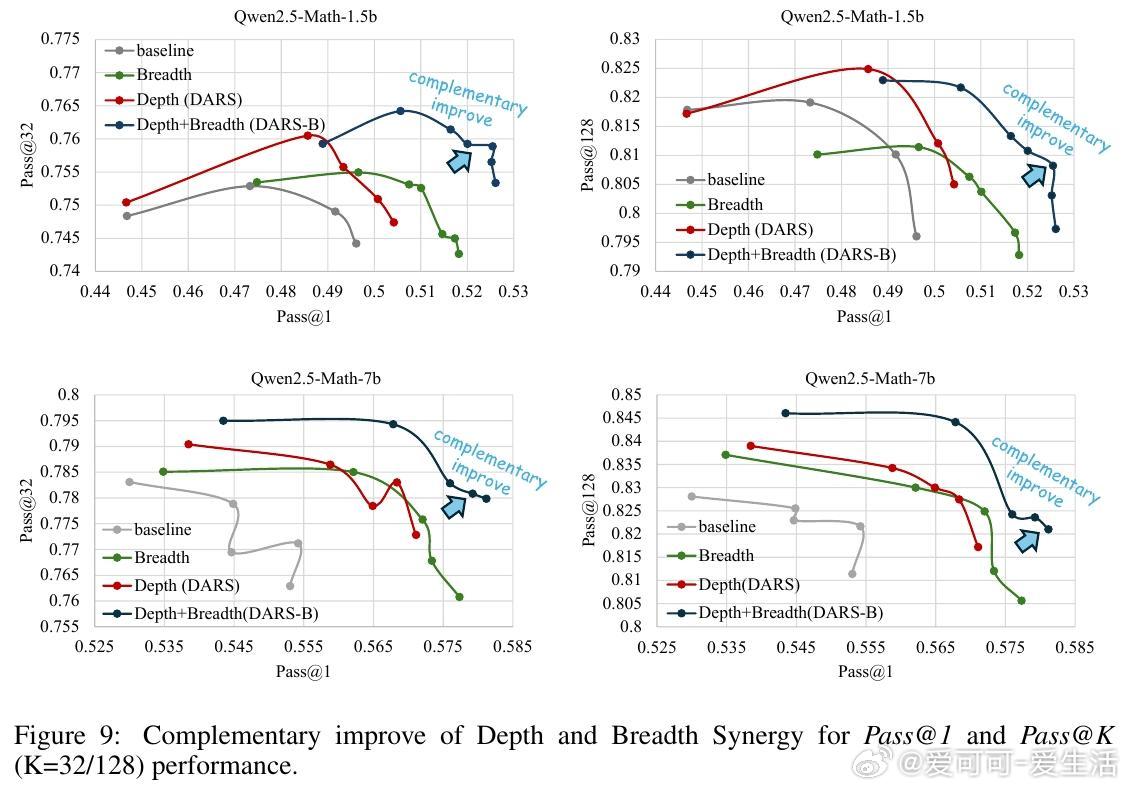
• 深度(Depth)指模型能正确解决的最难问题。现有GRPO算法的累计优势计算偏向中等难度样本,忽视高难度样本,限制Pass• 广度(Breadth)指单次迭代中训练样本数量。大幅增加训练批量规模,采用全批次多轮PPO更新,显著提升Pass• 提出Difficulty Adaptive Rollout Sampling(DARS),通过两阶段多轮采样动态分配计算资源,重点加强对难题的采样,纠正累计优势偏差,显著提升Pass• 结合DARS与大广度训练的DARS-B方案,实现Pass• 实验覆盖五大数学推理基准,采用Qwen2.5-Math系列模型,显示DARS-B领先传统GRPO及单维度扩展方案,强化了LLM推理性能和训练稳定性。
该研究为利用RLVR激发LLM复杂推理能力提供了系统性框架与实证指导,强调针对难题的适应性采样和大批量训练策略的协同作用,为未来RLVR优化和大规模智能模型训练奠定基础。
详情见👉 arxiv.org/abs/2508.13755
强化学习大语言模型推理能力机器学习人工智能